Redis Cluster探索與思考
《Redis Cluster探索與思考》要點:
本文介紹了Redis Cluster探索與思考,希望對您有用。如果有疑問,可以聯系我們。
作者 | 張冬洪
責編 | 仲培藝
Redis Cluster的基來源根基理和架構
Redis Cluster是分布式Redis的實現.隨著Redis版本的更替,以及各種已知bug的fixed,在穩定性和高可用性上有了很大的提升和進步,越來越多的企業將Redis Cluster實際應用到線上業務中,通過從社區獲取到反饋社區的迭代,為Redis Cluster成為一個可靠的企業級開源產品,在簡化業務架構和業務邏輯方面都起著積極重要的作用.下面從Redis Cluster的基來源根基理為起點開啟Redis Cluster在業界的分析與思考之旅.
基來源根基理
Redis Cluster的基來源根基理可以從數據分片、數據遷移、集群通訊、故障檢測以及故障轉移等方面進行了解,Cluster相關的代碼也不是很多,注釋也很詳細,可自行查看,地址是:https://github.com/antirez/redis/blob/unstable/src/cluster.c.這里由于篇幅的原因,主要從數據分片和數據遷移兩方面進行詳細介紹:
數據分片
Redis Cluster在設計中沒有使用一致性哈希(Consistency Hashing),而是使用數據分片(Sharding)引入哈希槽(hash slot)來實現;一個 Redis Cluster包括16384(0~16383)個哈希槽,存儲在Redis Cluster中的所有鍵都會被映射到這些slot中,集群中的每個鍵都屬于這16384個哈希槽中的一個,集群使用公式slot=CRC16(key)/16384來計算key屬于哪個槽,其中CRC16(key)語句用于計算key的CRC16 校驗和.
集群中的每個主節點(Master)都負責處理16384個哈希槽中的一部分,當集群處于穩定狀態時,每個哈希槽都只由一個主節點進行處理,每個主節點可以有一個到N個從節點(Slave),當主節點出現宕機或網絡斷線等弗成用時,從節點能自動提升為主節點進行處理.
如圖1,ClusterNode數據結構中的slots和numslots屬性記錄了節點負責處理哪些槽.其中,slot屬性是一個二進制位數組(bitarray),其長度為16384/8=2048 Byte,共包括16384個二進制位.集群中的Master節點用bit(0和1)來標識對于某個槽是否擁有.比如,對于編號為1的槽,Master只要判斷序列第二位(索引從0開始)的值是不是1即可,時間復雜度為O(1).

圖1 ClusterNode數據布局

集群中所有槽的分配信息都保存在ClusterState數據結構的slots數組中,程序要檢查槽i是否已經被分配或者找出處理槽i的節點,只需要拜訪clusterState.slots[i]的值即可,復雜度也為O(1).ClusterState數據結構如圖2所示.
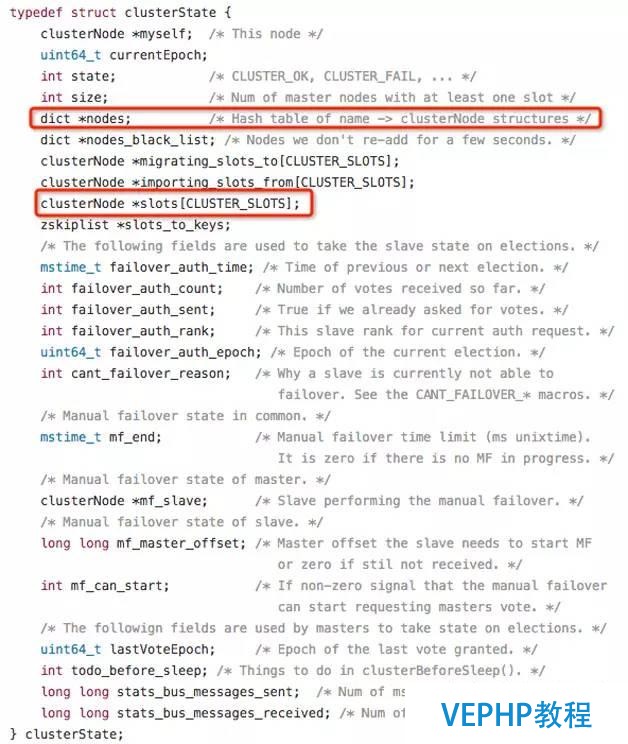
圖2 ClusterState數據布局
查找關系如圖3所示.
