Node.js的線程和進程詳解
《Node.js的線程和進程詳解》要點:
本文介紹了Node.js的線程和進程詳解,希望對您有用。如果有疑問,可以聯系我們。
相關主題:node.js web開發
很多Node.js初學者都會有這樣的疑惑,Node.js到底是單線程的還是多線程的?本文解釋了Node.js對于單/多線程的關系和支持情況。同時本文還將列舉一些讓Node.js的web服務器線程阻塞的例子,最后會提供Node.js碰到這類cpu密集型問題的解決方案。
閱讀本文前,你需要對Node.js有一個初步的認識,熟悉Node.js基本語法、cluster模塊、child_process模塊和express框架;接觸過apache的http壓力測試工具ab;了解一般web服務器對于靜態文件的處理流程。
Node.js和PHP
早期有很多關于Node.js爭論的焦點都在它的單線程模型方面,在由Jani Hartikainen寫的一篇著名的文章《PHP優于Node.js的五大理由》中,更有一條矛頭直接指向Node.js單線程脆弱的問題。
如果PHP代碼損壞,不會拖垮整個服務器。
PHP代碼只運行在自己的進程范圍中,當某個請求顯示錯誤時,它只對特定的請求產生影響。而在Node.js環境中,所有的請求均在單一的進程服務中,當某個請求導致未知錯誤時,整個服務器都會受到影響。
Node.js和Apache+PHP還有一個非常不同的地方就是進程的運行時間長短,當然這一點也被此文作為一個PHP優于Node.js的理由來寫了。
PHP進程短暫。
在PHP中,每個進程對請求持續的時間很短暫,這就意味著你不必為資源配置和內存而擔憂。而Node.js的進程需要運行很長一段時間,你需要小心并妥善管理好內存。比如,如果你忘記從全局數據中刪除條目,這會輕易的導致內存泄露。
在這里我們并不想引起一次關于PHP和Node.js孰優孰劣的口水仗,PHP和Node.js各代表著一個互聯網時代的開發語言,就如同我們討論跑車和越野車誰更好一樣,它們都有自己所擅長和適用的場景。
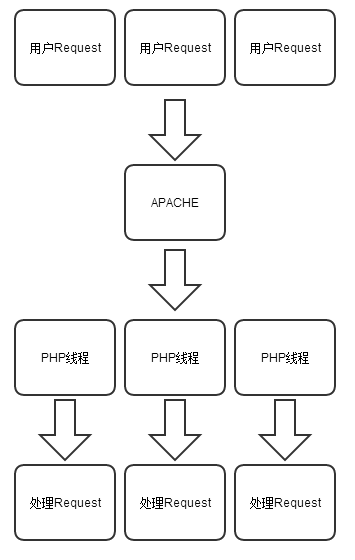
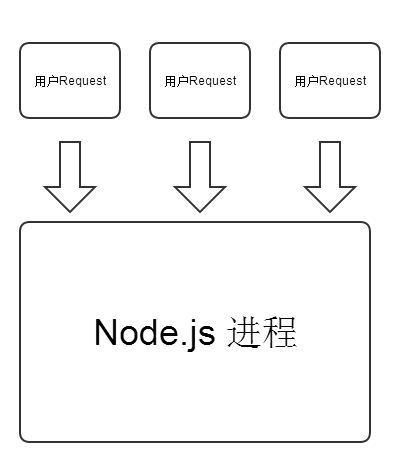
我們可以通過下面這兩張圖深入理解一下PHP和Node.js對處理Http請求時的區別。
PHP的模型:
Node.js的模型:
所以你在編寫Node.js代碼時,要保持清醒的頭腦,任何一個隱藏著的異常被觸發后,都會將整個Node.js進程擊潰。但是這樣的特性也為我們編寫代碼帶來便利,比如同樣要實現一個簡單的網站訪問次數統計,Node.js只需要在內存里定義一個變量var count=0;,每次有用戶請求過來執行count++;即可。
var http = require('http'); var count = 0; http.createServer(function (request, response) { response.writeHead(200, {'Content-Type': 'text/plain'}); response.end((++count).toString())
}).listen(8124); console.log('Server running at http://127.0.0.1:8124/');但是對于PHP來說就需要使用第三方媒介來存儲這個count值了,比如創建一個count.txt文件來保存網站的訪問次數。
<?php $counter_file = ("count.txt"); $visits = file($counter_file); $visits[0]++; $fp = fopen($counter_file,"w"); fputs($fp,"$visits[0]"); fclose($fp); echo "$visits[0]"; ?>單線程的js
Google的V8 Javascript引擎已經在Chrome瀏覽器里證明了它的性能,所以Node.js的作者Ryan Dahl選擇了v8作為Node.js的執行引擎,v8賦予Node.js高效性能的同時也注定了Node.js和大名鼎鼎的Nginx一樣,都是以單線程為基礎的,當然這也正是作者Ryan Dahl設計Node.js的初衷。
單線程的優缺點
Node.js的單線程具有它的優勢,但也并非十全十美,在保持單線程模型的同時,它是如何保證非阻塞的呢?
