SQL從技巧、案例和工具入手,詳解性能優(yōu)化怎么做
《SQL從技巧、案例和工具入手,詳解性能優(yōu)化怎么做》要點(diǎn):
本文介紹了SQL從技巧、案例和工具入手,詳解性能優(yōu)化怎么做,希望對(duì)您有用。如果有疑問,可以聯(lián)系我們。
作者介紹
顏圣杰,.NET平臺(tái)軟件工程師,對(duì)DDD領(lǐng)域驅(qū)動(dòng)設(shè)計(jì)感興趣,目前在研究ABP框架,熱愛寫作與分享.
最近一段時(shí)間系統(tǒng)新版本要發(fā)布,在beta客戶測(cè)試期間,暴露了很多問題,除了一些業(yè)務(wù)和異常問題外,其它都集中在性能上.有幸接觸到這些性能調(diào)優(yōu)的機(jī)會(huì),這里跟大家歸納交流一下.
性能優(yōu)化是一個(gè)老生常談的問題了,典型的性能問題如頁(yè)面響應(yīng)慢、接口超時(shí),服務(wù)器負(fù)載高、并發(fā)數(shù)低,數(shù)據(jù)庫(kù)頻繁死鎖等.而造成性能問題又有很多種,比如磁盤I/O、內(nèi)存、網(wǎng)絡(luò)、算法、大數(shù)據(jù)量等.我們可以大致把性能問題分為四個(gè)層次:代碼層次、數(shù)據(jù)庫(kù)層次、算法層次、架構(gòu)層次.
下面我會(huì)結(jié)合實(shí)際性能優(yōu)化案例,和大家分享下性能調(diào)優(yōu)的工具、方法和技巧.
先說(shuō)心態(tài)
說(shuō)到性能問題,你可能首先就想到的是麻煩或者頭大,因?yàn)橐话阈阅軉栴}都比較緊急,輕則影響客戶體驗(yàn),重則宕機(jī)導(dǎo)致財(cái)務(wù)損失,而且性能問題比較隱蔽,不易發(fā)現(xiàn).因此一時(shí)間無(wú)從下手,而這時(shí)我們就很容易從心底開始去排斥它,不愿接這燙手的山芋.
恰巧,性能調(diào)優(yōu)也是體現(xiàn)程序員水平的一個(gè)重要指標(biāo).
因?yàn)樘幚鞡UG、崩潰、調(diào)優(yōu)、入侵等突發(fā)事件比編程本身更能體現(xiàn)平庸程序員與理想程序員的差距.當(dāng)面對(duì)一個(gè)未知的問題時(shí),如何定位復(fù)雜條件下的核心問題、如何抽絲剝繭地分析問題的潛在原因、如何排除干擾還原一個(gè)最小的可驗(yàn)證場(chǎng)景、如何抓住關(guān)鍵數(shù)據(jù)驗(yàn)證自己的猜測(cè)與實(shí)驗(yàn),都是體現(xiàn)程序員思考力的最好場(chǎng)景.是的,在衡量理想程序員的標(biāo)準(zhǔn)上,思考力比經(jīng)驗(yàn)更加重要.
所以,若你不甘平庸,請(qǐng)擁抱性能調(diào)優(yōu)的每一個(gè)機(jī)會(huì).當(dāng)你擁有一個(gè)正確的心態(tài),你所面對(duì)的性能問題就已經(jīng)解決了一半.
再說(shuō)技巧
拿到一個(gè)性能問題,不要忙著先上工具,先了解問題出現(xiàn)的背景,問題的嚴(yán)重程度.然后大致根據(jù)自己的經(jīng)驗(yàn)積累作出預(yù)估.比如客戶來(lái)了個(gè)性能問題說(shuō)系統(tǒng)宕機(jī)了,已經(jīng)造成資金損失了.這種涉及到錢的問題,大家都比較敏感,根據(jù)自己的Level,決定是否要接這個(gè)鍋.這不是逃避,而是自知之明.
