揭秘Spark應(yīng)用性能調(diào)優(yōu)
《揭秘Spark應(yīng)用性能調(diào)優(yōu)》要點(diǎn):
本文介紹了揭秘Spark應(yīng)用性能調(diào)優(yōu),希望對(duì)您有用。如果有疑問,可以聯(lián)系我們。
引言:在多臺(tái)機(jī)器上分布數(shù)據(jù)以及處理數(shù)據(jù)是Spark的核心能力,即我們所說的大規(guī)模的數(shù)據(jù)集處理.為了充分利用Spark特性,應(yīng)該考慮一些調(diào)優(yōu)技術(shù).本文每一小節(jié)都是關(guān)于調(diào)優(yōu)技術(shù)的,并給出了如何實(shí)現(xiàn)調(diào)優(yōu)的必要步驟.
本文選自《Spark GraphX實(shí)戰(zhàn)》.
1 用緩存和持久化來加速 Spark
我們知道Spark 可以通過 RDD 實(shí)現(xiàn)計(jì)算鏈的原理 :轉(zhuǎn)換函數(shù)包含在 RDD 鏈中,但僅在調(diào)用 action 函數(shù)后才會(huì)觸發(fā)實(shí)際的求值過程,執(zhí)行分布式運(yùn)算,返回運(yùn)算結(jié)果.要是在 同一 RDD 上重復(fù)調(diào)用 action 會(huì)發(fā)生什么?
RDD 持久化
一般 RDD 不會(huì)保留運(yùn)算結(jié)果,如果再次調(diào)用 action 函數(shù),整個(gè) RDD 鏈會(huì)重新 運(yùn)算.有些情況下這不會(huì)有問題,但是對(duì)于許多機(jī)器學(xué)習(xí)任務(wù)和圖處理任務(wù),這就 是很大的問題了.通常需要多次迭代的算法,在同一個(gè) RDD 上執(zhí)行很多次,反復(fù) 地重新加載數(shù)據(jù)和重新計(jì)算會(huì)導(dǎo)致時(shí)間浪費(fèi).更糟糕的是,這些算法通常需要很長 的 RDD 鏈.
看來我們需要另一種方式來充分利用集群可用內(nèi)存來保存 RDD 的運(yùn)算結(jié)果. 這就是 Spark 緩存(緩存也是 Spark 支持的一種持久化類型).
要在內(nèi)存中緩存一個(gè) RDD,可以調(diào)用 RDD 對(duì)象的 cache 函數(shù).以下在 spark- shell 中執(zhí)行的代碼,會(huì)計(jì)算文件的總行數(shù),輸出文件內(nèi)容 :
val filename = "..."
val rdd1 = sc.textFile(filename).cache
rdd1.count
rdd1.collect
如果不調(diào)用 cache 函數(shù),當(dāng) count 和 collect 這兩個(gè) action 函數(shù)被調(diào)用時(shí), 會(huì)導(dǎo)致執(zhí)行從存儲(chǔ)系統(tǒng)中讀文件兩次.調(diào)用了 cache 函數(shù),第一個(gè) action 函數(shù)(count 函數(shù))會(huì)把它的運(yùn)算結(jié)果保留在內(nèi)存中,在執(zhí)行第二個(gè) action 函數(shù)(collection 函數(shù))時(shí),會(huì)直接在使用緩存的數(shù)據(jù)上繼續(xù)運(yùn)算,而不需要重新計(jì)算整個(gè) RDD 鏈. 即使通過轉(zhuǎn)換緩存的 RDD,生成新的 RDD,緩存的數(shù)據(jù)仍然可用.下面的代碼會(huì)找出所有的注釋行(以 # 開始的行數(shù)據(jù)).
val rdd2 =rdd1.filter(_.startsWith("#"))
rdd2.collect
因?yàn)?rdd2 源于已緩存的 rdd1,rdd1 已經(jīng)把它的運(yùn)算結(jié)果緩存在內(nèi)存中了, 所以 rdd2 也就不需要重新從存儲(chǔ)系統(tǒng)中讀取數(shù)據(jù).