高性能
首先,單線程避免了傳統PHP那樣頻繁創建、切換線程的開銷,使執行速度更加迅速。
第二,資源占用小,如果有對Node.js的web服務器做過壓力測試的朋友可能發現,Node.js在大負荷下對內存占用仍然很低,同樣的負載PHP因為一個請求一個線程的模型,將會占用大量的物理內存,很可能會導致服務器因物理內存耗盡而頻繁交換,失去響應。
線程安全
單線程的js還保證了絕對的線程安全,不用擔心同一變量同時被多個線程進行讀寫而造成的程序崩潰。比如我們之前做的web訪問統計,因為單線程的絕對線程安全,所以不可能存在同時對count變量進行讀寫的情況,我們的統計代碼就算是成百的并發用戶請求都不會出現問題,相較PHP的那種存文件記錄訪問,就會面臨并發同時寫文件的問題。
線程安全的同時也解放了開發人員,免去了多線程編程中忘記對變量加鎖或者解鎖造成的悲劇。
單線程的異步和非阻塞
Node.js是單線程的,但是它如何做到I/O的異步和非阻塞的呢?其實Node.js在底層訪問I/O還是多線程的,有興趣的朋友可以翻看Node.js的fs模塊的源碼,里面會用到libuv來處理I/O,所以在我們看來Node.js的代碼就是非阻塞和異步形式的。
阻塞/非阻塞與異步/同步是兩個不同的概念,同步不代表阻塞,但是阻塞肯定就是同步了。
舉個現實生活中的例子,我去食堂打飯,我選擇了A套餐,然后工作人員幫我去配餐,如果我就站在旁邊,等待工作人員給我配餐,這種情況就稱之為同步;若工作人員幫我配餐的同時,排在我后面的人就開始點餐,這樣整個食堂的點餐服務并沒有因為我在等待A套餐而停止,這種情況就稱之為非阻塞。這個例子就簡單說明了同步但非阻塞的情況。
再如果我在等待配餐的時候去買飲料,等聽到叫號再回去拿套餐,此時我的飲料也已經買好,這樣我在等待配餐的同時還執行了買飲料的任務,叫號就等于執行了回調,就是異步非阻塞了。
阻塞的單線程
既然Node.js是單線程異步非阻塞的,是不是我們就可以高枕無憂了呢?
還是拿上面那個買套餐的例子,如果我在買飲料的時候,已經叫我的號讓我去拿套餐,可是我等了好久才拿到飲料,所以我可能在大廳叫我的餐號之后很久才拿到A套餐,這也就是單線程的阻塞情況。
在瀏覽器中,js都是以單線程的方式運行的,所以我們不用擔心js同時執行帶來的沖突問題,這對于我們編碼帶來很多的便利。
但是對于在服務端執行的Node.js,它可能每秒有上百個請求需要處理,對于在瀏覽器端工作良好的單線程js是否也能同樣在服務端表現良好呢?
我們看如下代碼:
var start = Date.now();//獲取當前時間戳
setTimeout(function () { console.log(Date.now() - start); for (var i = 0; i < 1000000000; i++){//執行長循環
}
}, 1000); setTimeout(function () { console.log(Date.now() - start);
}, 2000);最終我們的打印結果是:(結果可能因為你的機器而不同)
1000 3738
對于我們期望2秒后執行的setTimeout函數其實經過了3738毫秒之后才執行,換而言之,因為執行了一個很長的for循環,所以我們整個Node.js主線程被阻塞了,如果在我們處理100個用戶請求中,其中第一個有需要這樣大量的計算,那么其余99個就都會被延遲執行。
其實雖然Node.js可以處理數以千記的并發,但是一個Node.js進程在某一時刻其實只是在處理一個請求。
單線程和多核
線程是cpu調度的一個基本單位,一個cpu同時只能執行一個線程的任務,同樣一個線程任務也只能在一個cpu上執行,所以如果你運行Node.js的機器是像i5,i7這樣多核cpu,那么將無法充分利用多核cpu的性能來為Node.js服務。
多線程
在C++、C#、python等其他語言都有與之對應的多線程編程,有些時候這很有趣,帶給我們靈活的編程方式;但是也可能帶給我們一堆麻煩,需要學習更多的Api知識,在編寫更多代碼的同時也存在著更多的風險,線程的切換和鎖也會造成系統資源的開銷。
就像上面的那個例子,如果我們的Node.js有創建子線程的能力,那問題就迎刃而解了:
var start = Date.now(); createThread(function () { //創建一個子線程執行這10億次循環
console.log(Date.now() - start); for (var i = 0; i < 1000000000; i++){}
}); setTimeout(function () { //因為10億次循環是在子線程中執行的,所以主線程不受影響
console.log(Date.now() - start);
}, 2000);可惜也可以說可喜的是,Node.js的核心模塊并沒有提供這樣的api給我們,我們真的不想多線程又回歸回來。不過或許多線程真的能夠解決我們某方面的問題。
tagg2模塊
Jorge Chamorro Bieling是tagg(Threads a gogo for Node.js)包的作者,他硬是利用phread庫和C語言讓Node.js支持了多線程的開發,我們看一下tagg模塊的簡單示例:
var Threads = require('threads_a_gogo');//加載tagg包
function fibo(n) {//定義斐波那契數組計算函數
return n > 1 ? fibo(n - 1) + fibo(n - 2) : 1;
} var t = Threads.create().eval(fibo); t.eval('fibo(35)', function(err, result) {//將fibo(35)丟入子線程運行
if (err) throw err; //線程創建失敗
console.log('fibo(35)=' + result);//打印fibo執行35次的結果
}); console.log('not block');//打印信息了,表示沒有阻塞上面這段代碼利用tagg包將fibo(35)這個計算丟入了子線程中進行,保證了Node.js主線程的舒暢,當子線程任務執行完畢將會執行主線程的回調函數,把結果打印到屏幕上,執行結果如下:
not block fibo(35)=14930352
斐波那契數列,又稱黃金分割數列,這個數列從第三項開始,每一項都等于前兩項之和:0、1、1、2、3、5、8、13、21、……。
注意我們上面代碼的斐波那契數組算法并不是最優算法,只是為了模擬cpu密集型計算任務。
由于tagg包目前只能在linux下安裝運行,所以我fork了一個分支,修改了部分tagg包的代碼,發布了tagg2包。tagg2包同樣具有tagg包的多線程功能,采用新的node-gyp命令進行編譯,同時它跨平臺支持,mac,linux,windows下都可以使用,對開發人員的api也更加友好。安裝方法很簡單,直接npm install tagg2。
一個利用tagg2計算斐波那契數組的http服務器代碼:
var express = require('express'); var tagg2 = require("tagg2"); var app = express(); var th_func = function(){//線程執行函數,以下內容會在線程中執行
var fibo =function fibo (n) {//在子線程中定義fibo函數
return n > 1 ? fibo(n - 1) + fibo(n - 2) : 1;
} var n = fibo(~~thread.buffer);//執行fibo遞歸
thread.end(n);//當線程執行完畢,執行thread.end帶上計算結果回調主線程
}; app.get('/', function(req, res){ var n = ~~req.query.n || 1;//獲取用戶請求參數
var buf = new Buffer(n.toString()); tagg2.create(th_func, {buffer:buf}, function(err,result){ //創建一個js線程,傳入工作函數,buffer參數以及回調函數
if(err) return res.end(err);//如果線程創建失敗
res.end(result.toString());//響應線程執行計算的結果
})
}); app.listen(8124); console.log('listen on 8124');其中~~req.query.n表示將用戶傳遞的參數n取整,功能類似Math.floor函數。
我們用express框架搭建了一個web服務器,根據用戶發送的參數n的值來創建子線程計算斐波那契數組,當子線程計算完畢之后將結果響應給客戶端。由于計算是丟入子線程中運行的,所以整個主線程不會被阻塞,還是能夠繼續處理新請求的。
我們利用apache的http壓力測試工具ab來進行一次簡單的壓力測試,看看執行斐波那契數組35次,100客戶端并發100個請求,我們的QPS (Query Per Second)每秒查詢率在多少。
ab的全稱是ApacheBench,是Apache附帶的一個小工具,用于進行HTTP服務器的性能測試,可以同時模擬多個并發請求。
我們的測試硬件:linux 2.6.4 4cpu 8G 64bit,網絡環境則是內網。
ab壓力測試命令:
ab -c 100 -n 100 http://192.168.28.5:8124/?n=35
壓力測試結果:
Server Software: Server Hostname: 192.168.28.5 Server Port: 8124 Document Path: /?n=35 Document Length: 8 bytes Concurrency Level: 100 Time taken for tests: 5.606 seconds Complete requests: 100 Failed requests: 0 Write errors: 0 Total transferred: 10600 bytes HTML transferred: 800 bytes Requests per second: 17.84 [#/sec](mean) Time per request: 5605.769 [ms](mean) Time per request: 56.058 [ms](mean, across all concurrent requests) Transfer rate: 1.85 [Kbytes/sec] received Connection Times (ms) min mean[+/-sd] median max Connect: 3 4 0.8 4 6 Processing: 455 5367 599.7 5526 5598 Waiting: 454 5367 599.7 5526 5598 Total: 461 5372 599.3 5531 5602 Percentage of the requests served within a certain time (ms) 50% 5531 66% 5565 75% 5577 80% 5581 90% 5592 95% 5597 98% 5600 99% 5602 100% 5602 (longest request)
我們看到Requests per second表示每秒我們服務器處理的任務數量,這里是17.84。第二個我們比較關心的是兩個Time per request結果,上面一行Time per request:5605.769 [ms](mean)表示當前這個并發量下處理每組請求的時間,而下面這個Time per request:56.058 [ms](mean, across all concurrent requests)表示每個用戶平均處理時間,因為我們本次測試并發是100,所以結果正好是上一行的100分之1。得出本次測試平均每個用戶請求的平均等待時間為56.058 [ms]。
另外我們看下最后帶有百分比的列表,可以看到50%的用戶是在5531 ms以內返回的,最慢的也不過5602 ms,響應延遲非常的平均。
我們如果用cluster來啟動4個進程,是否可以充分利用cpu達到tagg2那樣的QPS呢?我們在同樣的網絡環境和測試機上運行如下代碼:
var cluster = require('cluster');//加載clustr模塊
