mySQL集群
《mySQL集群》要點:
本文介紹了mySQL集群,希望對您有用。如果有疑問,可以聯(lián)系我們。
mySQL集群(cluster)
在這一章為了不浪費讀者的寶貴時間,我只會列出mySQL集群的幾種比較方案,目前有一些第三方提供的mySQL集群方案還是不錯的選擇.
MySQL的cluster方案有很多官方和第三方的選擇,選擇多就是一種懊惱,因此,我們考慮MySQL數(shù)據(jù)庫滿足下三點需求并來考察市面上可行的解決方案:
高可用性:主服務(wù)器故障后可自動切換到后備服務(wù)器可伸縮性:可方便通過腳本增加DB服務(wù)器負載均衡:支持手動把某公司的數(shù)據(jù)哀求切換到另外的服務(wù)器,可配置哪些公司的數(shù)據(jù)服務(wù)訪問哪個服務(wù)器
這是我列出的時下市面上比較流行的幾種mySQL集群方案中一些核心功能的比較,供參考:
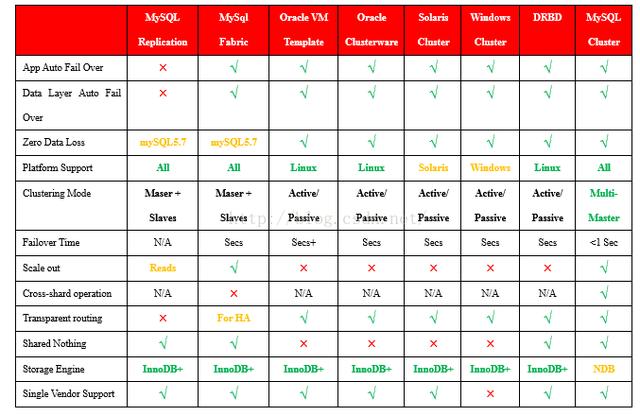
推薦第三方mySQL集群方案
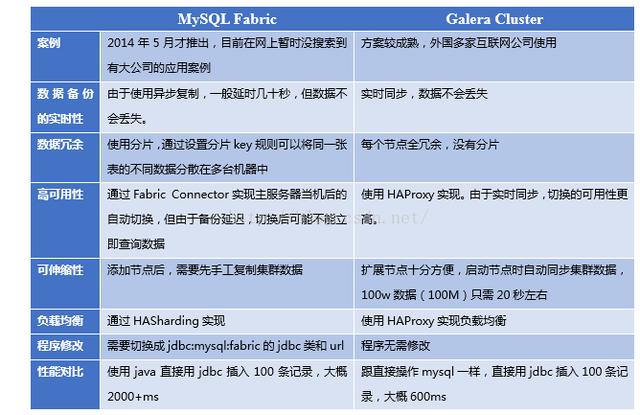
綜合比較下來,筆者推薦采用MySQL Fabric和MySQL Cluster方案,以及另外一種較成熟的集群方案Galera Cluster.
幾種mySQL集群方案的比較
MySQLCluster
MySQL Cluster 是MySQL 官方集群部署方案,它的歷史較久.支持通過自動分片支持讀寫擴展,通過實時備份冗余數(shù)據(jù),是可用性最高的方案,聲稱可做到99.999%的可用性.