了解問題背景后,下一步就來(lái)嘗試問題重現(xiàn).如果在測(cè)試環(huán)境能夠重現(xiàn),那這種問題會(huì)很好跟蹤分析.如果問題不能穩(wěn)定重現(xiàn)或僅能在生產(chǎn)環(huán)境重現(xiàn),那就相對(duì)比較棘手,這時(shí)要立刻收集現(xiàn)場(chǎng)證據(jù),包括但不限于抓dump、收集應(yīng)用程序以及系統(tǒng)日志、關(guān)注CPU內(nèi)存情況、數(shù)據(jù)庫(kù)備份等,之后不妨再嘗試重現(xiàn),比如恢復(fù)客戶數(shù)據(jù)庫(kù)到測(cè)試環(huán)境重現(xiàn).
不管問題能否重現(xiàn),再下一步,我們要大致對(duì)問題進(jìn)行分類,是代碼層次的業(yè)務(wù)邏輯問題還是數(shù)據(jù)庫(kù)層次的操作耗時(shí)問題,又或是系統(tǒng)架構(gòu)的吞吐量問題.那如何確定呢?而我傾向于先從數(shù)據(jù)庫(kù)動(dòng)手.我的習(xí)慣做法是,使用數(shù)據(jù)庫(kù)監(jiān)控工具,先跟蹤下SQL耗時(shí)情況.如果監(jiān)控到耗時(shí)較長(zhǎng)的SQL語(yǔ)句,那基本上就是數(shù)據(jù)庫(kù)層次的問題,否則就是代碼層次.若為代碼層次,再研究完代碼后,再細(xì)化為算法或架構(gòu)層次問題.
確定問題種類后,是時(shí)候上工具來(lái)精準(zhǔn)定位問題點(diǎn)了:
SQL耗時(shí)問題,推薦使用免費(fèi)的Plan Explorer分析執(zhí)行計(jì)劃.
代碼問題定位,優(yōu)先推薦使用VS自帶的Performance Analysis,其次是RedGate的性能分析套件.NET Developer Bundle;然后還有Jet Brains的dotTrace -- .NET performance profiler,dotMemory-- .NET memory profiler;再然后就是反人類的Windbg等等.
精準(zhǔn)定位問題點(diǎn)后,就是著手優(yōu)化了.相信到這一步,就是優(yōu)化策略的選擇了,這里就不展開了.
優(yōu)化后,最后當(dāng)然要進(jìn)行測(cè)試了,畢竟優(yōu)化了多少,我們也要做到心里有譜才行.
啰啰嗦嗦有點(diǎn)多,下面直接上案例.
案例分享
這里分享下我針對(duì)代碼層面、數(shù)據(jù)庫(kù)層面和算法層面的優(yōu)化案例.
1. SQL優(yōu)化案例
案例1:客戶反饋某結(jié)算報(bào)表統(tǒng)計(jì)十天內(nèi)的數(shù)據(jù)耗時(shí)10mins左右.
由于前幾天剛學(xué)會(huì)用RedGate的分析工具,拿到這個(gè)問題,本地嘗試重現(xiàn)后,就直接想使用工具分析.然而,這工具在使用webdev模式起站點(diǎn)時(shí),總是報(bào)錯(cuò),而當(dāng)時(shí)時(shí)一根筋,老是想解決這個(gè)工具的報(bào)錯(cuò)問題.結(jié)果,白白搞了半天也沒搞定.最后不得已放棄工具,轉(zhuǎn)而選擇使用SQL Server Profiler去監(jiān)控SQL語(yǔ)句耗時(shí).一跟蹤不要緊,問題就直接暴露了,整個(gè)全屏的重復(fù)SQL語(yǔ)句,如下圖:
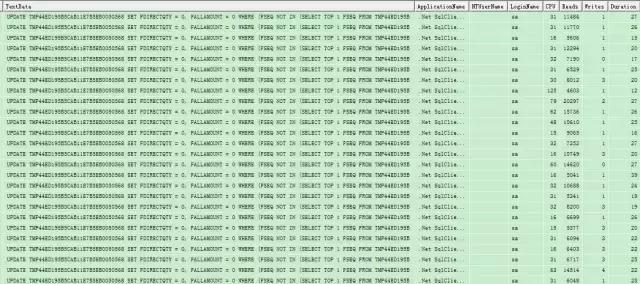
SQL Profiler監(jiān)控結(jié)果
這下問題就很明顯了,八成是代碼在循環(huán)拼接SQL執(zhí)行語(yǔ)句.根據(jù)抓取到SQL關(guān)鍵字往代碼中去搜索,果然如此.

