Mysql應(yīng)用MySQL學(xué)習(xí)筆記小結(jié)
《Mysql應(yīng)用MySQL學(xué)習(xí)筆記小結(jié)》要點(diǎn):
本文介紹了Mysql應(yīng)用MySQL學(xué)習(xí)筆記小結(jié),希望對(duì)您有用。如果有疑問,可以聯(lián)系我們。
慢速SQL:執(zhí)行時(shí)間超過給定時(shí)間范圍的查詢就稱為慢速查詢.
在MySQL中如何記錄慢速SQL?
答:可以在my.cnf中設(shè)置如下信息:MYSQL教程
[mysqld] ; enable the slow query log, default 10 seconds log-slow-queries ; log queries taking longer than 5 seconds long_query_time = 5 ; log queries that don't use indexes even if they take less than long_query_time ; MySQL 4.1 and newer only log-queries-not-using-indexes
這三個(gè)設(shè)置的意思是可以記錄執(zhí)行時(shí)間超過5 秒和沒有使用索引的查詢.
MySQL中日志分類:
1. error log mysql錯(cuò)誤記錄日志
2. bin log 記錄修改數(shù)據(jù)時(shí)候產(chǎn)生的quer并用二進(jìn)制的方式進(jìn)行存儲(chǔ)
3. mysql-bin.index 記錄是記錄所有Binary Log 的絕對(duì)路徑,保證MySQL 各種線程能夠順利的根據(jù)它找到所有需要的Binary Log 文件.
4. slow query log 記錄慢速SQL,是一個(gè)簡(jiǎn)單的文本格式,可以通過各種文本編輯器查看其中的內(nèi)容.其中記錄了語句執(zhí)行的時(shí)刻,執(zhí)行所消耗的時(shí)間,執(zhí)行用戶.
5. innodb redo log 記錄Innodb 所做的所有物理變更和事務(wù)信息,保證事務(wù)安全性.
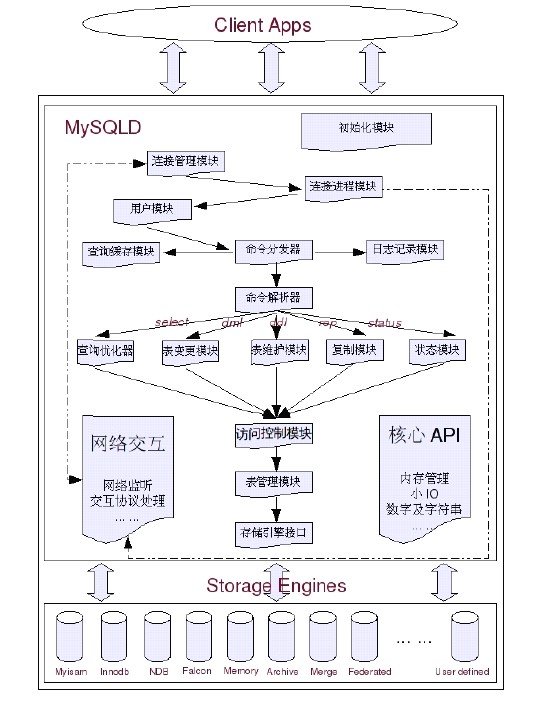
SQL架構(gòu)可分為:SQL 層 與 Storage Engine層
SQL Layer 中包含了多個(gè)子模塊:
1、初始化模塊
顧名思議,初始化模塊就是在MySQL Server 啟動(dòng)的時(shí)候,對(duì)整個(gè)系統(tǒng)做各種各樣的初始化操作,比如各種buffer,cache 結(jié)構(gòu)的初始化和內(nèi)存空間的申請(qǐng),各種系統(tǒng)變量的初始化設(shè)定,各種存儲(chǔ)引擎的初始化設(shè)置,等等.
2、核心API
核心API 模塊主要是為了提供一些需要非常高效的底層操作功能的優(yōu)化實(shí)現(xiàn),包括各種底層數(shù)據(jù)結(jié)構(gòu)的實(shí)現(xiàn),特殊算法的實(shí)現(xiàn),字符串處理,數(shù)字處理等,小文件I/O,格式化輸出,以及最重要的內(nèi)存管理部分.核心API 模塊的所有源代碼都集中在mysys 和strings文件夾下面,有興趣的讀者可以研究研究.
3、網(wǎng)絡(luò)交互模塊
底層網(wǎng)絡(luò)交互模塊抽象出底層網(wǎng)絡(luò)交互所使用的接口api,實(shí)現(xiàn)底層網(wǎng)絡(luò)數(shù)據(jù)的接收與發(fā)送,以方便其他各個(gè)模塊調(diào)用,以及對(duì)這一部分的維護(hù).所有源碼都在vio 文件夾下面.
4、Client & Server 交互協(xié)議模塊
任何C/S 結(jié)構(gòu)的軟件系統(tǒng),都肯定會(huì)有自己獨(dú)有的信息交互協(xié)議,MySQL 也不例外.MySQL的Client & Server 交互協(xié)議模塊部分,實(shí)現(xiàn)了客戶端與MySQL 交互過程中的所有協(xié)議.當(dāng)然這些協(xié)議都是建立在現(xiàn)有的OS 和網(wǎng)絡(luò)協(xié)議之上的,如TCP/IP 以及Unix Socket.