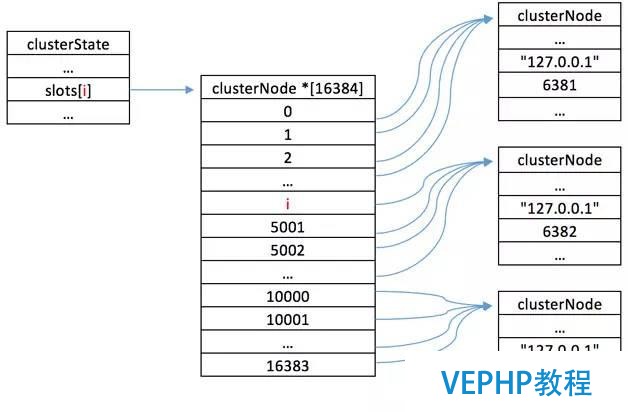
圖3 查找關系圖
數據遷移
數據遷移可以理解為slot和key的遷移,這個功能很重要,極大地便利了集群做線性擴展,以及實現平滑的擴容或縮容.那么它是一個怎樣的實現過程?下面舉個例子:現在要將Master A節點中編號為1、2、3的slot遷移到Master B節點中,在slot遷移的中間狀態下,slot 1、2、3在Master A節點的狀態表現為MIGRATING,在Master B節點的狀態表現為IMPORTING.
MIGRATING狀態
這個狀態如圖4所示是被遷移slot在當前所在Master A節點中出現的一種狀態,預備遷移slot從Mater A到Master B的時候,被遷移slot的狀態首先變為MIGRATING狀態,當客戶端哀求的某個key所屬的slot的狀態處于MIGRATING狀態時,會出現以下幾種情況:
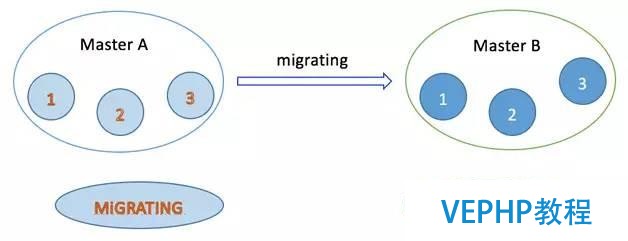
圖4 slot遷移的中間狀態
如果key存在則勝利處理.
如果key不存在,則返回客戶端ASK,客戶端根據ASK首先發送ASKING命令到目標節點,然后發送哀求的命令到目標節點.
當key包括多個命令時:
如果都存在則勝利處理
如果都不存在,則返回客戶端ASK
如果一部分存在,則返回客戶端TRYAGAIN,通知客戶端稍后重試,這樣當所有的key都遷移完畢,客戶端重試哀求時會得到ASK,然后經過一次重定向就可以獲取這批鍵
此時并不刷新客戶端中node的映射關系
IMPORTING狀態
這個狀態如圖2所示是被遷移slot在目標Master B節點中出現的一種狀態,預備遷移slot從Mater A到Master B的時候,被遷移slot的狀態首先變為IMPORTING狀態.在這種狀態下的slot對客戶端的哀求可能會有下面幾種影響:
如果key不存在則新建.
如果key不在該節點上,命令會被MOVED重定向,刷新客戶端中node的映射關系.
如果是ASKING命令則命令會被執行,從而key沒在被遷移的節點,已經被遷移到目標節點的情況命令可以被順利執行.
鍵空間遷移
這是完成數據遷移的重要一步,鍵空間遷移是指當滿足了slot遷移前提的情況下,通過相關命令將slot 1、2、3中的鍵空間從Master A節點轉移到Master B節點,這個過程由MIGRATE命令經過3步真正完成數據轉移.步調示意如圖5.
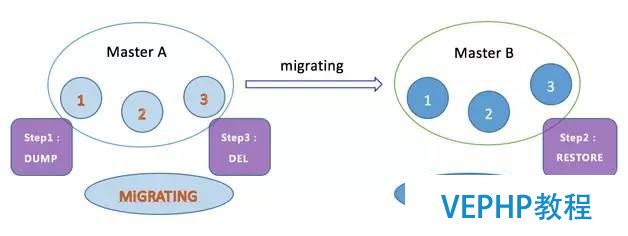
圖5 表空間遷移步調
顛末上面三步可以完成鍵空間數據遷移,然后再將處于MIGRATING和IMPORTING狀態的槽變為常態即可,從而完成整個重新分片的過程.