架構(gòu)及實現(xiàn)原理:
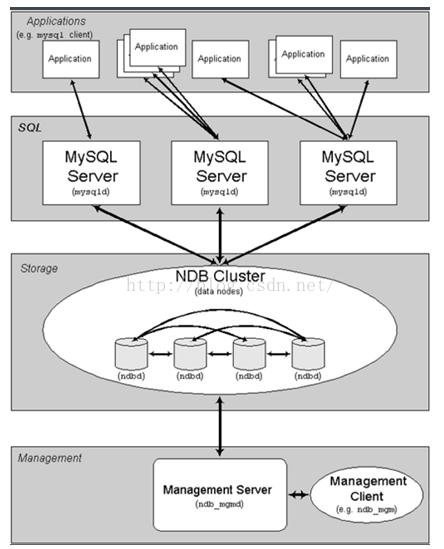
mySQL cluster主要由三種類型的服務(wù)組成:
NDB Management Server:管理服務(wù)器主要用于管理cluster中的其他類型節(jié)點(Data Node和SQL Node),通過它可以配置Node信息,啟動和停止Node. SQL Node:在MySQL Cluster中,一個SQL Node就是一個使用NDB引擎的mysql server進程,用于供外部應(yīng)用提供集群數(shù)據(jù)的拜訪入口.Data Node:用于存儲集群數(shù)據(jù);系統(tǒng)會盡量將數(shù)據(jù)放在內(nèi)存中.
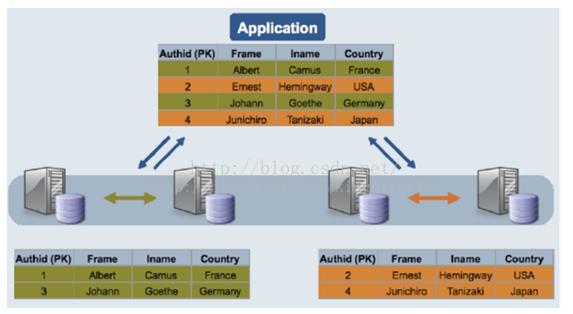
缺點及限制:
對需要進行分片的表需要修改引擎Innodb為NDB,不需要分片的可以不修改.NDB的事務(wù)隔離級別只支持Read Committed,即一個事務(wù)在提交前,查詢不到在事務(wù)內(nèi)所做的修改;而Innodb支持所有的事務(wù)隔離級別,默認(rèn)使用Repeatable Read,不存在這個問題.外鍵支持:雖然最新的Cluster版本已經(jīng)支持外鍵,但性能有問題(因為外鍵所關(guān)聯(lián)的記錄可能在別的分片節(jié)點中),所以建議去掉所有外鍵.Data Node節(jié)點數(shù)據(jù)會被盡量放在內(nèi)存中,對內(nèi)存要求大. 數(shù)據(jù)庫系統(tǒng)提供了四種事務(wù)隔離級別:
Serializable(串行化):一個事務(wù)在執(zhí)行過程中完全看不到其他事務(wù)對數(shù)據(jù)庫所做的更新(事務(wù)執(zhí)行的時候不允許別的事務(wù)并發(fā)執(zhí)行.事務(wù)串行化執(zhí)行,事務(wù)只能一個接著一個地執(zhí)行,而不能并發(fā)執(zhí)行.).Repeatable Read(可重復(fù)讀):一個事務(wù)在執(zhí)行過程中可以看到其他事務(wù)已經(jīng)提交的新插入的記錄,但是不能看到其他其他事務(wù)對已有記錄的更新.Read Commited(讀已提交數(shù)據(jù)):一個事務(wù)在執(zhí)行過程中可以看到其他事務(wù)已經(jīng)提交的新插入的記錄,而且能看到其他事務(wù)已經(jīng)提交的對已有記錄的更新.Read Uncommitted(讀未提交數(shù)據(jù)):一個事務(wù)在執(zhí)行過程中可以看到其他事務(wù)沒有提交的新插入的記錄,而且能看到其他事務(wù)沒有提交的對已有記錄的更新.
MySQL Fabric
為了實現(xiàn)和方便管理MySQL 分片以及實現(xiàn)高可用部署,Oracle在2014年5月推出了一套為各方寄予厚望的MySQL產(chǎn)品 -- MySQL Fabric, 用來管理MySQL 服務(wù),提供擴展性和容易使用的系統(tǒng),Fabric當(dāng)前實現(xiàn)了兩個特性:高可用和使用數(shù)據(jù)分片實現(xiàn)可擴展性和負載均衡,這兩個特性能單獨使用或結(jié)合使用.
MySQL Fabric 使用了一系列的python腳本實現(xiàn).