5、用戶模塊
用戶模塊所實(shí)現(xiàn)的功能,主要包括用戶的登錄連接權(quán)限控制和用戶的授權(quán)管理.他就像MySQL 的大門守衛(wèi)一樣,決定是否給來訪者“開門”.
6、訪問控制模塊
造訪客人進(jìn)門了就可以想干嘛就干嘛么?為了安全考慮,肯定不能如此隨意.這時(shí)候就需要訪問控制模塊實(shí)時(shí)監(jiān)控客人的每一個(gè)動(dòng)作,給不同的客人以不同的權(quán)限.訪問控制模塊實(shí)現(xiàn)的功能就是根據(jù)用戶模塊中各用戶的授權(quán)信息,以及數(shù)據(jù)庫(kù)自身特有的各種約束,來控制用戶對(duì)數(shù)據(jù)的訪問.用戶模塊和訪問控制模塊兩者結(jié)合起來,組成了MySQL 整個(gè)數(shù)據(jù)庫(kù)系統(tǒng)的權(quán)限安全管理的功能.
7、連接管理、連接線程和線程管理
連接管理模塊負(fù)責(zé)監(jiān)聽對(duì)MySQL Server 的各種請(qǐng)求,接收連接請(qǐng)求,轉(zhuǎn)發(fā)所有連接請(qǐng)求到線程管理模塊.每一個(gè)連接上MySQL Server 的客戶端請(qǐng)求都會(huì)被分配(或創(chuàng)建)一個(gè)連接線程為其單獨(dú)服務(wù).而連接線程的主要工作就是負(fù)責(zé)MySQL Server 與客戶端的通信,接受客戶端的命令請(qǐng)求,傳遞Server 端的結(jié)果信息等.線程管理模塊則負(fù)責(zé)管理維護(hù)這些連接線程.包括線程的創(chuàng)建,線程的cache 等.
8、Query 解析和轉(zhuǎn)發(fā)模塊
在MySQL 中我們習(xí)慣將所有Client 端發(fā)送給Server 端的命令都稱為query,在MySQLServer 里面,連接線程接收到客戶端的一個(gè)Query 后,會(huì)直接將該query 傳遞給專門負(fù)責(zé)將各種Query 進(jìn)行分類然后轉(zhuǎn)發(fā)給各個(gè)對(duì)應(yīng)的處理模塊,這個(gè)模塊就是query 解析和轉(zhuǎn)發(fā)模塊.其主要工作就是將query 語句進(jìn)行語義和語法的分析,然后按照不同的操作類型進(jìn)行分類,然后做出針對(duì)性的轉(zhuǎn)發(fā).
9、Query Cache 模塊
Query Cache 模塊在MySQL 中是一個(gè)非常重要的模塊,他的主要功能是將客戶端提交給MySQL 的Select 類query 請(qǐng)求的返回結(jié)果集cache 到內(nèi)存中,與該query 的一個(gè)hash 值做一個(gè)對(duì)應(yīng).該Query 所取數(shù)據(jù)的基表發(fā)生任何數(shù)據(jù)的變化之后,MySQL 會(huì)自動(dòng)使該query 的Cache 失效.在讀寫比例非常高的應(yīng)用系統(tǒng)中,Query Cache 對(duì)性能的提高是非常顯著的.當(dāng)然它對(duì)內(nèi)存的消耗也是非常大的.
10、Query 優(yōu)化器模塊
Query 優(yōu)化器,顧名思義,就是優(yōu)化客戶端請(qǐng)求的query,根據(jù)客戶端請(qǐng)求的query 語句,和數(shù)據(jù)庫(kù)中的一些統(tǒng)計(jì)信息,在一系列算法的基礎(chǔ)上進(jìn)行分析,得出一個(gè)最優(yōu)的策略,告訴后面的程序如何取得這個(gè)query 語句的結(jié)果.
11、表變更管理模塊
表變更管理模塊主要是負(fù)責(zé)完成一些DML 和DDL 的query,如:update,delte,insert,create table,alter table 等語句的處理.
12、表維護(hù)模塊
表的狀態(tài)檢查,錯(cuò)誤修復(fù),以及優(yōu)化和分析等工作都是表維護(hù)模塊需要做的事情.
13、系統(tǒng)狀態(tài)管理模塊
系統(tǒng)狀態(tài)管理模塊負(fù)責(zé)在客戶端請(qǐng)求系統(tǒng)狀態(tài)的時(shí)候,將各種狀態(tài)數(shù)據(jù)返回給用戶,像DBA 常用的各種show status 命令,show variables 命令等,所得到的結(jié)果都是由這個(gè)模塊返回的.
14、表管理器
這個(gè)模塊從名字上看來很容易和上面的表變更和表維護(hù)模塊相混淆,但是其功能與變更及維護(hù)模塊卻完全不同.大家知道,每一個(gè)MySQL 的表都有一個(gè)表的定義文件,也就是*.frm文件.表管理器的工作主要就是維護(hù)這些文件,以及一個(gè)cache,該cache 中的主要內(nèi)容是各個(gè)表的結(jié)構(gòu)信息.此外它還維護(hù)table 級(jí)別的鎖管理.
15、日志記錄模塊
日志記錄模塊主要負(fù)責(zé)整個(gè)系統(tǒng)級(jí)別的邏輯層的日志的記錄,包括error log,binarylog,slow query log 等.