看到這段代碼,咱先不評(píng)判這段代碼的優(yōu)劣,因?yàn)楫吘勾a注釋清晰,省了我們理清業(yè)務(wù)的功夫.這段SQL主要是想做去重處理,很顯然選用了錯(cuò)誤的方案.改后代碼如下:
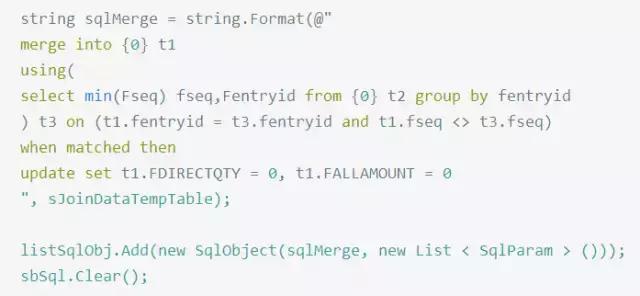
改后測(cè)試相同數(shù)據(jù)量,耗時(shí)由10mins降到10s左右.
2.代碼優(yōu)化案例
案例2:客戶反饋銷售訂單100條分錄行,保存進(jìn)行可發(fā)量校驗(yàn)時(shí),耗時(shí)7mins左右.
拿到這個(gè)問題后,本地重現(xiàn)后,監(jiān)控SQL耗時(shí)沒有異常,那就著重分析代碼了.因?yàn)榭砂l(fā)量校驗(yàn)的業(yè)務(wù)邏輯極其復(fù)雜,加上又直接再一個(gè)類文件實(shí)現(xiàn)該功能,3500+行的代碼,加上零星注釋,真是讓人避之不及.逃避不是辦法,還是上工具分析一把.
這次我選用的時(shí)VS自帶的Performance Profiler,開發(fā)環(huán)境下極其強(qiáng)大的性能調(diào)優(yōu)工具.針對(duì)我們當(dāng)前案例,我們僅需要跟蹤指定服務(wù)對(duì)應(yīng)的DLL即可,使用步驟如下:
Analyze-->Profiler-->New Performance Session
打開Performance Explorer
找到新添加的Performance Session,右鍵Targets,然后選擇Add Target Binary,添加要跟蹤的dll文件即可
將應(yīng)用跑起來(lái)
選中Performance Session,右鍵Attach對(duì)應(yīng)進(jìn)程即可跟蹤分析性能了
在跟蹤過(guò)程中,可隨時(shí)暫停跟蹤和停止跟蹤
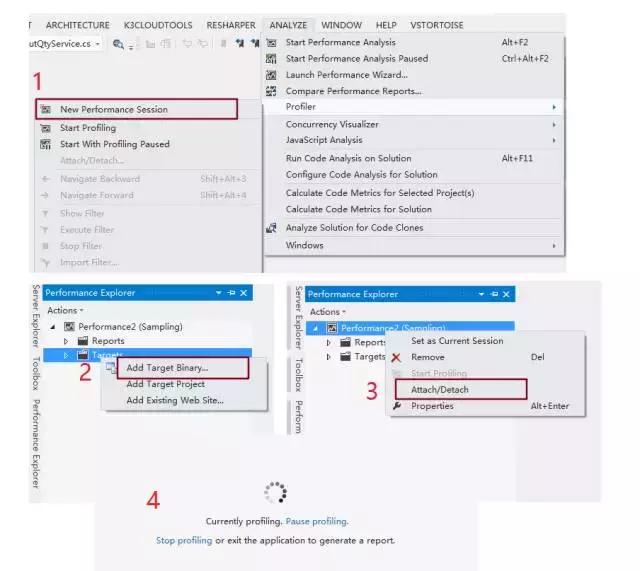
圖示步驟