應(yīng)用案例:由于該方案在去年才推出,目前在網(wǎng)上暫時沒搜索到有大公司的應(yīng)用案例.
架構(gòu)及實現(xiàn)原理:
Fabric支持實現(xiàn)高可用性的架構(gòu)圖如下
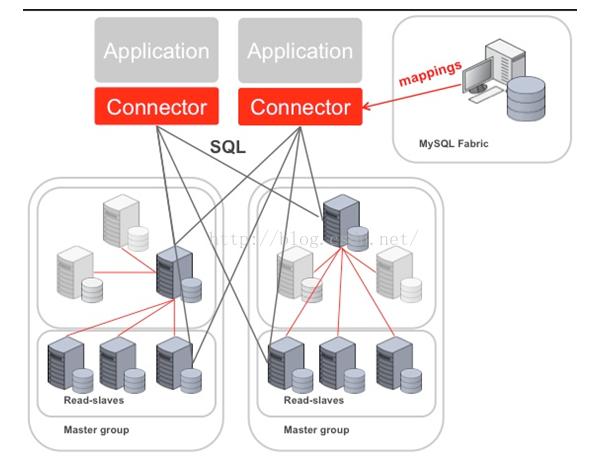
Fabric使用HA組實現(xiàn)高可用性,其中一臺是主服務(wù)器,其他是備份服務(wù)器, 備份服務(wù)器通過同步復(fù)制實現(xiàn)數(shù)據(jù)冗余.應(yīng)用程序使用特定的驅(qū)動,連接到Fabric 的Connector組件,當(dāng)主服務(wù)器發(fā)生故障后,Connector自動升級其中一個備份服務(wù)器為主服務(wù)器,應(yīng)用程序無需修改.
Fabric支持可擴展性及負載均衡的架構(gòu)如下:
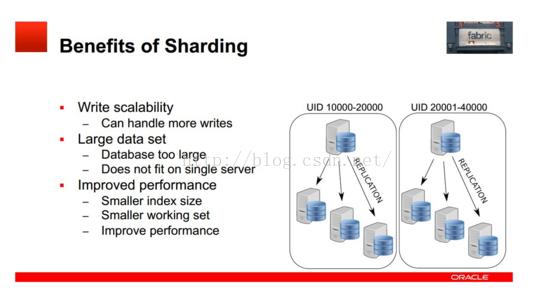
使用多個HA 組實現(xiàn)分片,每個組之間分擔(dān)不同的分片數(shù)據(jù)(組內(nèi)的數(shù)據(jù)是冗余的,這個在高可用性中已經(jīng)提到)
應(yīng)用程序只需向connector發(fā)送query和insert等語句,Connector通過MasterGroup自動分配這些數(shù)據(jù)到各個組,或從各個組中組合符合條件的數(shù)據(jù),返回給應(yīng)用程序.
缺點及限制:
影響比較大的兩個限制是:
自增長鍵不能作為分片的鍵;事務(wù)及查詢只支持在同一個分片內(nèi),事務(wù)中更新的數(shù)據(jù)不能跨分片,查詢語句返回的數(shù)據(jù)也不能跨分片.
分片:如何支持可擴展性和負載均衡
當(dāng)一臺機器或一個組承受不了服務(wù)壓力后,可以添加服務(wù)器分?jǐn)傋x寫壓力,通過Fabirc的分片功能可以將某些表中數(shù)據(jù)分散存儲到不同服務(wù)器.我們可以設(shè)定分配數(shù)據(jù)存儲的規(guī)則,通過在表中設(shè)置分片key設(shè)置分配的規(guī)則.另外,有些表的數(shù)據(jù)可能并不需要分片存儲,需要將整張表存儲在同一個服務(wù)器中,可以將設(shè)置一個全局組(Global Group)用于存儲這些數(shù)據(jù),存儲到全局組的數(shù)據(jù)會自動拷貝到其他所有的分片組中.
Galera Cluster
Galera Cluster號稱是世界上最先進的開源數(shù)據(jù)庫集群方案.