16、復(fù)制模塊
復(fù)制模塊又可分為Master 模塊和Slave 模塊兩部分, Master 模塊主要負(fù)責(zé)在Replication 環(huán)境中讀取Master 端的binary 日志,以及與Slave 端的I/O 線程交互等工作.Slave 模塊比Master 模塊所要做的事情稍多一些,在系統(tǒng)中主要體現(xiàn)在兩個(gè)線程上面.一個(gè)是負(fù)責(zé)從Master 請(qǐng)求和接受binary 日志,并寫入本地relay log 中的I/O 線程.另外一個(gè)是負(fù)責(zé)從relay log 中讀取相關(guān)日志事件,然后解析成可以在Slave 端正確執(zhí)行并得到和Master 端完全相同的結(jié)果的命令并再交給Slave 執(zhí)行的SQL 線程.
17、存儲(chǔ)引擎接口模塊
存儲(chǔ)引擎接口模塊可以說是MySQL 數(shù)據(jù)庫(kù)中最有特色的一點(diǎn)了.目前各種數(shù)據(jù)庫(kù)產(chǎn)品
中,基本上只有MySQL 可以實(shí)現(xiàn)其底層數(shù)據(jù)存儲(chǔ)引擎的插件式管理.這個(gè)模塊實(shí)際上只是一個(gè)抽象類,但正是因?yàn)樗晒Φ貙⒏鞣N數(shù)據(jù)處理高度抽象化,才成就了今天MySQL 可插拔存儲(chǔ)引擎的特色.MYSQL教程
 MYSQL教程
MYSQL教程
MySQL性能調(diào)優(yōu)之監(jiān)控方法:MYSQL教程
1. set profiling=1 開啟性能監(jiān)控,此命令在某些版本的mysql中無法使用
2. 然后執(zhí)行SQL
3. show profiless,查看系統(tǒng)執(zhí)行SQL的時(shí)間
4. show profile cpu, block io for query 數(shù)字ID (此ID為show profiles中的性能輸出日志序號(hào))MYSQL教程
?MySQL 各存儲(chǔ)引擎使用了三種類型(級(jí)別)的鎖定機(jī)制:行級(jí)鎖定,頁級(jí)鎖定和表級(jí)鎖定.
在MySQL 數(shù)據(jù)庫(kù)中,使用表級(jí)鎖定的主要是MyISAM,Memory,CSV 等一些非事務(wù)性存儲(chǔ)引擎,而使用行級(jí)鎖定的主要是Innodb 存儲(chǔ)引擎和NDB Cluster 存儲(chǔ)引擎,頁級(jí)鎖定主要是BerkeleyDB 存儲(chǔ)引擎的鎖定方式.
?
MyISAM讀請(qǐng)求和寫等待隊(duì)列中的寫鎖請(qǐng)求的優(yōu)先級(jí)規(guī)則主要為以下規(guī)則決定:
1. 除了READ_HIGH_PRIORITY 的讀鎖定之外,Pending write-lock queue 中的WRITE 寫鎖定能夠阻塞所有其他的讀鎖定;
2. READ_HIGH_PRIORITY 讀鎖定的請(qǐng)求能夠阻塞所有Pending write-lock queue 中的寫鎖定;
3. 除了WRITE 寫鎖定之外,Pending write-lock queue 中的其他任何寫鎖定都比讀鎖定的優(yōu)先級(jí)低.MYSQL教程
MyISAM寫鎖定出現(xiàn)在Current write-lock queue 之后,會(huì)阻塞除了以下情況下的所有其他鎖定的請(qǐng)求:
1. 在某些存儲(chǔ)引擎的允許下,可以允許一個(gè)WRITE_CONCURRENT_INSERT 寫鎖定請(qǐng)求
2. 寫鎖定為WRITE_ALLOW_WRITE 的時(shí)候,允許除了WRITE_ONLY 之外的所有讀和寫鎖定請(qǐng)求
3. 寫鎖定為WRITE_ALLOW_READ 的時(shí)候,允許除了READ_NO_INSERT 之外的所有讀鎖定請(qǐng)求
4. 寫鎖定為WRITE_DELAYED 的時(shí)候,允許除了READ_NO_INSERT 之外的所有讀鎖定請(qǐng)求
5. 寫鎖定為WRITE_CONCURRENT_INSERT 的時(shí)候,允許除了READ_NO_INSERT 之外的所有讀鎖定請(qǐng)求
?
Innodb 的行級(jí)鎖定注意事項(xiàng):
a) 盡可能讓所有的數(shù)據(jù)檢索都通過索引來完成,從而避免Innodb 因?yàn)闊o法通過索引鍵加鎖而升級(jí)為表級(jí)鎖定;
b) 合理設(shè)計(jì)索引,讓Innodb 在索引鍵上面加鎖的時(shí)候盡可能準(zhǔn)確,盡可能的縮小鎖定范圍,避免造成不必要的鎖定而影響其他Query 的執(zhí)行;
c) 盡可能減少基于范圍的數(shù)據(jù)檢索過濾條件,避免因?yàn)殚g隙鎖帶來的負(fù)面影響而鎖定了不該鎖定的記錄;
d) 盡量控制事務(wù)的大小,減少鎖定的資源量和鎖定時(shí)間長(zhǎng)度;
e) 在業(yè)務(wù)環(huán)境允許的情況下,盡量使用較低級(jí)別的事務(wù)隔離,以減少M(fèi)ySQL 因?yàn)閷?shí)現(xiàn)事務(wù)隔離級(jí)別所帶來的附加成本;
如何查看MyISAM中表級(jí)鎖定信息:
答:show status like '%table_locks%'
???? table_locks_immediate:顯示的數(shù)字就是鎖定的次數(shù).