var numCPUs = require('os').cpus().length;//設定啟動進程數為cpu個數
if (cluster.isMaster) { for (var i = 0; i < numCPUs; i++) { cluster.fork();//啟動子進程
}
} else { var express = require('express'); var app = express(); var fibo = function fibo (n) {//定義斐波那契數組算法
return n > 1 ? fibo(n - 1) + fibo(n - 2) : 1;
} app.get('/', function(req, res){ var n = fibo(~~req.query.n || 1);//接收參數
res.send(n.toString());
}); app.listen(8124); console.log('listen on 8124');
}在終端屏幕上打印了4行信息:
listen on 8124 listen on 8124 listen on 8124 listen on 8124
我們成功啟動了4個cluster之后,用同樣的ab壓力測試命令對8124端口進行測試,結果如下:
Server Software: Server Hostname: 192.168.28.5 Server Port: 8124 Document Path: /?n=35 Document Length: 8 bytes Concurrency Level: 100 Time taken for tests: 10.509 seconds Complete requests: 100 Failed requests: 0 Write errors: 0 Total transferred: 16500 bytes HTML transferred: 800 bytes Requests per second: 9.52 [#/sec](mean) Time per request: 10508.755 [ms](mean) Time per request: 105.088 [ms](mean, across all concurrent requests) Transfer rate: 1.53 [Kbytes/sec] received Connection Times (ms) min mean[+/-sd] median max Connect: 4 5 0.4 5 6 Processing: 336 3539 2639.8 2929 10499 Waiting: 335 3539 2639.9 2929 10499 Total: 340 3544 2640.0 2934 10504 Percentage of the requests served within a certain time (ms) 50% 2934 66% 3763 75% 4527 80% 5153 90% 8261 95% 9719 98% 10308 99% 10504 100% 10504 (longest request)
通過和上面tagg2包的測試結果對比,我們發現區別很大。首先每秒處理的任務數從17.84 [#/sec]下降到了9.52 [#/sec],這說明我們web服務器整體的吞吐率下降了;然后每個用戶請求的平均等待時間也從56.058 [ms]提高到了105.088 [ms],用戶等待的時間也更長了。
最后我們發現用戶請求處理的時長非常的不均勻,50%的用戶在2934 ms內返回了,最慢的等待達到了10504 ms。雖然我們使用了cluster啟動了4個Node.js進程處理用戶請求,但是對于每個Node.js進程來說還是單線程的,所以當有4個用戶跑滿了4個Node.js的cluster進程之后,新來的用戶請求就只能等待了,最后造成了先到的用戶處理時間短,后到的用戶請求處理時間比較長,就造成了用戶等待時間非常的不平均。
v8引擎
大家看到這里是不是開始心潮澎湃,感覺js一統江湖的時代來臨了,單線程異步非阻塞的模型可以勝任大并發,同時開發也非常高效,多線程下的js可以承擔cpu密集型任務,不會有主線程阻塞而引起的性能問題。
但是,不論tagg還是tagg2包都是利用phtread庫和v8的v8::Isolate Class類來實現js多線程功能的。
Isolate代表著一個獨立的v8引擎實例,v8的Isolate擁有完全分開的狀態,在一個Isolate實例中的對象不能夠在另外一個Isolate實例中使用。嵌入式開發者可以在其他線程創建一些額外的Isolate實例并行運行。在任何時刻,一個Isolate實例只能夠被一個線程進行訪問,可以利用加鎖/解鎖進行同步操作。
換而言之,我們在進行v8的嵌入式開發時,無法在多線程中訪問js變量,這條規則將直接導致我們之前的tagg2里面線程執行的函數無法使用Node.js的核心api,比如fs,crypto等模塊。如此看來,tagg2包還是有它使用的局限性,針對一些可以使用js原生的大量計算或循環可以使用tagg2,Node.js核心api因為無法從主線程共享對象的關系,也就不能跨線程使用了。
libuv
最后,如果我們非要讓Node.js支持多線程,還是提倡使用官方的做法,利用libuv庫來實現。
libuv是一個跨平臺的異步I/O庫,它主要用于Node.js的開發,同時他也被Mozilla's Rust language,Luvit,Julia,pyuv等使用。它主要包括了Event loops事件循環,Filesystem文件系統,Networking網絡支持,Threads線程,Processes進程,Utilities其他工具。
在Node.js核心api中的異步多線程大多是使用libuv來實現的,下一章將帶領大家開發一個讓Node.js支持多線程并基于libuv的Node.js包。
多進程
在支持html5的瀏覽器里,我們可以使用webworker來將一些耗時的計算丟入worker進程中執行,這樣主進程就不會阻塞,用戶也就不會有卡頓的感覺了。在Node.js中是否也可以使用這類技術,保證主線程的通暢呢?