主要優(yōu)點及特性:
真正的多主服務(wù)模式:多個服務(wù)能同時被讀寫,不像Fabric那樣某些服務(wù)只能作備份用同步復(fù)制:無延遲復(fù)制,不會產(chǎn)生數(shù)據(jù)丟失熱備用:當(dāng)某臺服務(wù)器當(dāng)機后,備用服務(wù)器會自動接管,不會產(chǎn)生任何當(dāng)機時間自動擴展節(jié)點:新增服務(wù)器時,不需手工復(fù)制數(shù)據(jù)庫到新的節(jié)點支持InnoDB引擎對應(yīng)用程序透明:應(yīng)用程序不需作修改.
架構(gòu)及實現(xiàn)原理:
首先,我們看看傳統(tǒng)的基于mysql Replication(復(fù)制)的架構(gòu)圖:
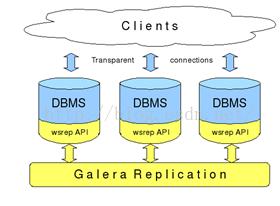
Replication方式是通過啟動復(fù)制線程從主服務(wù)器上拷貝更新日志,讓后傳送到備份服務(wù)器上執(zhí)行,這種方式存在事務(wù)丟失及同步不及時的風(fēng)險.Fabric以及傳統(tǒng)的主從復(fù)制都是使用這種實現(xiàn)方式.
而Galera則采用以下架構(gòu)保證事務(wù)在所有機器的一致性.
客戶端通過Galera Load Balancer拜訪數(shù)據(jù)庫,提交的每個事務(wù)都會通過wsrep API 在所有服務(wù)器中執(zhí)行,要不所有服務(wù)器都執(zhí)行成功,要不就所有都回滾,保證所有服務(wù)的數(shù)據(jù)一致性,而且所有服務(wù)器同步實時更新.
缺點及限制:
由于同一個事務(wù)需要在集群的多臺機器上執(zhí)行,因此網(wǎng)絡(luò)傳輸及并發(fā)執(zhí)行會導(dǎo)致性能上有一定的消耗.所有機器上都存儲著相同的數(shù)據(jù),全冗余.若一臺機器既作為主服務(wù)器,又作為備份服務(wù)器,出現(xiàn)樂觀鎖導(dǎo)致rollback的概率會增大,編寫程序時要小心.不支持的SQL:LOCK / UNLOCK TABLES / GET_LOCK(), RELEASE_LOCK()…不支持XA Transaction
目前基于Galera Cluster的實現(xiàn)方案有三種:Galera Cluster for MySQL、Percona XtraDB Cluster、MariaDB Galera Cluster.
我們采用較成熟、應(yīng)用案例較多的Percona XtraDB Cluster.
應(yīng)用案例:
超過2000多家外國企業(yè)使用

Fabric對比Galera
mySQL連接數(shù)優(yōu)化
我們?nèi)绻?jīng)常遇見MySQL:ERROR1040:Too many connections的情況,一種情況是拜訪量確實很高,MySQL服務(wù)器扛不住了,這個時候就要考慮增加從服務(wù)器分散讀壓力,從架構(gòu)層面.另外一種情況是MySQL配置文件中max_connections的值過小.來看一個例子.
mysql> show variables like 'max_connections';
+-----------------+-------+
|
Variable_name | Value |
+-----------------+-------+
|
max_connections | 800 |
+-----------------+-------+
#### 這臺服務(wù)器最大連接數(shù)是256,然后查詢一下該服務(wù)器響應(yīng)的最大連接數(shù);
mysql> show global status like 'Max_used_connections';
