Mysql必讀MySQL中Stmt 預處理提高效率問題的小研究
作者:VEPHP 時間 2017-10-23
《Mysql必讀MySQL中Stmt 預處理提高效率問題的小研究》要點:
本文介紹了Mysql必讀MySQL中Stmt 預處理提高效率問題的小研究,希望對您有用。如果有疑問,可以聯系我們。
代碼如下:
DELIMITER $$
set @stmt = 'select userid,username from myuser where userid between ? and ?';
prepare s1 from @stmt;
set @s1 = 2;
set @s2 = 100;
execute s1 using @s1,@s2;
deallocate prepare s1;
$$
DELIMITER ;
用這種形式寫的查詢,可以隨意替換參數,給出代碼的人稱之為預處理,我想這個應該就是MySQL中的變量綁定吧……但是,在查資料的過程中我卻聽到了兩種聲音,一種是,MySQL中有類似Oracle變量綁定的寫法,但沒有其實際作用,也就是只能方便編寫,不能提高效率,這種說法在幾個09年的帖子中看到:
http://www.itpub.net/thread-1210292-1-1.html
http://cuda.itpub.net/redirect.php?fid=73&tid=1210572&goto=nextnewset
另一種說法是MySQL中的變量綁定是能確實提高效率的,這個是希望有的,那到底有木有,還是自己去試驗下吧.
試驗是在本機進行的,數據量比較小,具體數字并不具有實際意義,但是,能用來說明一些問題,數據庫版本是mysql-5.1.57-win32免安裝版.
本著對數據庫不是很熟悉的態度^_^,試驗過程中走了不少彎路,此文以結論為主,就不列出實驗的設計過程,文筆不好,文章寫得有點枯燥,寫出來是希望有人來拍磚,因為我得出的結論是:預處理在有沒有cache的情況下的執行效率都不及直接執行…… 我對自己的實驗結果不愿接受..如果說預處理只為了規范下Query,使cache命中率提高的話個人覺得大材小用了,希望有比較了解的人能指出事實究竟是什么樣子的――NewSilen
實驗準備
第一個文件NormalQuery.sql
代碼如下:
Set profiling=1;
Select * From MyTable where DictID = 100601000004;
Select DictID from MyTable limit 1,100;
Select DictID from MyTable limit 2,100;
/*從limit 1,100 到limit 100,100 此處省略重復代碼*/
......
Select DictID from MyTable limit 100,100;
SELECT query_id,seq,STATE,10000*DURATION FROM information_schema.profiling INTO OUTFILE 'd:/NormalResults.csv' FIELDS TERMINATED BY ',' LINES TERMINATED BY '\n';
第二個sql文件 StmtQuery.sql
代碼如下:
Set profiling=1;
Select * From MyTable where DictID = 100601000004;
set @stmt = 'Select DictID from MyTable limit ?,?';
prepare s1 from @stmt;
set @s = 100;
set @s1 = 101;
set @s2 = 102;
......
set @s100 =200;
execute s1 using @s1,@s;
execute s1 using @s2,@s;
......