架構
實現細節:
Redis Cluster中節點負責存儲數據,記錄集群狀態,集群節點能自動發現其他節點,檢測出節點的狀態,并在必要時剔除故障節點,提升新的主節點.
Redis Cluster中所有節點通過PING-PONG機制彼此互聯,使用一個二級制協議(Cluster Bus) 進行通信,優化傳輸速度和帶寬.發現新的節點、發送PING包、特定情況下發送集群消息,集群連接能夠宣布與訂閱消息.
客戶端和集群中的節點直連,不需要中間的Proxy層.理論上而言,客戶端可以自由地向集群中的所有節點發送哀求,但是每次不需要連接集群中的所有節點,只需要連接集群中任何一個可用節點即可.當客戶端發起哀求后,接收到重定向(MOVED\ASK)錯誤,會自動重定向到其他節點,所以客戶端無需保存集群狀態.不過客戶端可以緩存鍵值和節點之間的映射關系,這樣能明顯提高命令執行的效率.
Redis Cluster中節點之間使用異步復制,在分區過程中存在窗口,容易導致丟失寫入的數據,集群即使努力測驗考試所有寫入,但是以下兩種情況可能丟失數據:
命令操作已經到達主節點,但在主節點回復的時候,寫入可能還沒有通過主節點復制到從節點那里.如果這時主節點宕機了,這條命令將永久丟失.以防主節點長時間弗成達而它的一個從節點已經被提升為主節點.
分區導致一個主節點不可達,然而集群發送故障轉移(failover),提升從節點為主節點,本來的主節點再次恢復.一個沒有更新路由表(routing table)的客戶端或許會在集群把這個主節點變成一個從節點(新主節點的從節點)之前對它進行寫入操作,導致數據徹底丟失.
Redis集群的節點不可用后,在經過集群折半以上Master節點與故障節點通信超過cluster-node-timeout時間后,認為該節點故障,從而集群根據自動故障機制,將從節點提升為主節點.這時集群恢復可用.
Redis Cluster的優勢和不敷
優勢
1. 無中心架構.
2. 數據依照slot存儲分布在多個節點,節點間數據共享,可動態調整數據分布.
3. 可擴展性,可線性擴展到1000個節點,節點可動態添加或刪除.
4. 高可用性,部分節點弗成用時,集群仍可用.通過增加Slave做standby數據副本,能夠實現故障自動failover,節點之間通過gossip協議交換狀態信息,用投票機制完成Slave到Master的角色提升.
5. 降低運維本錢,提高系統的擴展性和可用性.
不足
1. Client實現復雜,驅動要求實現Smart Client,緩存slots mapping信息并及時更新,提高了開發難度,客戶端的不成熟影響業務的穩定性.目前僅JedisCluster相對成熟,異常處理部分還不完善,好比常見的“max redirect exception”.
2. 節點會因為某些原因發生阻塞(阻塞時間大于clutser-node-timeout),被判斷下線,這種failover是沒有需要的.
3. 數據通過異步復制,不保證數據的強一致性.
4. 多個業務使用同一套集群時,無法根據統計區分冷熱數據,資源隔離性較差,容易呈現相互影響的情況.
5. Slave在集群中充當“冷備”,不克不及緩解讀壓力,當然可以通過SDK的合理設計來提高Slave資源的利用率.
Redis Cluster在業界有哪些探索
通過調研了解,目前業界使用Redis Cluster年夜致可以總結為4類:
直連型
直連型,又可以稱之為經典型或者傳統型,是官方的默認使用方式,架構圖見圖6.這種使用方式的優缺點在上面的介紹中已經有所說明,這里不再過多重復贅述.但值得一提的是,這種方式使用Redis Cluster需要依賴Smart Client,諸如連接維護、緩存路由表、MultiOp和Pipeline的支持都需要在Client上實現,而且很多語言的Client目前都還是沒有的(關于Clients的更多介紹請參考https://redis.io/clients).雖然Client能夠進行定制化,但有必定的開發難度,客戶端的不成熟將直接影響到線上業務的穩定性.