跟蹤結(jié)束后本案例跟蹤到的采樣結(jié)果如下圖:
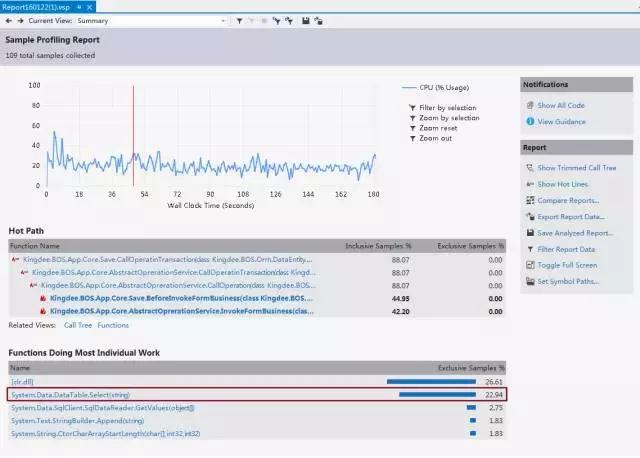
VS Performance Profiler分析報(bào)告
同時(shí)Performance Profiler也給出了問題的建議,如下圖:
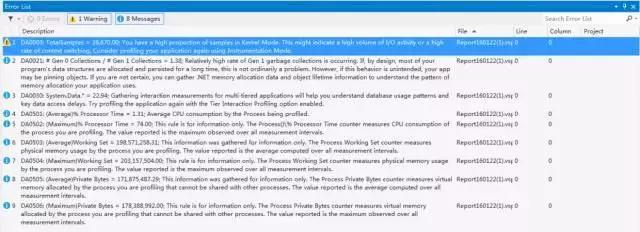
VS Performance Profiler分析提示
其中第1、4條大致說(shuō)明程序I/O消耗大,第一代的GC上存在未及時(shí)釋放的垃圾占比過(guò)高.而根據(jù)上圖的采樣結(jié)果,我們可以直接看出是由于再代碼中頻繁操作DataTable引起的性能瓶頸.走讀代碼發(fā)現(xiàn)的確如此,所有的數(shù)量統(tǒng)計(jì)都是在代碼中循環(huán)遍歷DataTable進(jìn)行處理的.而最終的優(yōu)化策略,就相當(dāng)于一次大的重構(gòu),將所有代碼中通過(guò)遍歷DataTable的計(jì)算邏輯全部挪到SQL中去做.由于代碼過(guò)多,就不再放出.
案例3:客戶反饋批量引入1000張訂單,耗時(shí)40mins左右,且容易中斷.
同樣,我們還是先嘗試本地重現(xiàn).經(jīng)測(cè)試批量引入101張單據(jù),就耗時(shí)5mins左右.下一步打開SQL監(jiān)控工具也未發(fā)現(xiàn)耗時(shí)語(yǔ)句.但考慮到是批量導(dǎo)入操作,雖然單個(gè)耗時(shí)不多,但乘以100這個(gè)基數(shù),就明顯了.下面我們就使用RedGate的Ants Performance Profiler跟蹤一下.
該工具比較直觀,可以同時(shí)監(jiān)控代碼和SQL執(zhí)行情況.第一步,New Profiler Session,第二步進(jìn)行設(shè)置,如下圖.根據(jù)自己的應(yīng)用程序類別,選擇相應(yīng)的跟蹤方式.