注意:cache 辦法作為一個(gè)標(biāo)志表示 RDD 應(yīng)當(dāng)緩存,但并不是立即緩存. 緩存發(fā)生在當(dāng)前 RDD 在下一次要被計(jì)算的時(shí)候.
持久化等級(jí)
如上所述,緩存是其中一種持久化類型.下表列出了 Spark 支持的所有持久 化等級(jí).
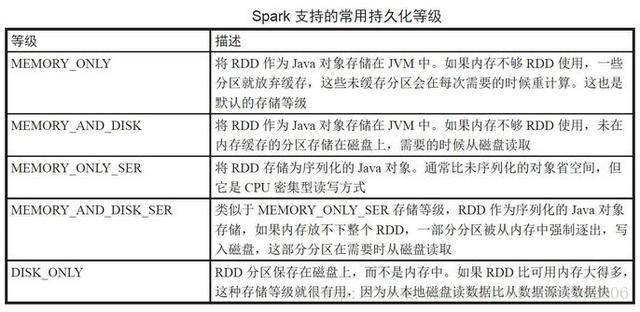
每個(gè)持久化等級(jí)都定義在單例對(duì)象 StorageLevel 中.例如,調(diào)用 rdd.persist(StorageLevel.MEMORY_AND_DISK)辦法會(huì)把 RDD 設(shè)置成內(nèi)存和磁盤緩 存. cache 辦法內(nèi)部也是調(diào)用 rdd.persist(StorageLevel.MEMORY_ONLY).
注意 :其他的持久化等級(jí),如 MEMORY_ONLY2、MEMORY_AND_ DISK2 等,也是可用的.它們會(huì)復(fù)制 RDD到集群的其他節(jié)點(diǎn)上,以便 提供容錯(cuò)能力.這些內(nèi)容超出了本書范圍,感興趣的讀者可以看看 Petar Zec’ evic’ 和 Marko
Bonac’ i(Manning, 2016)的書 Spark in Action,這本書更 深入地介紹了 Spark 容錯(cuò)方面的內(nèi)容.
圖的持久化
無論什么時(shí)候,通過 Graph 對(duì)象調(diào)用一些函數(shù)如 mapVertices 或 aggregateMessages, 這些操作都是基于下層的 RDD 實(shí)現(xiàn)的.
Graph 對(duì)象提供了基于頂點(diǎn) RDD 和邊 RDD 方便的緩存和持久化辦法.
在合適的時(shí)機(jī)反持久化
雖然看起來緩存是一個(gè)應(yīng)該被到處使用的好東西,但是用得太多也會(huì)讓人過度依賴它.
當(dāng)緩存越來越多的 RDD 后,可用的內(nèi)存就會(huì)減少.最終 Spark 會(huì)把分區(qū)數(shù)據(jù)從 內(nèi)存中逐出(使用最少最近使用算法,LRU).同時(shí),緩存過多的 Java 對(duì)象,JVM 垃圾回收高耗是不可避免的.這就是為什么當(dāng)緩存不再被使用時(shí)很有必要調(diào)用 un- persist 辦法.對(duì)迭代算法而言,在循環(huán)中常用下面的辦法調(diào)用模式 :
調(diào)用 Graph 的 cache 或 persist 辦法.
調(diào)用 Graph 的 action 函數(shù),觸發(fā) Graph 下面的 RDD 被緩存……
執(zhí)行算法主體的其余部分.
在循環(huán)體的最后部分,反持久化,即釋放緩存.
提示 :用Pregel API的好處是,它已經(jīng)在內(nèi)部做了緩存和釋放緩存的操作.
何時(shí)不用緩存
不能盲目地在內(nèi)存中緩存 RDD.要考慮數(shù)據(jù)集會(huì)被拜訪多少次以及每次拜訪時(shí) 重計(jì)算和緩存的代價(jià)對(duì)比,重計(jì)算也可能比增加內(nèi)存的方式付出的代價(jià)小.
毫無疑問,如果僅僅讀一次數(shù)據(jù)集,緩存 RDD 就毫無意義,這還會(huì)讓作業(yè)運(yùn) 行得更慢,特別是用了有序列化的持久化等級(jí).