execute s1 using @s100,@s;
SELECT query_id,seq,STATE,10000*DURATION FROM information_schema.profiling INTO OUTFILE 'd:/StmtResults.csv' FIELDS TERMINATED BY ',' LINES TERMINATED BY '\n';
做幾點小說明:
1. Set profiling=1; 執行此語句之后,可以從information_schema.profiling這張表中讀出語句執行的詳細信息,其實包含不少內容,包括我需要的時間信息,這是張臨時表,每新開一個會話都要重新設置profiling屬性才能從這張表中讀取數據
2. Select * From MyTable where DictID = 100601000004;
這行代碼貌似和我們的實驗沒什么關系,本來我也是這么認為的,之所以加這句,是我在之前的摸索中發現,執行過程中有個步驟是open table,如果是第一次打開某張表,那時間是相當長的,所以在執行后面的語句前,我先執行了這行代碼打開試驗用的表
3. MySQL默認在information_schema.profiling表中保存的查詢歷史是15條,可以修改profiling_history_size屬性來進行調整,我希望他大一些讓我能一次取出足夠的數據,不過最大值只有100,盡管我調整為150,最后能夠查到的也只有100條,不過也夠了
4. SQL代碼我沒有全列出來,因為查詢語句差不多,上面代碼中用省略號表示了,最后的結果是兩個csv文件,個人習慣,你也可以把結果存到數據庫進行分析
實驗步驟
重啟數據庫,執行文件NormalQuery.sql,執行文件StmtQuery.sql,得到兩個結果文件
再重啟數據庫,執行StmtQuery.sql,執行文件NormalQuery.sql,得到另外兩個結果文件
實驗結果
詳細結果在最后提供了附件下載,有興趣的朋友可以看下
結果分析
每一個SQL文件中執行了一百個查詢語句,沒有重復的查詢語句,不存在查詢cache,統計執行SQL的平均時間得出如下結果
MYSQL實例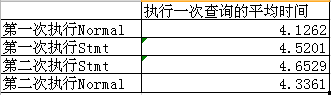
MYSQL實例從結果中可以看出,無論是先執行還是后執行,NormalQuery中的語句都比使用預處理語句的要快一些=.=!
MYSQL實例那再來看看每一句查詢具體的情況,Normal和Stmt的query各執行了兩百次,每一步的詳細信息如下:
MYSQL實例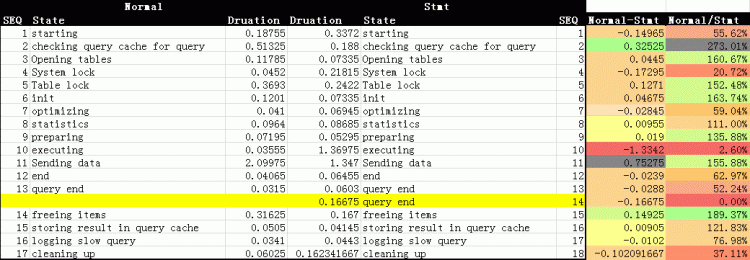
MYSQL實例從這里面可以看出,第一個,normalquery比stmtquery少一個步驟,第二個,雖然stmt在不少步驟上是優于normal的,但在executing一步上輸掉太多,最后結果上也是落敗
MYSQL實例?最后,再給出一個查詢緩存的實驗結果,具體步驟就不列了
MYSQL實例
MYSQL實例在查詢緩存的時候,Normal完勝……
MYSQL實例寫在最后
MYSQL實例大概情況就是這樣,我回憶了一下,網上說預處理可以提高效率的,基本都是用編程的方式去執行查詢,不知道這個有沒有關系,基礎有限,希望園子里的大牛能看到,協助解惑
實驗結果附件
MySQL預處理實驗結果
維易PHP培訓學院每天發布《Mysql必讀MySQL中Stmt 預處理提高效率問題的小研究》等實戰技能,PHP、MYSQL、LINUX、APP、JS,CSS全面培養人才。
同類教程排行
- Mysql實例mysql報錯:Deadl
- MYSQL數據庫mysql導入sql文件
- MYSQL的UTF8MB4編碼排序要用u
- MYSQL教程mysql自定義split
- 如何打造MySQL高可用平臺
- MYSQL創建表出錯Tablespace
- Mysql必讀MySQL中CLIENT_
- MYSQL數據庫mysql常用字典表(完
- Mysql應用MySql的Communi
- Mysql入門解決MySQL Sendi
- Mysql必讀關于skip_name_r
- MYSQL數據庫MySQL實現兩張表數據
- Mysql實例使用dreamhost空間
- MYSQL數據庫mysql 查詢表中平均
- MYSQL教程mysql 跨表查詢、更新