cluster
cluster可以用來讓Node.js充分利用多核cpu的性能,同時也可以讓Node.js程序更加健壯,官網上的cluster示例已經告訴我們如何重新啟動一個因為異常而奔潰的子進程。
webworker
想要像在瀏覽器端那樣啟動worker進程,我們需要利用Node.js核心api里的child_process模塊。child_process模塊提供了fork的方法,可以啟動一個Node.js文件,將它作為worker進程,當worker進程工作完畢,把結果通過send方法傳遞給主進程,然后自動退出,這樣我們就利用了多進程來解決主線程阻塞的問題。
我們先啟動一個web服務,還是接收參數計算斐波那契數組:
var express = require('express'); var fork = require('child_process').fork; var app = express(); app.get('/', function(req, res){ var worker = fork('./work_fibo.js') //創建一個工作進程
worker.on('message', function(m) {//接收工作進程計算結果
if('object' === typeof m && m.type === 'fibo'){ worker.kill();//發送殺死進程的信號
res.send(m.result.toString());//將結果返回客戶端
}
}); worker.send({type:'fibo',num:~~req.query.n || 1}); //發送給工作進程計算fibo的數量
}); app.listen(8124);我們通過express監聽8124端口,對每個用戶的請求都會去fork一個子進程,通過調用worker.send方法將參數n傳遞給子進程,同時監聽子進程發送消息的message事件,將結果響應給客戶端。
下面是被fork的work_fibo.js文件內容:
var fibo = function fibo (n) {//定義算法
return n > 1 ? fibo(n - 1) + fibo(n - 2) : 1;
} process.on('message', function(m) { //接收主進程發送過來的消息
if(typeof m === 'object' && m.type === 'fibo'){ var num = fibo(~~m.num); //計算jibo
process.send({type: 'fibo',result:num}) //計算完畢返回結果
}
}); process.on('SIGHUP', function() { process.exit();//收到kill信息,進程退出
});我們先定義函數fibo用來計算斐波那契數組,然后監聽了主線程發來的消息,計算完畢之后將結果send到主線程。同時還監聽process的SIGHUP事件,觸發此事件就進程退出。
這里我們有一點需要注意,主線程的kill方法并不是真的使子進程退出,而是會觸發子進程的SIGHUP事件,真正的退出還是依靠process.exit();。
下面我們用ab 命令測試一下多進程方案的處理性能和用戶請求延遲,測試環境不變,還是100個并發100次請求,計算斐波那切數組第35位:
Server Software: Server Hostname: 192.168.28.5 Server Port: 8124 Document Path: /?n=35 Document Length: 8 bytes Concurrency Level: 100 Time taken for tests: 7.036 seconds Complete requests: 100 Failed requests: 0 Write errors: 0 Total transferred: 16500 bytes HTML transferred: 800 bytes Requests per second: 14.21 [#/sec](mean) Time per request: 7035.775 [ms](mean) Time per request: 70.358 [ms](mean, across all concurrent requests) Transfer rate: 2.29 [Kbytes/sec] received Connection Times (ms) min mean[+/-sd] median max Connect: 4 4 0.2 4 5 Processing: 4269 5855 970.3 6132 7027 Waiting: 4269 5855 970.3 6132 7027 Total: 4273 5860 970.3 6136 7032 Percentage of the requests served within a certain time (ms) 50% 6136 66% 6561 75% 6781 80% 6857 90% 6968 95% 7003 98% 7017 99% 7032 100% 7032 (longest request)
壓力測試結果QPS約為14.21,相比cluster來說,還是快了很多,每個用戶請求的延遲都很平均,因為進程的創建和銷毀的開銷要大于線程,所以在性能方面略低于tagg2,不過相對于cluster方案,這樣的提升還是令我們滿意的。
換一種思路
使用child_process模塊的fork方法確實可以讓我們很好的解決單線程對cpu密集型任務的阻塞問題,同時又沒有tagg2包那樣無法使用Node.js核心api的限制。
但是如果我的worker具有多樣性,每次在利用child_process模塊解決問題時都需要去創建一個worker.js的工作函數文件,有點麻煩。我們是不是可以更加簡單一些呢?