???? table_locks_waited:顯示的數(shù)字是出現(xiàn)表級(jí)鎖定爭(zhēng)用而發(fā)生等待的次數(shù)
?
如何查看Innodb中行級(jí)鎖定信息:
答: show status like '%Innodb_rows%'
Innodb 的行級(jí)鎖定狀態(tài)變量不僅記錄了鎖定等待次數(shù),還記錄了鎖定總時(shí)長(zhǎng),每次平均時(shí)長(zhǎng),以及最大時(shí)長(zhǎng),此外還有一個(gè)非累積狀態(tài)量顯示了當(dāng)前正在等待鎖定的等待數(shù)量.對(duì)各個(gè)狀態(tài)量的說明如下:
● Innodb_row_lock_current_waits:當(dāng)前正在等待鎖定的數(shù)量;
● Innodb_row_lock_time:從系統(tǒng)啟動(dòng)到現(xiàn)在鎖定總時(shí)間長(zhǎng)度;
● Innodb_row_lock_time_avg:每次等待所花平均時(shí)間;
● Innodb_row_lock_time_max:從系統(tǒng)啟動(dòng)到現(xiàn)在等待最常的一次所花的時(shí)間;
● Innodb_row_lock_waits:系統(tǒng)啟動(dòng)后到現(xiàn)在總共等待的次數(shù);
?
mysqlslap是一個(gè)mysql官方提供的壓力測(cè)試工具.以下是比較重要的參數(shù):
Cdefaults-file,配置文件存放位置
Cconcurrency,并發(fā)數(shù)
Cengines,引擎
Citerations,迭代的實(shí)驗(yàn)次數(shù)
Csocket,socket文件位置
自動(dòng)測(cè)試:
Cauto-generate-sql,自動(dòng)產(chǎn)生測(cè)試SQL
Cauto-generate-sql-load-type,測(cè)試SQL的類型.類型有mixed,update,write,key,read.
Cnumber-of-queries,執(zhí)行的SQL總數(shù)量
Cnumber-int-cols,表內(nèi)int列的數(shù)量
Cnumber-char-cols,表內(nèi)char列的數(shù)量
例如:
shell>mysqlslap Cdefaults-file=/u01/mysql1/mysql/my.cnf Cconcurrency=50,100 Citerations=1 Cnumber-int-cols=4 Cauto-generate-sql Cauto-generate-sql-load-type=write Cengine=myisam Cnumber-of-queries=200 -S/tmp/mysql1.sock
Benchmark
Running for engine myisam
Average number of seconds to run all queries: 0.016 seconds
Minimum number of seconds to run all queries: 0.016 seconds
Maximum number of seconds to run all queries: 0.016 seconds
Number of clients running queries: 50
Average number of queries per client: 4
Benchmark
Running for engine myisam
Average number of seconds to run all queries: 0.265 seconds
Minimum number of seconds to run all queries: 0.265 seconds
Maximum number of seconds to run all queries: 0.265 seconds
Number of clients running queries: 100
Average number of queries per client: 2
指定數(shù)據(jù)庫(kù)的測(cè)試:
Ccreate-schema,指定數(shù)據(jù)庫(kù)名稱
Cquery,指定SQL語句,可以定位到某個(gè)包含SQL的文件
例如:
shell>mysqlslap Cdefaults-file=/u01/mysql1/mysql/my.cnf Cconcurrency=25,50 Citerations=1 Ccreate-schema=test Cquery=/u01/test.sql -S/tmp/mysql1.sock
Benchmark
Average number of seconds to run all queries: 0.018 seconds
Minimum number of seconds to run all queries: 0.018 seconds
Maximum number of seconds to run all queries: 0.018 seconds
Number of clients running queries: 25
Average number of queries per client: 1
Benchmark
Average number of seconds to run all queries: 0.011 seconds
Minimum number of seconds to run all queries: 0.011 seconds
Maximum number of seconds to run all queries: 0.011 seconds
Number of clients running queries: 50
Average number of queries per client: 1
?
MySQL 中索引使用相關(guān)的限制:
1. MyISAM 存儲(chǔ)引擎索引鍵長(zhǎng)度總和不能超過1000 字節(jié);
2. BLOB 和TEXT 類型的列只能創(chuàng)建前綴索引;
3. MySQL 目前不支持函數(shù)索引;
4. 使用不等于(!= 或者<>)的時(shí)候MySQL 無法使用索引;
5. 過濾字段使用了函數(shù)運(yùn)算后(如abs(column)),MySQL 無法使用索引;
6. Join 語句中Join 條件字段類型不一致的時(shí)候MySQL 無法使用索引;
7. 使用LIKE 操作的時(shí)候如果條件以通配符開始( '%abc...')MySQL 無法使用索引;
8. 使用非等值查詢的時(shí)候MySQL 無法使用Hash 索引;
MySQL 目前可以通過兩種算法來實(shí)現(xiàn)數(shù)據(jù)的排序操作:
1. 取出滿足過濾條件的用于排序條件的字段以及可以直接定位到行數(shù)據(jù)的行指針信息,在SortBuffer 中進(jìn)行實(shí)際的排序操作,然后利用排好序之后的數(shù)據(jù)根據(jù)行指針信息返回表中取得客戶端請(qǐng)求的其他字段的數(shù)據(jù),再返回給客戶端;
2. 根據(jù)過濾條件一次取出排序字段以及客戶端請(qǐng)求的所有其他字段的數(shù)據(jù),并將不需要排序的字段存放在一塊內(nèi)存區(qū)域中,然后在Sort Buffer 中將排序字段和行指針信息進(jìn)行排序,最后再利用排序后的行指針與存放在內(nèi)存區(qū)域中和其他字段一起的行指針信息進(jìn)行匹配合并結(jié)果集,再按照順序返回給客戶端.