+----------------------+-------+
|
Variable_name | Value |
+----------------------+-------+
|
Max_used_connections | 245 |
+----------------------+-------+
#### MySQL服務(wù)器過去的最大連接數(shù)是245,沒有達到服務(wù)器連接數(shù)的上線800,不會出現(xiàn)1040錯誤.
#### Max_used_connections /max_connections * 100% = 85%
#### 最大連接數(shù)占上限連接數(shù)的85%左右,如果發(fā)現(xiàn)比例在10%以下,則說明MySQL服務(wù)器連接數(shù)的上限設(shè)置得過高了.
key_buffer_size
key_buffer_size是設(shè)置MyISAM表索引緩存空間的大小,此參數(shù)對MyISAM表性能影響最大.下面是一臺MyISAM為主要存儲引擎服務(wù)器的配置:
mysql> show variables like 'key_buffer_size';
+-----------------+-----------+
|
Variable_name | Value |
+-----------------+-----------+
|
key_buffer_size | 536870912 |
+-----------------+-----------+
#### 從上面可以看出,分配了512MB內(nèi)存給key_buffer_size.再來看key_buffer_size的使用情況:
mysql> show global status like 'key_read%';
+-------------------+--------------+
|
Variable_name | Value |
+-------------------+-------+
|
Key_read_requests | 27813678766 |
|
Key_reads | 6798830|
+-------------------+--------------+
一共有27813678766個索引讀取哀求,有6798830個哀求在內(nèi)存中沒有找到,直接從硬盤讀取索引.
key_cache_miss_rate = key_reads / key_read_requests * 100%
比如上面的數(shù)據(jù),key_cache_miss_rate為0.0244%,4000%個索引讀取哀求才有一個直接讀硬盤,效果已經(jīng)很好了,key_cache_miss_rate在0.1%以下都很好,如果key_cache_miss_rate在0.01%以下的話,則說明key_buffer_size分配得過多,可以適當(dāng)減少.
mySQL的臨時表
當(dāng)執(zhí)行語句時,關(guān)于已經(jīng)被創(chuàng)建了隱含臨時表的數(shù)量,我們可以用如下命令查詢其具體情況:
mysql> show global status like 'created_tmp%';
+-------------------------+----------+
|
Variable_name | Value |
+-------------------------+----------+
|
Created_tmp_disk_tables | 21119 |
|
Created_tmp_files | 6 |
|
Created_tmp_tables | 17715532 |
+-------------------------+----------+
#### MySQL服務(wù)器對臨時表的配置:
mysql> show variables where Variable_name in ('tmp_table_size','max_heap_table_size');
+---------------------+---------+
|
Variable_name | Value |
+---------------------+---------+
|
max_heap_table_size | 2097152 |
|
tmp_table_size | 2097152 |
+---------------------+---------+
每次創(chuàng)建臨時表時,Created_tmp_table都會增加,如果磁盤上創(chuàng)建臨時表,Created_tmp_disk_tables也會增加.Created_tmp_files表示MySQL服務(wù)創(chuàng)建的臨時文件數(shù),比較理想的配置是:
Created_tmp_disk_tables / Created_tmp_files *100% <= 25%
比如上面的服務(wù)器:
Created_tmp_disk_tables / Created_tmp_files *100% =1.20%,這個值就很棒了.
mySQL打開表的情況
Open_tables表示打開表的數(shù)量,Opened_tables表示打開過的表數(shù)量,我們可以用如下命令查看其具體情況:
mysql> show global status like 'open%tables%';
+---------------+-------+
|
Variable_name | Value |
+---------------+-------+
|
Open_tables | 351 |
|
Opened_tables | 1455 |
#### 查詢下服務(wù)器table_open_cache;
mysql> show variables like 'table_open_cache';
+------------------+-------+
|
Variable_name | Value |
+------------------+-------+
|
table_open_cache | 2048 |
+------------------+-------+
如果Opened_tables數(shù)量過大,說明配置中table_open_cache的值可能太小.