在我們啟動Node.js程序時,node命令可以帶上-e這個參數,它將直接執行-e后面的字符串,如下代碼就將打印出hello world。
node -e "console.log('hello world')"合理的利用這個特性,我們就可以免去每次都創建一個文件的麻煩。
var express = require('express');
var spawn = require('child_process').spawn;
var app = express();
var spawn_worker = function(n,end){//定義工作函數
var fibo = function fibo (n) {
return n > 1 ? fibo(n - 1) + fibo(n - 2) : 1;
}
end(fibo(n));
}
var spawn_end = function(result){//定義工作函數結束的回調函數參數
console.log(result);
process.exit();
}
app.get('/', function(req, res){
var n = ~~req.query.n || 1;
//拼接-e后面的參數
var spawn_cmd = '('+spawn_worker.toString()+'('+n+','+spawn_end.toString()+'));'
console.log(spawn_cmd);//注意這個打印結果
var worker = spawn('node',['-e',spawn_cmd]);//執行node -e "xxx"命令
var fibo_res = '';
worker.stdout.on('data', function (data) { //接收工作函數的返回
fibo_res += data.toString();
});
worker.on('close', function (code) {//將結果響應給客戶端
res.send(fibo_res);
});
});
app.listen(8124);代碼很簡單,我們主要關注3個地方。
第一、我們定義了spawn_worker函數,他其實就是將會在-e后面執行的工作函數,所以我們把計算斐波那契數組的算法定義在內,spawn_worker函數接收2個參數,第一個參數n表示客戶請求要計算的斐波那契數組的位數,第二個end參數是一個函數,如果計算完畢則執行end,將結果傳回主線程;
第二、真正當Node.js腳步執行的字符串其實就是spawn_cmd里的內容,它的內容我們通過運行之后的打印信息,很容易就能明白;
第三、我們利用child_process的spawn方法,類似在命令行里執行了node -e "js code",啟動Node.js工作進程,同時監聽子進程的標準輸出,將數據保存起來,當子進程退出之后把結果響應給用戶。
現在主要的焦點就是變量spawn_cmd到底保存了什么,我們打開瀏覽器在地址欄里輸入:
http://127.0.0.1:8124/?n=35
下面就是程序運行之后的打印信息,
(function (n,end){ var fibo = function fibo (n) { return n > 1 ? fibo(n - 1) + fibo(n - 2) : 1;
} end(fibo(n));
}(35,function (result){ console.log(result); process.exit();
}));對于在子進程執行的工作函數的兩個參數n和end現在一目了然,n代表著用戶請求的參數,期望獲得的斐波那契數組的位數,而end參數則是一個匿名函數,在標準輸出中打印計算結果然后退出進程。
node -e命令雖然可以減少創建文件的麻煩,但同時它也有命令行長度的限制,這個值各個系統都不相同,我們通過命令getconf ARG_MAX來獲得最大命令長度,例如:MAC OSX下是262,144 byte,而我的linux虛擬機則是131072 byte。
多進程和多線程
大部分多線程解決cpu密集型任務的方案都可以用我們之前討論的多進程方案來替代,但是有一些比較特殊的場景多線程的優勢就發揮出來了,下面就拿我們最常見的http web服務器響應一個小的靜態文件作為例子。
以express處理小型靜態文件為例,大致的處理流程如下:
首先獲取文件狀態,判斷文件的修改時間或者判斷
etag來確定是否響應304給客戶端,讓客戶端繼續使用本地緩存。如果緩存已經失效或者客戶端沒有緩存,就需要獲取文件的內容到buffer中,為響應作準備。
然后判斷文件的
MIME類型,如果是類似html,js,css等靜態資源,還需要gzip壓縮之后傳輸給客戶端最后將gzip壓縮完成的靜態文件響應給客戶端。
下面是一個正常成功的Node.js處理靜態資源無緩存流程圖:
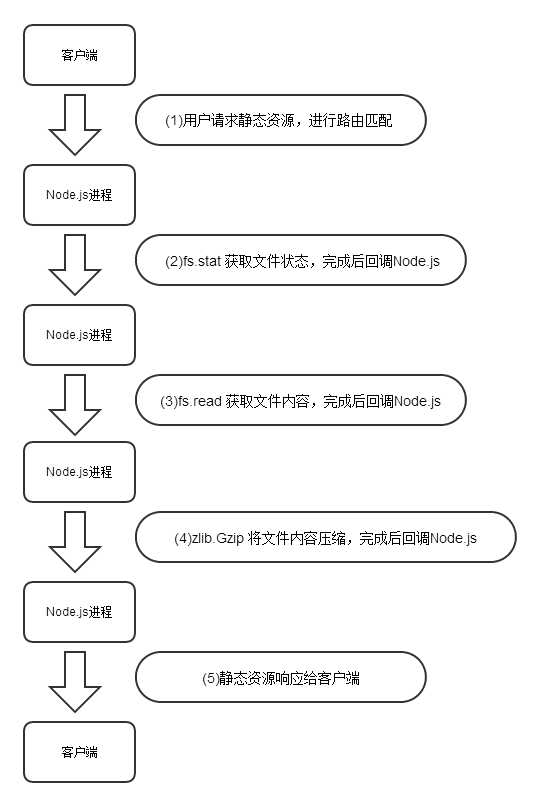
這個流程中的(2),(3),(4)步都經歷了從js到C++ ,打開和釋放文件,還有調用了zlib庫的gzip算法,其中每個異步的算法都會有創建和銷毀線程的開銷,所以這樣也是大家詬病Node.js處理靜態文件不給力的原因之一。
