當MongoDB遇見Spark
《當MongoDB遇見Spark》要點:
本文介紹了當MongoDB遇見Spark,希望對您有用。如果有疑問,可以聯系我們。
相關主題:非關系型數據庫
適宜讀者人群
正在使用Mongodb的開發者
傳統Spark生態系統 和 MongoDB在Spark生態的角色
傳統Spark生態系統
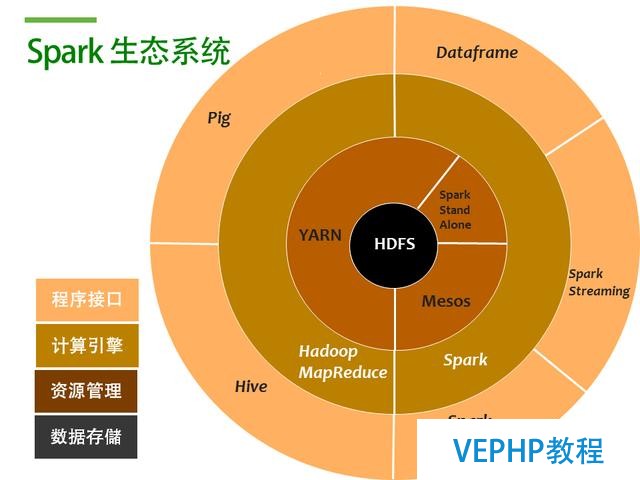
Spark生態系統
那么Mongodb作為一個database, 可以擔任什么樣的角色呢? 就是數據存儲這部分, 也就是圖中的黑色圈圈HDFS的部分, 如下圖
用MongoDB替換HDFS后的Spark生態系統
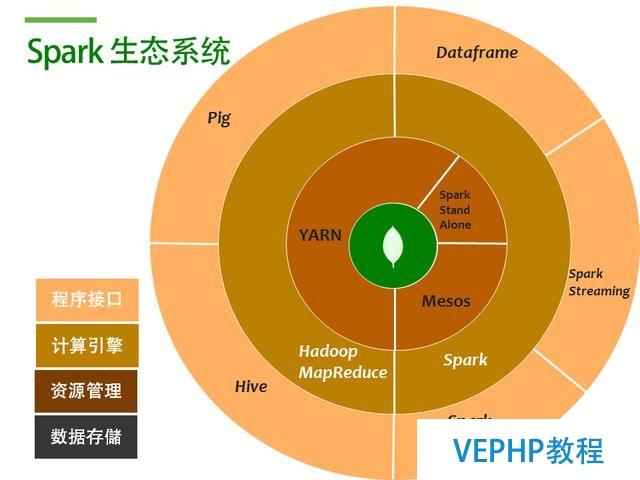
Spark+Mongodb生態系統
為什么要用MongoDB替換HDFS
存儲方式上, HDFS以文件為單位,每個文件64MB~128MB不等, 而MongoDB作為文檔數據庫則表現得更加細顆粒化
MongoDB支持HDFS所沒有的索引的概念, 所以在讀取上更加快
MongoDB支持的增刪改功能比HDFS更加易于修改寫入后的數據
HDFS的響應級別為分鐘, 而MongoDB通常是毫秒級別
如果現有數據庫已經是MongoDB的話, 那就不用再轉存一份到HDFS上了
可以利用MongoDB強大的Aggregate做數據的篩選或預處理
MongoDB Spark Connector介紹
支持讀取和寫入,即可以將計算后的結果寫入MongoDB
將查詢拆分為n個子任務, 如Connector會將一次match,拆分為多個子任務交給spark來處理, 減少數據的全量讀取
MongoDB Spark 示例代碼
計算用類型Type=1的message字符數并按userid進行分組
開發Maven dependency配置
這里用的是mongo-spark-connector_2.11 的2.0.0版本和spark的spark-core_2.11的2.0.2版本
<dependency>
示例代碼
import com.mongodb.spark._ import org.apache.spark.{SparkConf, SparkContext} import org.bson._ val conf = new SparkConf()維易PHP培訓學院每天發布《當MongoDB遇見Spark》等實戰技能,PHP、MYSQL、LINUX、APP、JS,CSS全面培養人才。