比較合適的值為:
open_tables / opened_tables* 100% > = 85%
open_tables / table_open_cache* 100% < = 95%
mySQL的進程使用情況
如果我們在MySQL服務(wù)器的配置文件中設(shè)置了thread_cache_size,當(dāng)客戶端斷開時,服務(wù)器處理此客戶哀求的線程將會緩存起來以響應(yīng)一下客戶而不是銷毀(前提是緩存數(shù)未達上線)Thread_created表示創(chuàng)建過的線程數(shù),我們可以用如下命令查看:
mysql> show global status like 'thread%';
+-------------------+-------+
|
Variable_name | Value |
+-------------------+-------+
|
Threads_cached | 40|
|
Threads_connected | 1 |
|
Threads_created | 330 |
|
Threads_running | 1 |
+-------------------+-------+
#### 查詢服務(wù)器thread_cache_size配置如下:
mysql> show variables like 'thread_cache_size';
+-------------------+-------+
|
Variable_name | Value |
+-------------------+-------+
|
thread_cache_size | 100 |
+-------------------+-------+
如果發(fā)現(xiàn)Threads_created的值過大的話,表明MySQL服務(wù)器一直在創(chuàng)建線程,這也是比較耗費資源的,可以適當(dāng)增大配置文件中thread_cache_size的值.
查詢緩存(query cache)
它主要涉及兩個參數(shù),query_cache_size是設(shè)置MySQL的Query Cache大小,query_cache_type是設(shè)置使用查詢緩存的類型,我們可以用如下命令查看其具體情況:
mysql> show global status like 'qcache%';
+-------------------------+-----------+
|
Variable_name | Value |
+-------------------------+-----------+
|
Qcache_free_blocks | 22756 |
|
Qcache_free_memory | 76764704 |
|
Qcache_hits | 213028692 |
|
Qcache_inserts | 208894227 |
|
Qcache_lowmem_prunes | 4010916 |
|
Qcache_not_cached | 13385031 |
|
Qcache_queries_in_cache | 43560 |
|
Qcache_total_blocks | 111212 |
+-------------------------+-----------+
MySQL查詢緩存變量的相關(guān)解釋如下:
Qcache_free_blocks: 緩存中相領(lǐng)內(nèi)存快的個數(shù).數(shù)目大說明可能有碎片.flush query cache會對緩存中的碎片進行整理,從而得到一個空間塊.Qcache_free_memory:緩存中的空閑空間.Qcache_hits:多少次命中.通過這個參數(shù)可以查看到Query Cache的基本效果.Qcache_inserts:插入次數(shù),沒插入一次查詢時就增加1.命中次數(shù)除以插入次數(shù)就是命中比率.Qcache_lowmem_prunes:多少條Query因為內(nèi)存不足而被清楚出Query Cache.通過Qcache_lowmem_prunes和Query_free_memory相互結(jié)合,能 夠更清楚地了解到系統(tǒng)中Query Cache的內(nèi)存大小是否真的足夠,是否非常頻繁地出現(xiàn)因為內(nèi)存不足而有Query被換出的情況. Qcache_not_cached:不適合進行緩存的查詢數(shù)量,通常是由于這些查詢不是select語句或用了now()之類的函數(shù).Qcache_queries_in_cache:當(dāng)前緩存的查詢和響應(yīng)數(shù)量.Qcache_total_blocks:緩存中塊的數(shù)量.