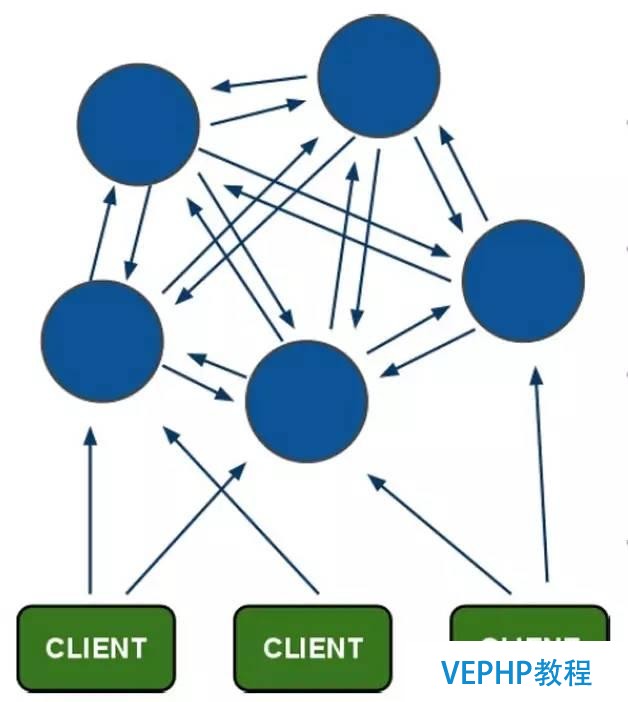
圖6 Redis Cluster架構
帶Proxy型
在Redis Cluster還沒有那么穩定的時候,很多公司都已經開始探索分布式Redis的實現了,好比有基于Twemproxy或者Codis的實現,下面舉一個唯品會基于Twemproxy架構的例子(不少公司分布式Redis的集群架構都經歷過這個階段),如圖7所示.
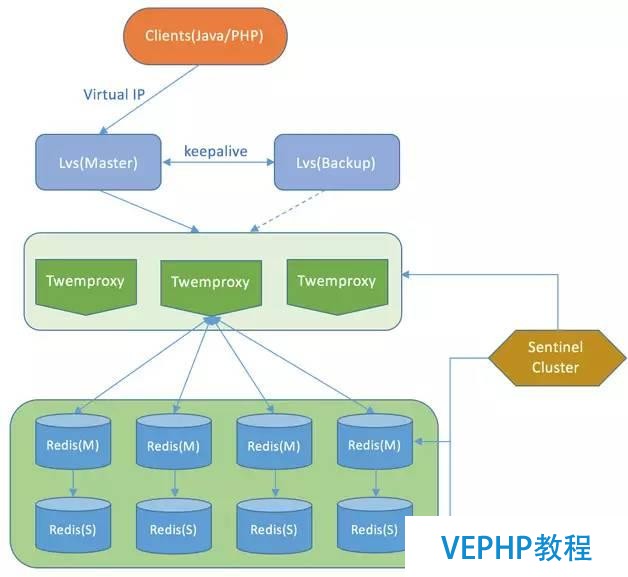
圖7 Redis基于Twemproxy的架構實現
這種架構的優點和缺點也比擬明顯.
長處:
1. 后端Sharding邏輯對業務透明,業務方的讀寫方式和操作單個Redis一致;
2. 可以作為Cache和Storage的Proxy,Proxy的邏輯和Redis資源層的邏輯是隔離的;
3. Proxy層可以用來兼容那些目前還不支持的Clients.
缺點:
1. 結構復雜,運維本錢高;
2. 可擴展性差,進行擴縮容都必要手動干預;
3. failover邏輯需要自己實現,其自己不能支持故障的自動轉移;
4. Proxy層多了一次轉發,性能有所損耗.
正是因此,我們知道Redis Cluster和基于Twemproxy布局使用中各自的優缺點,于是就出現了下面的這種架構,糅合了二者的優點,盡量規避二者的缺點,架構如圖8.