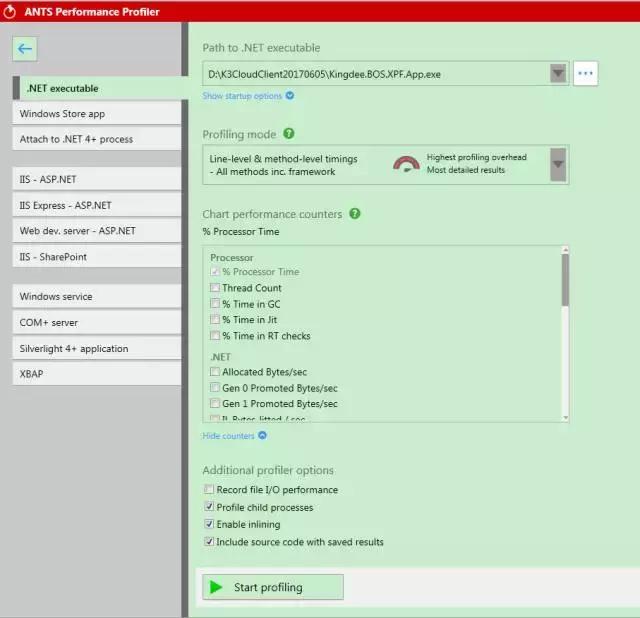
跟蹤設(shè)置
針對(duì)這個(gè)問題,我們跟蹤到的調(diào)用堆棧和SQL耗時(shí)結(jié)果如下圖:

調(diào)用堆棧監(jiān)控結(jié)果
SQL監(jiān)控結(jié)果
首先從調(diào)用堆棧中的Hit Count,我們可以首先看出它是一個(gè)批量過(guò)程,因?yàn)槿肟诤瘮?shù)僅調(diào)用一次;第二個(gè)我們可以代碼中是循環(huán)處理每一個(gè)單據(jù),因?yàn)镠it Count與我們批量引入的單據(jù)數(shù)量相符;第三個(gè),突然來(lái)了個(gè)10201,如果有一定的數(shù)字敏感性的話,這次性能問題的原因就被你找到了.這里就不賣關(guān)子了,101 x 101 = 10201.
是不是明白了什么,存在循環(huán)嵌套循環(huán)的情況.我們走讀代碼確定一下:

好吧,外層套了一個(gè)空循環(huán)卻什么也沒做.修改就很簡(jiǎn)單了,刪除無(wú)效外層循環(huán)即可.
3.算法優(yōu)化案例
案例4:某全流程跟蹤報(bào)表超時(shí).
這個(gè)報(bào)表是用來(lái)跟蹤所有單據(jù)從下單到出庫(kù)的業(yè)務(wù)流程數(shù)據(jù)流轉(zhuǎn)情況.而所有的流程數(shù)據(jù)都是按照樹形結(jié)果存儲(chǔ)在數(shù)據(jù)庫(kù)表中的,類似這樣:

圖中的流程為:銷售合同-->銷售訂單-->發(fā)貨通知單-->銷售出庫(kù)單
為了構(gòu)造流程圖,之前的處理方法是把流程數(shù)據(jù)取回來(lái),通過(guò)代碼構(gòu)造流程圖.這也就是性能差的原因.
而針對(duì)這種情況,就是考驗(yàn)我們平時(shí)經(jīng)驗(yàn)積累了.對(duì)于樹形結(jié)構(gòu)的表,我們也是可以通過(guò)SQL來(lái)進(jìn)行直接查詢的,這就要用到了SQL Server的CTE語(yǔ)法來(lái)進(jìn)行遞歸查詢.
仔細(xì)觀察上面的表結(jié)構(gòu),會(huì)發(fā)現(xiàn)其樹形結(jié)構(gòu)的特點(diǎn):
FFIRSTNODE:標(biāo)記是否為根節(jié)點(diǎn)
FSTABLENAME:標(biāo)記來(lái)源單據(jù)名稱
FSID:標(biāo)記來(lái)源單據(jù)分錄ID
FTTABLENAME:標(biāo)記目標(biāo)單據(jù)名稱
FTID:標(biāo)記目標(biāo)單據(jù)分錄ID
首先想到的辦法就是把流程數(shù)據(jù)取回來(lái),然后代碼構(gòu)造流程圖.