2.checkpointing
圖算法中一個(gè)常用的模式是用每個(gè)迭代過程中運(yùn)算后的新數(shù)據(jù)更新圖.這意味 著,實(shí)際構(gòu)成圖的頂點(diǎn) RDD 亦或邊 RDD 的鏈會(huì)變得越來越長.
定義 :當(dāng) RDD 由逐級(jí)繼承的祖先 RDD 鏈形成時(shí),我們說從 RDD 到 根 RDD 的路徑是其譜系.
下面清單所示的示例是一個(gè)簡單的算法,可生成一個(gè)新頂點(diǎn)集并更新圖.這個(gè) 算法迭代的次數(shù)由變量 iterations 控制.

上述代碼每一次調(diào)用 joinVertices 都會(huì)增加一個(gè)新 RDD 到頂點(diǎn) RDD 鏈中. 顯然我們需要使用緩存來確保在每次迭代中避免重新計(jì)算 RDD 鏈,但這并不能改變一個(gè)事實(shí),那就是有一個(gè)不斷增長的子 RDD 到父 RDD 的對(duì)象引用列表.
這樣的后果是,如果運(yùn)行迭代次數(shù)過多,運(yùn)行的代碼中最終會(huì)爆出 Stack- OverflowError 棧溢出錯(cuò)誤.通常迭代 500次就會(huì)出現(xiàn)棧溢出.
而由 RDD 提供并且被 Graph 繼承的一個(gè)特性 :checkpointing,能解決長 RDD 譜系問題.下面清單中的代碼示范了如何使用 checkpointing,這樣就可以持續(xù)輸出 頂點(diǎn),更新結(jié)果圖.

一個(gè)標(biāo)記為 checkpointing 的 RDD 會(huì)把 RDD 保存到一個(gè) checkpoint 目錄,然 后指向父 RDD 的連接被切斷,即切斷了 lineage 譜系.一個(gè)標(biāo)記為 checkpointing 的 Graph 會(huì)導(dǎo)致下面的頂點(diǎn) RDD 和邊 RDD 做 checkpoint.
調(diào)用 SparkContext.setCheckpointDir 來設(shè)置 checkpoint 目錄,指定一個(gè) 共享存儲(chǔ)系統(tǒng)的文件路徑,如 HDFS.
如前面的代碼清單所示,必須在調(diào)用 RDD 任何辦法之前調(diào)用 checkpoint,這 是因?yàn)?checkpointing 是一個(gè)相當(dāng)耗時(shí)的過程(畢竟需要把圖寫入磁盤文件),通常 需要不斷地 checkpoint 避免棧溢出錯(cuò)誤,一般可以每 100 次迭代做一次 checkpoint.
注意 :一個(gè)加速 checkpointing 的選擇是 checkpoint 到 Tachyon(已 更名為 Alluxio),而不是checkpoint 到標(biāo)準(zhǔn)的文件系 統(tǒng).Alluxio,來自 AMPLab,是一個(gè)“以內(nèi)存為中心的有容錯(cuò)能力的分布式文件系統(tǒng),它能讓Spark 這類集群框架加速拜訪共享在內(nèi)存中的文件”.
3 通過序列化降低內(nèi)存壓力
內(nèi)存壓力(內(nèi)存不夠用)往往是 Spark 應(yīng)用性能差和容易出故障的主要原因 之一.這些問題通常表現(xiàn)為頻繁的、耗時(shí)的 JVM 垃圾回收和“內(nèi)存不足”的錯(cuò) 誤.checkpointing 在這里也不能緩解內(nèi)存壓力.遇到這種問題,首先要考慮序列化 Graph 對(duì)象.
定義 :數(shù)據(jù)序列化,Data serialization,是把 JVM 里表示的對(duì)象實(shí) 例轉(zhuǎn)換(序列化)成字節(jié)流 ;把字節(jié)流通過網(wǎng)絡(luò)傳輸?shù)搅硪粋€(gè) JVM 進(jìn)程 中 ;在另一個(gè) JVM 進(jìn)程中,字節(jié)流可以被“反序列化”為一個(gè)對(duì)象實(shí)例.Spark用序列化的方式,可以在網(wǎng)絡(luò)間傳輸對(duì)象,也可以把序列化后的字節(jié)流緩存在內(nèi)存中.