?
MySQL Explain 功能中給我們展示的各種信息的解釋:
◆ ID:Query Optimizer 所選定的執(zhí)行計(jì)劃中查詢的序列號(hào);
◆ Select_type:所使用的查詢類型,主要有以下這幾種查詢類型
◇ DEPENDENT SUBQUERY:子查詢中內(nèi)層的第一個(gè)SELECT,依賴于外部查詢的結(jié)果集;
◇ DEPENDENT UNION:子查詢中的UNION,且為UNION 中從第二個(gè)SELECT 開始的后面所有SELECT,同樣依賴于外部查詢的結(jié)果集;
◇ PRIMARY:子查詢中的最外層查詢,注意并不是主鍵查詢;
◇ SIMPLE:除子查詢或者UNION 之外的其他查詢;
◇ SUBQUERY:子查詢內(nèi)層查詢的第一個(gè)SELECT,結(jié)果不依賴于外部查詢結(jié)果集;
◇ UNCACHEABLE SUBQUERY:結(jié)果集無法緩存的子查詢;
◇ UNION:UNION 語句中第二個(gè)SELECT 開始的后面所有SELECT,第一個(gè)SELECT 為PRIMARY
◇ UNION RESULT:UNION 中的合并結(jié)果;
◆ Table:顯示這一步所訪問的數(shù)據(jù)庫(kù)中的表的名稱;
◆ Type:告訴我們對(duì)表所使用的訪問方式,主要包含如下集中類型;
◇ all:全表掃描
◇ const:讀常量,且最多只會(huì)有一條記錄匹配,由于是常量,所以實(shí)際上只需要讀一次;
◇ eq_ref:最多只會(huì)有一條匹配結(jié)果,一般是通過主鍵或者唯一鍵索引來訪問;
◇ fulltext:
◇ index:全索引掃描;
◇ index_merge:查詢中同時(shí)使用兩個(gè)(或更多)索引,然后對(duì)索引結(jié)果進(jìn)行merge 之后再讀取表數(shù)據(jù);
◇ index_subquery:子查詢中的返回結(jié)果字段組合是一個(gè)索引(或索引組合),但不是一個(gè)主鍵或者唯一索引;
◇ rang:索引范圍掃描;
◇ ref:Join 語句中被驅(qū)動(dòng)表索引引用查詢;
◇ ref_or_null:與ref 的唯一區(qū)別就是在使用索引引用查詢之外再增加一個(gè)空值的查詢;
◇ system:系統(tǒng)表,表中只有一行數(shù)據(jù);
◇ unique_subquery:子查詢中的返回結(jié)果字段組合是主鍵或者唯一約束;
◆ Possible_keys:該查詢可以利用的索引. 如果沒有任何索引可以使用,就會(huì)顯示成null,這一項(xiàng)內(nèi)容對(duì)于優(yōu)化時(shí)候索引的調(diào)整非常重要;
◆ Key:MySQL Query Optimizer 從possible_keys 中所選擇使用的索引;
◆ Key_len:被選中使用索引的索引鍵長(zhǎng)度;
◆ Ref:列出是通過常量(const),還是某個(gè)表的某個(gè)字段(如果是join)來過濾(通過key)的;
◆ Rows:MySQL Query Optimizer 通過系統(tǒng)收集到的統(tǒng)計(jì)信息估算出來的結(jié)果集記錄條數(shù);
◆ Extra:查詢中每一步實(shí)現(xiàn)的額外細(xì)節(jié)信息,主要可能會(huì)是以下內(nèi)容:
◇ Distinct:查找distinct 值,所以當(dāng)mysql 找到了第一條匹配的結(jié)果后,將停止該值的查詢而轉(zhuǎn)為后面其他值的查詢;
◇ Full scan on NULL key:子查詢中的一種優(yōu)化方式,主要在遇到無法通過索引訪問null值的使用使用;
◇ Impossible WHERE noticed after reading const tables:MySQL Query Optimizer 通過收集到的統(tǒng)計(jì)信息判斷出不可能存在結(jié)果;
◇ No tables:Query 語句中使用FROM DUAL 或者不包含任何FROM 子句;
◇ Not exists:在某些左連接中MySQL Query Optimizer 所通過改變?cè)蠶uery 的組成而使用的優(yōu)化方法,可以部分減少數(shù)據(jù)訪問次數(shù);
◇ Range checked for each record (index map: N):通過MySQL 官方手冊(cè)的描述,當(dāng)MySQL Query Optimizer 沒有發(fā)現(xiàn)好的可以使用的索引的時(shí)候,如果發(fā)現(xiàn)如果來自前面的表的列值已知,可能部分索引可以使用.對(duì)前面的表的每個(gè)行組合,MySQL 檢查是否可以使用range 或index_merge 訪問方法來索取行.