第一個(gè)思路:根據(jù)根節(jié)點(diǎn)循環(huán)往下找,吭呲半天,發(fā)現(xiàn)沒那么簡(jiǎn)單.因?yàn)槿魏我粋€(gè)源頭單據(jù)都可以多次下推目標(biāo)單據(jù).
第二個(gè)思路:先找到終極節(jié)點(diǎn),在從終極節(jié)點(diǎn)往上找只至根節(jié)點(diǎn)為0.
這個(gè)思路實(shí)現(xiàn)起來(lái)也沒有那么復(fù)雜,邏輯理清,循環(huán)遍歷,最終也能實(shí)現(xiàn)結(jié)果.(但在大數(shù)據(jù)量情況下,易導(dǎo)致性能瓶頸.)
這一次我們換一個(gè)思路,讓SQL來(lái)替我們做這一復(fù)雜的遞歸查詢.
1SQL Server 遞歸查詢
基本概念
公用表表達(dá)式(CTE) 可以認(rèn)為是在單個(gè) SELECT、INSERT、UPDATE、DELETE 或CREATE VIEW 語(yǔ)句的執(zhí)行范圍內(nèi)定義的臨時(shí)結(jié)果集.公用表表達(dá)式可以包括對(duì)自身的引用,這種表達(dá)式稱為遞歸公用表表達(dá)式.
創(chuàng)建遞歸查詢.
在不需要常規(guī)使用視圖時(shí)替換視圖,也就是說(shuō),不必將定義存儲(chǔ)在元數(shù)據(jù)中.
啟用按從標(biāo)量嵌套 select 語(yǔ)句派生的列進(jìn)行分組,或者按不確定性函數(shù)或有外部訪問的函數(shù)進(jìn)行分組.
在同一語(yǔ)句中多次引用生成的表.
MSDN上對(duì)CTE的介紹
https://docs.microsoft.com/zh-cn/sql/t-sql/queries/with-common-table-expression-transact-sql
T-SQL查詢進(jìn)階--詳解公用表表達(dá)式(CTE)
http://www.cnblogs.com/CareySon/archive/2011/12/12/2284740.html
CTE 的基本語(yǔ)法結(jié)構(gòu)如下:

即三個(gè)部分:
公用表表達(dá)式的名字(在WITH關(guān)鍵字之后)
查詢的列名(可選)
緊跟AS之后的SELECT語(yǔ)句(如果AS之后有多個(gè)對(duì)公用表的查詢,則只有第一個(gè)查詢有效)
動(dòng)手實(shí)踐
根據(jù)官網(wǎng)示例我們很簡(jiǎn)單就可以寫出CTE語(yǔ)句應(yīng)用于我們的應(yīng)用場(chǎng)景:

在查詢中我們指定條件參數(shù)WHERETBIE.FTTABLENAME = 'T_SAL_ORDERENTRY' AND TBIE.FTID = 121625,即可查詢到指定節(jié)點(diǎn)的完整流程數(shù)據(jù).
其中在與公用表TEST_CTE進(jìn)行關(guān)聯(lián)時(shí),我指定了兩個(gè)條件CTBIE.FSID=CTE.FTIDAND CTBIE.FSTABLENAME = CTE.FTTABLENAME,因?yàn)椴煌愋偷膯螕?jù)各有一套自增的ID,直接用ID進(jìn)行關(guān)聯(lián)迭代不可行.

需要注意的是OPTION(MAXRECURSION10)是用來(lái)限制遞歸次數(shù),以避免無(wú)限遞歸導(dǎo)致數(shù)據(jù)庫(kù)性能消耗嚴(yán)重.