為了改善這個問題,我之前有利用libuv庫開發了一個改善Node.js的http/https處理靜態文件的包,名為ifile,ifile包,之所以可以加速Node.js的靜態文件處理性能,主要是減少了js和C++的互相調用,以及頻繁的創建和銷毀線程的開銷,下圖是ifile包處理一個靜態無緩存資源的流程圖:
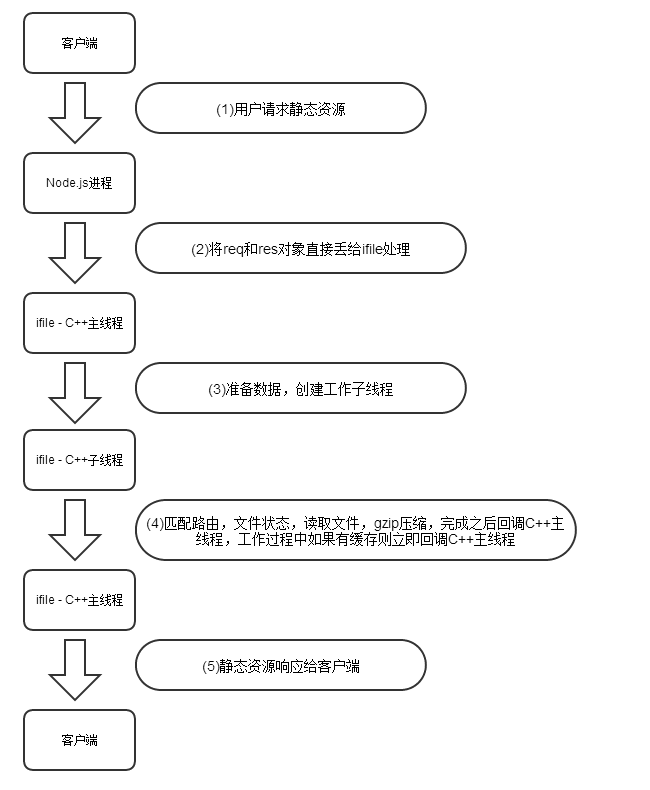
由于全部工作都是在libuv的子線程中執行的,所以Node.js主線程不會阻塞,當然性能也會大幅提升了,使用ifile包非常簡單,它能夠和express無縫的對接。
var express = require('express'); var ifile = require("ifile"); var app = express();
app.use(ifile.connect()); //默認值是 [['/static',__dirname]];
app.listen(8124);上面這4行代碼就可以讓express把靜態資源交給ifile包來處理了,我們在這里對它進行了一個簡單的壓力測試,測試用例為響應一個大小為92kb的jquery.1.7.1.min.js文件,測試命令:
ab -c 500 -n 5000 -H "Accept-Encoding: gzip" http://192.168.28.5:8124/static/jquery.1.7.1.min.js
由于在ab命令中我們加入了-H "Accept-Encoding: gzip",表示響應的靜態文件希望是gzip壓縮之后的,所以ifile將會把壓縮之后的jquery.1.7.1.min.js文件響應給客戶端。結果如下:
Server Software: Server Hostname: 192.168.28.5 Server Port: 8124 Document Path: /static/jquery.1.7.1.min.js Document Length: 33016 bytes Concurrency Level: 500 Time taken for tests: 9.222 seconds Complete requests: 5000 Failed requests: 0 Write errors: 0 Total transferred: 166495000 bytes HTML transferred: 165080000 bytes Requests per second: 542.16 [#/sec](mean) Time per request: 922.232 [ms](mean) Time per request: 1.844 [ms](mean, across all concurrent requests) Transfer rate: 17630.35 [Kbytes/sec] received Connection Times (ms) min mean[+/-sd] median max Connect: 0 49 210.2 1 1003 Processing: 191 829 128.6 870 1367 Waiting: 150 824 128.5 869 1091 Total: 221 878 230.7 873 1921 Percentage of the requests served within a certain time (ms) 50% 873 66% 878 75% 881 80% 885 90% 918 95% 1109 98% 1815 99% 1875 100% 1921 (longest request)
我們首先看到Document Length一項結果為33016 bytes說明我們的jquery文件已經被成功的gzip壓縮,因為源文件大小是92kb;其次,我們最關心的Requests per second:542.16 [#/sec](mean),說明我們每秒能處理542個任務;最后,我們看到,在這樣的壓力情況下,平均每個用戶的延遲在1.844 [ms]。
我們看下使用express框架處理這樣的壓力會是什么樣的結果,express測試代碼如下:
var express = require('express'); var app = express(); app.use(express.compress());//支持gzip
app.use('/static', express.static(__dirname + '/static')); app.listen(8124);代碼同樣非常簡單,注意這里我們使用:
app.use('/static', express.static(__dirname + '/static'));而不是:
app.use(express.static(__dirname));
后者每個請求都會去匹配一次文件是否存在,而前者只有請求url是/static開頭的才會去匹配靜態資源,所以前者效率更高一些。然后我們執行相同的ab壓力測試命令看下結果:
Server Software: Server Hostname: 192.168.28.5 Server Port: 8124 Document Path: /static/jquery.1.7.1.min.js Document Length: 33064 bytes Concurrency Level: 500 Time taken for tests: 16.665 seconds Complete requests: 5000 Failed requests: 0 Write errors: 0 Total transferred: 166890000 bytes HTML transferred: 165320000 bytes Requests per second: 300.03 [#/sec](mean) Time per request: 1666.517 [ms](mean) Time per request: 3.333 [ms](mean, across all concurrent requests) Transfer rate: 9779.59 [Kbytes/sec] received Connection Times (ms) min mean[+/-sd] median max Connect: 0 173 539.8 1 7003 Processing: 509 886 350.5 809 9366 Waiting: 238 476 277.9 426 9361 Total: 510 1059 632.9 825 9367 Percentage of the requests served within a certain time (ms) 50% 825 66% 908 75% 1201 80% 1446 90% 1820 95% 1952 98% 2560 99% 3737 100% 9367 (longest request)
同樣分析一下結果,Document Length:33064 bytes表示文檔大小為33064 bytes,說明我們的gzip起作用了,每秒處理任務數從ifile包的542下降到了300,最長用戶等待時間也延長到了9367 ms,可見我們的努力起到了立竿見影的作用,js和C++互相調用以及線程的創建和釋放并不是沒有損耗的。
但是當我在express的谷歌論壇里貼上這些測試結果,并宣傳ifile包的時候,express的作者TJ,給出了不一樣的評價,他在回復中說道:
請牢記你可能不需要這么高等級吞吐率的系統,就算是每月百萬級別下載量的
npm網站,也僅僅每秒處理17個請求而已,這樣的壓力甚至于PHP也可以處理掉(又黑了一把php)。
確實如TJ所說,性能只是我們項目的指標之一而非全部,一味的去追求高性能并不是很理智。
ifile包開源項目地址:https://github.com/DoubleSpout/ifile
總結
單線程的Node.js給我們編碼帶來了太多的便利和樂趣,我們應該時刻保持清醒的頭腦,在寫Node.js代碼中切不可與PHP混淆,任何一個隱藏的問題都可能擊潰整個線上正在運行的Node.js程序。
單線程異步的Node.js不代表不會阻塞,在主線程做過多的任務可能會導致主線程的卡死,影響整個程序的性能,所以我們要非常小心的處理大量的循環,字符串拼接和浮點運算等cpu密集型任務,合理的利用各種技術把任務丟給子線程或子進程去完成,保持Node.js主線程的暢通。
線程/進程的使用并不是沒有開銷的,盡可能減少創建和銷毀線程/進程的次數,可以提升我們系統整體的性能和出錯的概率。
最后請不要一味的追求高性能和高并發,因為我們可能不需要系統具有那么大的吞吐率。高效,敏捷,低成本的開發才是項目所需要的,這也是為什么Node.js能夠在眾多開發語言中脫穎而出的關鍵。
相關教程
- PHP編程:簡單談談PHP vs Node.js
- 實戰Angular2/Mongodb/Node博客系統(二)
- 基于MongoDB與NodeJS構建物聯網系統
- LINUX教學:Linux文件系統:基本文件類型和inode
- LINUX實戰:Ubuntu 16.04離線安裝Nodejs與JDK
- 一個簡單的node.js寫入文件的示例
- node.js如何連接mysql
- node.js中使用ES6的箭頭函數“=>”
- npm更新和nodejs更新升級
- Node.js模塊全局安裝路徑配置
- node.js定時器node-schedule模塊
- 讓Nodejs來管理定時器任務later
- node.js安裝wx-voice轉換silk和mp3
- node.js如何在terminal顯示二維碼?
- 怎樣接收node.js運行時附加的參數?
同類教程排行
- node.js出現selenium錯誤:
- node.js安裝wx-voice轉換s
- selenium之使用chrome瀏覽器
- node.js如何在terminal顯示
- node.js如何連接mysql
- NODE.JS selenium-web
- 讓Nodejs來管理定時器任務later
- PHP應用:golang、python、
- 怎樣接收node.js運行時附加的參數?
- node.js中使用ES6的箭頭函數“=
- Node.js模塊全局安裝路徑配置
- node.js定時器node-sched
- Ansible部署Node.js,讓你從
- 在linux centos上安裝node
- npm更新和nodejs更新升級