◇ Select tables optimized away:當(dāng)我們使用某些聚合函數(shù)來訪問存在索引的某個(gè)字段的時(shí)候,MySQL Query Optimizer 會(huì)通過索引而直接一次定位到所需的數(shù)據(jù)行完成整個(gè)查詢.當(dāng)然,前提是在Query 中不能有GROUP BY 操作.如使用MIN()或者M(jìn)AX()的時(shí)
候;
◇ Using filesort:當(dāng)我們的Query 中包含ORDER BY 操作,而且無法利用索引完成排序操作的時(shí)候,MySQL Query Optimizer 不得不選擇相應(yīng)的排序算法來實(shí)現(xiàn).
◇ Using index:所需要的數(shù)據(jù)只需要在Index 即可全部獲得而不需要再到表中取數(shù)據(jù);
◇ Using index for group-by:數(shù)據(jù)訪問和Using index 一樣,所需數(shù)據(jù)只需要讀取索引即可,而當(dāng)Query 中使用了GROUP BY 或者DISTINCT 子句的時(shí)候,如果分組字段也在索引中,Extra 中的信息就會(huì)是Using index for group-by;
◇ Using temporary:當(dāng)MySQL 在某些操作中必須使用臨時(shí)表的時(shí)候,在Extra 信息中就會(huì)出現(xiàn)Using temporary .主要常見于GROUP BY 和ORDER BY 等操作中.
◇ Using where:如果我們不是讀取表的所有數(shù)據(jù),或者不是僅僅通過索引就可以獲取所有需要的數(shù)據(jù),則會(huì)出現(xiàn)Using where 信息;
◇ Using where with pushed condition:這是一個(gè)僅僅在NDBCluster 存儲(chǔ)引擎中才會(huì)出現(xiàn)的信息,而且還需要通過打開Condition Pushdown 優(yōu)化功能才可能會(huì)被使用.控制參數(shù)為engine_condition_pushdown .
?
什么是松散索引?
答:實(shí)際上就是當(dāng)MySQL 完全利用索引掃描來實(shí)現(xiàn)GROUP BY 的時(shí)候,并不需要掃描所有滿足條件的索引鍵即可完成操作得出結(jié)果.
要利用到松散索引掃描實(shí)現(xiàn)GROUP BY,需要至少滿足以下幾個(gè)條件:
◆ GROUP BY 條件字段必須在同一個(gè)索引中最前面的連續(xù)位置;
◆ 在使用GROUP BY 的同時(shí),只能使用MAX 和MIN 這兩個(gè)聚合函數(shù);
◆ 如果引用到了該索引中GROUP BY 條件之外的字段條件的時(shí)候,必須以常量形式存在;MYSQL教程
為什么松散索引掃描的效率會(huì)很高?
答:因?yàn)樵跊]有WHERE 子句,也就是必須經(jīng)過全索引掃描的時(shí)候, 松散索引掃描需要讀取的鍵值數(shù)量與分組的組數(shù)量一樣多,也就是說比實(shí)際存在的鍵值數(shù)目要少很多.而在WHERE 子句包含范圍判斷式或者等值表達(dá)式的時(shí)候, 松散索引掃描查找滿足范圍條件的每個(gè)組的第1 個(gè)關(guān)鍵字,并且再次讀取盡可能最少數(shù)量的關(guān)鍵字.
?
什么是緊湊索引?
答:緊湊索引掃描實(shí)現(xiàn)GROUP BY 和松散索引掃描的區(qū)別主要在于他需要在掃描索引的時(shí)候,讀取所有滿足條件的索引鍵,然后再根據(jù)讀取的數(shù)據(jù)來完成GROUP BY 操作得到相應(yīng)結(jié)果.MYSQL教程
MySQL 處理GROUP BY 的方式,有兩種如下優(yōu)化思路:
1. 盡可能讓MySQL 可以利用索引來完成GROUP BY 操作,當(dāng)然最好是松散索引掃描的方式最佳.在系統(tǒng)允許的情況下,我們可以通過調(diào)整索引或者調(diào)整Query 這兩種方式來達(dá)到目的;MYSQL教程
2. 當(dāng)無法使用索引完成GROUP BY 的時(shí)候,由于要使用到臨時(shí)表且需要filesort,所以我們必須要有足夠的sort_buffer_size 來供MySQL 排序的時(shí)候使用,而且盡量不要進(jìn)行大結(jié)果集的GROUPBY 操作,因?yàn)槿绻鱿到y(tǒng)設(shè)置的臨時(shí)表大小的時(shí)候會(huì)出現(xiàn)將臨時(shí)表數(shù)據(jù)copy 到磁盤上面再進(jìn)行操作,這時(shí)候的排序分組操作性能將是成數(shù)量級(jí)的下降;
?
DINSTINCT 其實(shí)和 GROUP BY 原理類似,同樣可以使用松散索引.
?
MySQL Schema 設(shè)計(jì)優(yōu)化小記:
1. 適度冗余
2. 大字段垂直分拆
3. 大表水平分拆
?
時(shí)間字段類型:timestamp 占用4個(gè)字節(jié),datetime,date占用8個(gè)字節(jié),但是timestamp只能用在1970年以后的記錄,datetime,date可用在1001年開始.
?