擴(kuò)展:構(gòu)造遞歸路徑
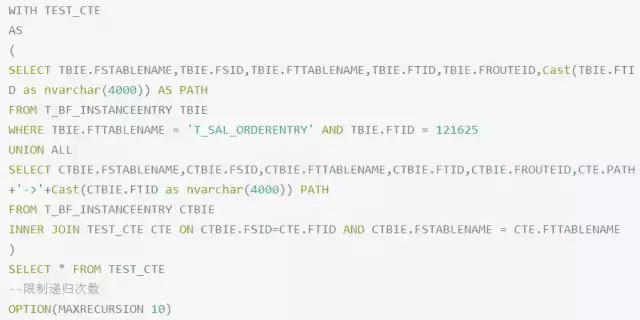
基于上一個(gè)查詢,增加一列手動(dòng)拼接遞歸路徑.注意SQL中將PATH設(shè)置的類型為navarchar(4000),在union中,兩邊的表結(jié)構(gòu)類型必須保持一致,否則會(huì)報(bào)錯(cuò)定位點(diǎn)類型和遞歸部分的類型不匹配.可參考此篇博文
《解決CTE定位點(diǎn)類型和遞歸部分的類型不匹配》.(http://www.cnblogs.com/ccding13/p/3515393.html)

遞歸路徑查詢結(jié)果
2Oracle 遞歸查詢
基本概念
Oracle中的遞歸查詢語(yǔ)句為start with…connect by prior,為中序遍歷算法.
可參考《Oracle 樹操作、遞歸查詢(select…start with…connect by…prior)》了解更多.(鏈接http://www.cnblogs.com/yingsong/p/5035907.html)

其基本語(yǔ)法是:
selectcolname from tablename
start with條件1
connect by條件2
where 條件3
條件1: 是根結(jié)點(diǎn)的限定語(yǔ)句,當(dāng)然可以放寬限定條件,以遍歷多個(gè)根結(jié)點(diǎn),實(shí)際就是多棵樹.
條件2:是連接條件,其中用PRIOR表示上一條記錄.
比如CONNECT BY PRIOR Id = Parent_Id就是說(shuō)上一條記錄的Id 是本條記錄的Parent_Id.
條件3:過(guò)濾返回的結(jié)果集.
PRIOR關(guān)鍵字
運(yùn)算符PRIOR被放置于等號(hào)前后的位置,決定著查詢時(shí)的檢索順序.
PRIOR被置于CONNECT BY子句中等號(hào)的前面時(shí),則強(qiáng)制從根節(jié)點(diǎn)到葉節(jié)點(diǎn)的順序檢索,為自頂向下查找.
如:CONNECT BY PRIOR Id=Parent_Id
PIROR運(yùn)算符被置于CONNECT BY 子句中等號(hào)的后面時(shí),則強(qiáng)制從葉節(jié)點(diǎn)到根節(jié)點(diǎn)的順序檢索,為自底向上的查找.
如:CONNECT BY Id=PRIOR Parent_Id
PS:當(dāng)CONNECT BY后指定多個(gè)連接條件時(shí),每個(gè)條件都應(yīng)指定PRIOR關(guān)鍵字.
動(dòng)手實(shí)踐
理清了用法,我們用Oracle來(lái)對(duì)查詢一下業(yè)務(wù)流程.


查詢結(jié)果
該流程為:銷售訂單-->發(fā)貨通知單-->銷售出庫(kù)單-->退貨通知單-->銷售退貨單
其中在指定連接條件時(shí),我指定了兩個(gè)條件FSID= PRIOR FTID AND FSTABLENAME=PRIOR FTTABLENAME,因?yàn)椴煌愋偷膯螕?jù)各有一套自增的ID,直接用ID進(jìn)行關(guān)聯(lián)迭代不可行.
擴(kuò)展:構(gòu)造遞歸路徑
Oracle中提供了SYS_CONNECT_BY_PATH函數(shù)用來(lái)進(jìn)行連接路徑.