要用序列化,可以選用 persist 中下面的 StorageLevels :
StorageLevel.MEMORY_ONLY_SER
StorageLevel.MEMORY_AND_DISK_SER
序列化節(jié)省了空間,同時(shí)序列化和反序列化也會(huì)增加 CPU 的開銷.
使用 Kryo 序列化
Spark 默認(rèn)使用 JavaSerializer 來序列化對(duì)象,這是一個(gè)低效的 Java 序列化框架,一個(gè)更好的選擇是選用 Kryo.Kryo 是一個(gè)開源的 Java 序列化框架,提供了 快速高效的序列化能力.
Spark 中使用 Kryo 序列 化,只需要設(shè)置 spark.serializer 參數(shù)為 org. apache.spark.serializer.KryoSerializer,如這樣設(shè)置命令行參數(shù) :
spark-shell --conf "spark.serializer=org.apache.spark.serializer.KryoSerializer"
要是每次都這樣設(shè)置參數(shù),會(huì)很煩瑣.可以在 $Spark_HOME/conf/spark-
defaults.conf 這個(gè)配置文件中,用標(biāo)準(zhǔn)的屬性文件語法(用 Tab 分隔作為一行),把 spark.serializer 等參數(shù)及其對(duì)應(yīng)的值寫入這個(gè)配置文件,如下所示 :
spark.serializer org.apache.spark.serializer.KryoSerializer
為保證性能最佳,Kryo 要求注冊(cè)要序列化的類,如果不注冊(cè),類名也會(huì)被序列 化在對(duì)象字節(jié)碼里,這樣對(duì)性能有較大影響.幸運(yùn)的是,Spark 對(duì)其框架里用到的 類做了自動(dòng)注冊(cè) ;但是,如果應(yīng)用程序代碼里有自定義的類,恰好這些自定義類也 要用 Kryo 序列化,那就需要調(diào)用 SparkConf.registerKryoClasses 函數(shù)來手 動(dòng)注冊(cè).下面的清單展示了如何注冊(cè) Person 這個(gè)自定義類.

檢查 RDD 大小
在應(yīng)用程序調(diào)優(yōu)時(shí),常常需要知道 RDD 的大小.這就很棘手,因?yàn)槲募驍?shù) 據(jù)庫中對(duì)象的大小和 JVM 中對(duì)象占用多少內(nèi)存沒有太大關(guān)系.
一個(gè)小技巧是,先將 RDD 緩存到內(nèi)存中,然后到 Spark UI 中的 Storage 選項(xiàng)卡, 這里記錄著 RDD 的大小.要衡量配置了序列化的效果,用這個(gè)辦法也可以.
《揭秘Spark應(yīng)用性能調(diào)優(yōu)》是否對(duì)您有啟發(fā),歡迎查看更多與《揭秘Spark應(yīng)用性能調(diào)優(yōu)》相關(guān)教程,學(xué)精學(xué)透。維易PHP學(xué)院為您提供精彩教程。
轉(zhuǎn)載請(qǐng)注明本頁網(wǎng)址:
http://www.fzlkiss.com/jiaocheng/8685.html
同類教程排行
- Mysql實(shí)例mysql報(bào)錯(cuò):Deadl
- MYSQL數(shù)據(jù)庫mysql導(dǎo)入sql文件
- MYSQL的UTF8MB4編碼排序要用u
- MYSQL教程mysql自定義split
- 如何打造MySQL高可用平臺(tái)
- MYSQL創(chuàng)建表出錯(cuò)Tablespace
- Mysql必讀MySQL中CLIENT_
- MYSQL數(shù)據(jù)庫mysql常用字典表(完
- Mysql應(yīng)用MySql的Communi
- Mysql入門解決MySQL Sendi
- Mysql必讀關(guān)于skip_name_r
- MYSQL數(shù)據(jù)庫MySQL實(shí)現(xiàn)兩張表數(shù)據(jù)
- Mysql實(shí)例使用dreamhost空間
- MYSQL數(shù)據(jù)庫mysql 查詢表中平均
- MYSQL教程mysql 跨表查詢、更新