MySQL binlog日志優(yōu)化方案:MYSQL教程
Binlog 相關(guān)參數(shù)及優(yōu)化策略
我們首先看看Binlog 的相關(guān)參數(shù),通過執(zhí)行如下命令可以獲得關(guān)于Binlog 的相關(guān)參數(shù).當(dāng)然,其中也顯示出了“ innodb_locks_unsafe_for_binlog”這個(gè)Innodb 存儲(chǔ)引擎特有的與Binlog 相關(guān)的參數(shù):
mysql> show variables like '%binlog%';
+--------------------------------+------------+
| Variable_name | Value |
+--------------------------------+------------+
| binlog_cache_size | 1048576 |
| innodb_locks_unsafe_for_binlog | OFF |
| max_binlog_cache_size | 4294967295 |
| max_binlog_size | 1073741824 |
| sync_binlog | 0 |
+--------------------------------+------------+
“binlog_cache_size":在事務(wù)過程中容納二進(jìn)制日志SQL 語句的緩存大小.二進(jìn)制日志緩存是服務(wù)器支持事務(wù)存儲(chǔ)引擎并且服務(wù)器啟用了二進(jìn)制日志(―log-bin 選項(xiàng))的前提下為每個(gè)客戶端分配的內(nèi)存,注意,是每個(gè)Client 都可以分配設(shè)置大小的binlog cache 空間.如果讀者朋友的系統(tǒng)中經(jīng)常會(huì)出現(xiàn)多語句事務(wù)的華,可以嘗試增加該值的大小,以獲得更好的性能.當(dāng)然,我們可以通過MySQL 的以下兩個(gè)狀態(tài)變量來判斷當(dāng)前的binlog_cache_size 的狀況:Binlog_cache_use 和Binlog_cache_disk_use.“max_binlog_cache_size”:和"binlog_cache_size"相對(duì)應(yīng),但是所代表的是binlog 能夠使用的最大cache 內(nèi)存大小.當(dāng)我們執(zhí)行多語句事務(wù)的時(shí)候,max_binlog_cache_size 如果不夠大的話,系統(tǒng)可能會(huì)報(bào)出“ Multi-statement transaction required more than 'max_binlog_cache_size' bytes ofstorage”的錯(cuò)誤.
“max_binlog_size”:Binlog 日志最大值,一般來說設(shè)置為512M 或者1G,但不能超過1G.該大小并不能非常嚴(yán)格控制Binlog 大小,尤其是當(dāng)?shù)竭_(dá)Binlog 比較靠近尾部而又遇到一個(gè)較大事務(wù)的時(shí)候,系統(tǒng)為了保證事務(wù)的完整性,不可能做切換日志的動(dòng)作,只能將該事務(wù)的所有SQL 都記錄進(jìn)入當(dāng)前日志,直到該事務(wù)結(jié)束.這一點(diǎn)和Oracle 的Redo 日志有點(diǎn)不一樣,因?yàn)镺racle 的Redo 日志所記錄的是數(shù)據(jù)文件的物理位置的變化,而且里面同時(shí)記錄了Redo 和Undo 相關(guān)的信息,所以同一個(gè)事務(wù)是否在一個(gè)日志中對(duì)Oracle 來說并不關(guān)鍵.而MySQL 在Binlog 中所記錄的是數(shù)據(jù)庫(kù)邏輯變化信息,MySQL 稱之為Event,實(shí)際上就是帶來數(shù)據(jù)庫(kù)變化的DML 之類的Query 語句.“sync_binlog”:這個(gè)參數(shù)是對(duì)于MySQL 系統(tǒng)來說是至關(guān)重要的,他不僅影響到Binlog 對(duì)MySQL 所帶來的性能損耗,而且還影響到MySQL 中數(shù)據(jù)的完整性.對(duì)于“sync_binlog”參數(shù)的各種設(shè)置的說明如下:
● sync_binlog=0,當(dāng)事務(wù)提交之后,MySQL 不做fsync 之類的磁盤同步指令刷新binlog_cache 中的信息到磁盤,而讓Filesystem 自行決定什么時(shí)候來做同步,或者cache 滿了之后才同步到磁盤.
● sync_binlog=n,當(dāng)每進(jìn)行n 次事務(wù)提交之后,MySQL 將進(jìn)行一次fsync 之類的磁盤同步指令來將binlog_cache 中的數(shù)據(jù)強(qiáng)制寫入磁盤.在MySQL 中系統(tǒng)默認(rèn)的設(shè)置是sync_binlog=0,也就是不做任何強(qiáng)制性的磁盤刷新指令,這時(shí)候的性能是最好的,但是風(fēng)險(xiǎn)也是最大的.因?yàn)橐坏┫到y(tǒng)Crash,在binlog_cache 中的所有binlog 信息都會(huì)被丟失.而當(dāng)設(shè)置為“1”的時(shí)候,是最安全但是性能損耗最大的設(shè)置.因?yàn)楫?dāng)設(shè)置為1 的時(shí)候,即使系統(tǒng)Crash,也最多丟失binlog_cache 中未完成的一個(gè)事務(wù),對(duì)實(shí)際數(shù)據(jù)沒有任何實(shí)質(zhì)性影響.從以往經(jīng)驗(yàn)和相關(guān)測(cè)試來看,對(duì)于高并發(fā)事務(wù)的系統(tǒng)來說,“sync_binlog”設(shè)置為0 和設(shè)置為1 的系統(tǒng)寫入性能差距可能高達(dá)5 倍甚至更多.
?