基于上個(gè)查詢,增加了一列SUBSTR(SYS_CONNECT_BY_PATH(FTID,'->'),3)NAME_PATH用來(lái)拼接遞歸路徑.

遞歸路徑查詢結(jié)果
顯示當(dāng)前節(jié)點(diǎn)的根節(jié)點(diǎn)
這個(gè)時(shí)候我們要用到connect_by_root函數(shù),用來(lái)記錄當(dāng)前節(jié)點(diǎn)的根節(jié)點(diǎn)信息.


當(dāng)前節(jié)點(diǎn)的根節(jié)點(diǎn)的查詢結(jié)果
Oracle中的with...as語(yǔ)句
Oracle也有with..as 查詢語(yǔ)法,一般用來(lái)進(jìn)行子查詢,提高查詢效率.
語(yǔ)法:
with tempTableName as ( select * from table1 )
select *from tempTableName
拿我們的案例舉例就是:

為啥要講這個(gè)呢,我們可以在Oracle遞歸查詢后進(jìn)行篩選啊.
總結(jié)
性能調(diào)優(yōu)是一個(gè)循序漸進(jìn)的過(guò)程,不可能一蹴而就,重在平時(shí)的點(diǎn)滴積累.關(guān)于工具的選擇和使用,本文并未展開,也希望讀者也不要糾結(jié)與此.當(dāng)你真正想解決一個(gè)問題的時(shí)候,相信工具的使用是難不住你的.
最后就大致總結(jié)下我的調(diào)優(yōu)思路:
調(diào)整心態(tài),積極應(yīng)對(duì)
了解性能背景, 收集證據(jù), 嘗試重現(xiàn)
問題分類,先監(jiān)控SQL耗時(shí),大致確定是SQL或是代碼層次原因
使用性能分析工具,確定問題點(diǎn)
調(diào)優(yōu)測(cè)試
End.
來(lái)源:公眾號(hào)“DBAplus社群”
運(yùn)行人員:中國(guó)統(tǒng)計(jì)網(wǎng)小編(微信號(hào):itongjilove)
微博ID:中國(guó)統(tǒng)計(jì)網(wǎng)
中國(guó)統(tǒng)計(jì)網(wǎng),是國(guó)內(nèi)最早的大數(shù)據(jù)學(xué)習(xí)網(wǎng)站,公眾號(hào):中國(guó)統(tǒng)計(jì)網(wǎng)
http://www.itongji.cn
《SQL從技巧、案例和工具入手,詳解性能優(yōu)化怎么做》是否對(duì)您有啟發(fā),歡迎查看更多與《SQL從技巧、案例和工具入手,詳解性能優(yōu)化怎么做》相關(guān)教程,學(xué)精學(xué)透。維易PHP學(xué)院為您提供精彩教程。
轉(zhuǎn)載請(qǐng)注明本頁(yè)網(wǎng)址:
http://www.fzlkiss.com/jiaocheng/7840.html
同類教程排行
- Mysql實(shí)例mysql報(bào)錯(cuò):Deadl
- MYSQL數(shù)據(jù)庫(kù)mysql導(dǎo)入sql文件
- MYSQL的UTF8MB4編碼排序要用u
- MYSQL教程mysql自定義split
- 如何打造MySQL高可用平臺(tái)
- MYSQL創(chuàng)建表出錯(cuò)Tablespace
- Mysql必讀MySQL中CLIENT_
- MYSQL數(shù)據(jù)庫(kù)mysql常用字典表(完
- Mysql應(yīng)用MySql的Communi
- Mysql入門解決MySQL Sendi
- Mysql必讀關(guān)于skip_name_r
- MYSQL數(shù)據(jù)庫(kù)MySQL實(shí)現(xiàn)兩張表數(shù)據(jù)
- Mysql實(shí)例使用dreamhost空間
- MYSQL數(shù)據(jù)庫(kù)mysql 查詢表中平均
- MYSQL教程mysql 跨表查詢、更新