query_cache的配置命令:
mysql> show variables like 'query_cache%';
+------------------------------+---------+
|
Variable_name | Value |
+------------------------------+---------+
|
query_cache_limit | 1048576 |
|
query_cache_min_res_unit | 2048 |
|
query_cache_size | 2097152 |
|
query_cache_type | ON |
|
query_cache_wlock_invalidate | OFF |
+------------------------------+---------+
字段解釋如下:
query_cache_limit:超過此大小的查詢將不緩存.query_cache_min_res_unit:緩存塊的最小值.query_cache_size:查詢緩存大小.query_cache_type:緩存類型,決定緩存什么樣的查詢,示例中表示不緩存select sql_no_cache查詢.query_cache_wlock_invalidat:表示當(dāng)有其他客戶端正在對MyISAM表進行寫操作,讀哀求是要等WRITE LOCK釋放資源后再查詢還是允許直接從Query Cache中讀取結(jié)果,默認(rèn)為OFF(可以直接從Query Cache中取得結(jié)果.)query_cache_min_res_unit的配置是一柄雙刃劍,默認(rèn)是4KB,設(shè)置值大對大數(shù)據(jù)查詢有好處,但如果你的查詢都是小數(shù)據(jù)查詢,就容易造成內(nèi)存碎片和浪費.查詢緩存碎片率 = Qcache_free_blocks /Qcache_total_blocks * 100%如果查詢碎片率超過20%,可以用 flush query cache 整理緩存碎片,或者試試減少query_cache_min_res_unit,如果你查詢都是小數(shù)據(jù)庫的話.查詢緩存利用率 = (Qcache_free_size – Qcache_free_memory)/query_cache_size * 100% .查詢緩存利用率在25%一下的話說明query_cache_size設(shè)置得過大,可適當(dāng)減少;查詢緩存利用率在80%以上而且Qcache_lowmem_prunes > 50的話則說明query_cache_size可能有點小,不然就是碎片太多.查詢命中率 = (Qcache_hits - Qcache_insert)/Qcache)hits * 100%,比如説:服務(wù)器中的查詢緩存碎片率等于20%左右,查詢緩存利用率在50%,查詢命中率在2%,說明命中率很差,可能寫操作比較頻繁,而且可能有些碎片.
mySQL排序使用情況
它表示系統(tǒng)中對數(shù)據(jù)進行排序時所用的Buffer,我們可以用如下命令查看:
mysql> show global status like 'sort%';
+-------------------+----------+
|
Variable_name | Value |
+-------------------+----------+
|
Sort_merge_passes | 10 |
|
Sort_range | 37431240 |
|
Sort_rows | 6738691532 |
|
Sort_scan | 1823485 |
+-------------------+----------+
Sort_merge_passes包含如下步驟:MySQL首先會嘗試在內(nèi)存中做排序,使用的內(nèi)存大小由系統(tǒng)變量sort_buffer_size來決定,如果它不夠大則把所有的記錄都讀在內(nèi)存中,而MySQL則會把每次在內(nèi)存中排序的結(jié)果存到臨時文件中,等MySQL找到所有記錄之后,再把臨時文件中的記錄做一次排序.這次再排序就會增加sort_merge_passes.實際上,MySQL會用另外一個臨時文件來存儲再次排序的結(jié)果,所以我們通常會看sort_merge_passes增加的數(shù)值是建臨時文件數(shù)的兩倍.因為用到了臨時文件,所以速度可能會比較慢,增大sort_buffer_size會減少sort_merge_passes和創(chuàng)建臨時文件的次數(shù),但盲目地增大sort_buffer_size并不一定能提高速度.
《mySQL集群》是否對您有啟發(fā),歡迎查看更多與《mySQL集群》相關(guān)教程,學(xué)精學(xué)透。維易PHP學(xué)院為您提供精彩教程。
轉(zhuǎn)載請注明本頁網(wǎng)址:
http://www.fzlkiss.com/jiaocheng/7130.html
同類教程排行
- Mysql實例mysql報錯:Deadl
- MYSQL數(shù)據(jù)庫mysql導(dǎo)入sql文件
- MYSQL的UTF8MB4編碼排序要用u
- MYSQL教程mysql自定義split
- 如何打造MySQL高可用平臺
- MYSQL創(chuàng)建表出錯Tablespace
- Mysql必讀MySQL中CLIENT_
- MYSQL數(shù)據(jù)庫mysql常用字典表(完
- Mysql應(yīng)用MySql的Communi
- Mysql入門解決MySQL Sendi
- Mysql必讀關(guān)于skip_name_r
- MYSQL數(shù)據(jù)庫MySQL實現(xiàn)兩張表數(shù)據(jù)
- Mysql實例使用dreamhost空間
- MYSQL數(shù)據(jù)庫mysql 查詢表中平均
- MYSQL教程mysql 跨表查詢、更新