MySQL QueryCache 負(fù)面影響:
a) Query 語句的hash 運(yùn)算以及hash 查找資源消耗.當(dāng)我們使用Query Cache 之后,每條SELECT類型的Query 在到達(dá)MySQL 之后,都需要進(jìn)行一個(gè)hash 運(yùn)算然后查找是否存在該Query 的Cache,雖然這個(gè)hash 運(yùn)算的算法可能已經(jīng)非常高效了,hash 查找的過程也已經(jīng)足夠的優(yōu)化了,對(duì)于一條Query 來說消耗的資源確實(shí)是非常非常的少,但是當(dāng)我們每秒都有上千甚至幾千條Query 的時(shí)候,我們就不能對(duì)產(chǎn)生的CPU 的消耗完全忽視了.
b) Query Cache 的失效問題.如果我們的表變更比較頻繁,則會(huì)造成Query Cache 的失效率非常高.這里的表變更不僅僅指表中數(shù)據(jù)的變更,還包括結(jié)構(gòu)或者索引等的任何變更.也就是說我們每次緩存到Query Cache 中的Cache 數(shù)據(jù)可能在剛存入后很快就會(huì)因?yàn)楸碇械臄?shù)據(jù)被改變而被清除,然后新的相同Query 進(jìn)來之后無法使用到之前的Cache.
c) Query Cache 中緩存的是Result Set ,而不是數(shù)據(jù)頁,也就是說,存在同一條記錄被Cache 多次的可能性存在.從而造成內(nèi)存資源的過渡消耗.當(dāng)然,可能有人會(huì)說我們可以限定QueryCache 的大小啊.是的,我們確實(shí)可以限定Query Cache 的大小,但是這樣,Query Cache 就很容易造成因?yàn)閮?nèi)存不足而被換出,造成命中率的下降.
?
在短連接的應(yīng)用系統(tǒng)中,thread_cache_size 的值應(yīng)該設(shè)置的相對(duì)大一些,不應(yīng)該小于應(yīng)用系統(tǒng)對(duì)數(shù)據(jù)庫(kù)的實(shí)際并發(fā)請(qǐng)求數(shù).
?
通過系統(tǒng)設(shè)置和當(dāng)前狀態(tài)的分析,我們可以發(fā)現(xiàn),thread_cache_size 的設(shè)置已經(jīng)足夠了,甚至還遠(yuǎn)大于系統(tǒng)的需要.所以我們可以適當(dāng)減少thread_cache_size 的設(shè)置,比如設(shè)置為8 或者16.根據(jù)Connections 和Threads_created 這兩個(gè)系統(tǒng)狀態(tài)值,我們還可以計(jì)算出系統(tǒng)新建連接連接的ThreadCache 命中率,也就是通過Thread Cache 池中取得連接線程的次數(shù)與系統(tǒng)接收的總連接次數(shù)的比率,如下:
Threads_Cache_Hit = (Connections - Threads_created) / Connections * 100%
一般來說,當(dāng)系統(tǒng)穩(wěn)定運(yùn)行一段時(shí)間之后,我們的Thread Cache 命中率應(yīng)該保持在90%左右甚至更高的比率才算正常.可以看出上面環(huán)境中的Thread Cache 命中比率基本還算是正常的.
?
如何查看MySQL打開Table的數(shù)量:
mysql> show status like 'open_tables';
+---------------+-------+
| Variable_name | Value |
+---------------+-------+
| Open_tables | 6 |
+---------------+-------+
?
MySQL buffer注意事項(xiàng)
join_buffer_size 和 sort_buffer_size 是針對(duì)的每個(gè)線程的buffer大小而言的,而不是整個(gè)系統(tǒng)共享的Buffer.
?
假設(shè)是一臺(tái)單獨(dú)給MySQL 使用的主機(jī),物理內(nèi)存總大小為8G,MySQL 最大連接數(shù)為500,同時(shí)還使用了MyISAM 存儲(chǔ)引擎,這時(shí)候我們的整體內(nèi)存該如何分配呢?
內(nèi)存分配為如下幾大部分:
a) 系統(tǒng)使用,假設(shè)預(yù)留800M;
b) 線程獨(dú)享,約2GB = 500 * (1MB + 1MB + 1MB + 512KB + 512KB),組成大概如下:
sort_buffer_size:1MB
join_buffer_size:1MB
read_buffer_size:1MB
read_rnd_buffer_size:512KB
thread_statck:512KB
c) MyISAM Key Cache,假設(shè)大概為1.5GB;
d) Innodb Buffer Pool 最大可用量:8GB - 800MB - 2GB - 1.5GB = 3.7GB;MYSQL教程
轉(zhuǎn)載請(qǐng)注明本頁網(wǎng)址:
http://www.fzlkiss.com/jiaocheng/5999.html
同類教程排行
- Mysql實(shí)例mysql報(bào)錯(cuò):Deadl
- MYSQL數(shù)據(jù)庫(kù)mysql導(dǎo)入sql文件
- MYSQL的UTF8MB4編碼排序要用u
- MYSQL教程mysql自定義split
- 如何打造MySQL高可用平臺(tái)
- MYSQL創(chuàng)建表出錯(cuò)Tablespace
- Mysql必讀MySQL中CLIENT_
- MYSQL數(shù)據(jù)庫(kù)mysql常用字典表(完
- Mysql應(yīng)用MySql的Communi
- Mysql入門解決MySQL Sendi
- Mysql必讀關(guān)于skip_name_r
- MYSQL數(shù)據(jù)庫(kù)MySQL實(shí)現(xiàn)兩張表數(shù)據(jù)
- Mysql實(shí)例使用dreamhost空間
- MYSQL數(shù)據(jù)庫(kù)mysql 查詢表中平均
- MYSQL教程mysql 跨表查詢、更新