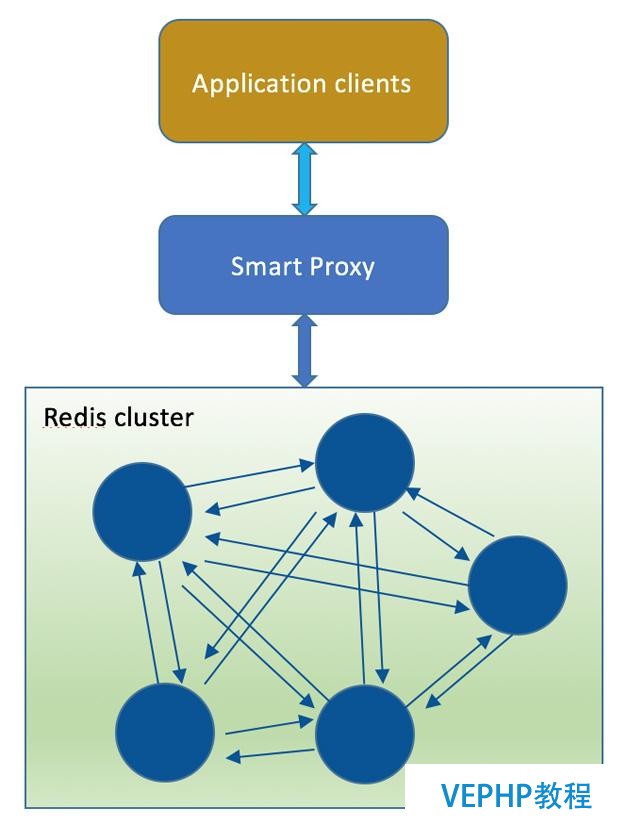
圖8 Smart Proxy計劃架構
目前業界Smart Proxy的方案了解到的有基于Nginx Proxy和自研的,自研的如餓了么開源部分功能的Corvus,優酷土豆是則通過Nginx來實現,滴滴也在展開基于這種方式的探索.選用Nginx Proxy主要是考慮到Nginx的高性能,包含異步非阻塞處理方式、高效的內存管理、和Redis一樣都是基于epoll事件驅動模式等優點.優酷土豆的Redis服務化就是采用這種結構.
長處:
1. 提供一套HTTP Restful接口,隔離底層資源,對客戶端完全透明,跨語言挪用變得簡單;
2. 升級維護較為容易,維護Redis Cluster,只需平滑升級Proxy;
3. 條理化存儲,底層存儲做冷熱異構存儲;
4. 權限控制,Proxy可以通過密鑰管理白名單,把一些不合法的哀求都過濾掉,并且也可以對用戶哀求的超大value進行控制和過濾;
5. 平安性,可以屏蔽掉一些危險命令,比如keys *、save、flushall等,當然這些也可以在Redis上進行設置;
6. 資源邏輯隔離,根據分歧用戶的key加上前綴,來實現動態路由和資源隔離;
7. 監控埋點,對于分歧的接口進行埋點監控.
缺點:
1. Proxy層做了一次轉發,性能有所損耗;
2. 增加了運維成本和管理成本,需要對架構和Nginx Proxy的實現細節足夠了解,因為Nginx Proxy在批量接口調用高并發下可能會瞬間向Redis Cluster發起幾百甚至上千的協程去拜訪,導致Redis的連接數或系統負載的不穩定,進而影響集群整體的穩定性.
云服務型
這種類型典型的案例就是企業級的PaaS產品,如亞馬遜和阿里云提供的Redis Cluster服務,用戶無需知道內部的實現細節,只管使用即可,降低了運維和開發成本.當然也有開源的產品,國內如搜狐的CacheCloud,它提供一個Redis云管理平臺,實現多種類型(Redis Standalone、Redis Sentinel、Redis Cluster)自動部署,辦理Redis實例碎片化現象,提供完善統計、監控、運維功能,減少開發人員的運維成本和誤操作,提高機器的利用率,提供靈活的伸縮性,提供方便的接入客戶端,更多細節請參考:https://cachecloud.github.io.盡管這還不錯,如果是一個新業務,到可以嘗試一下,但若對于一個穩定的業務而言,要遷移到CacheCloud上則需要謹慎.如果對分布式框架感興趣的可以看下Twitter開源的一個實現Memcached和Redis的分布式緩存框架Pelikan,目前國內并沒有看到這樣的應用案例,它的官網是http://twitter.github.io/pelikan/.
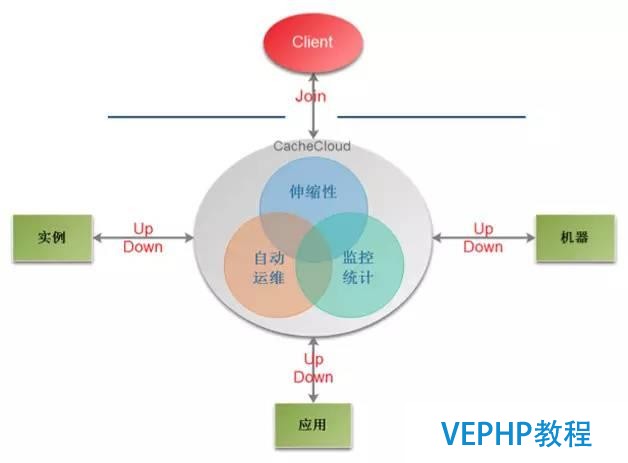
圖9 CacheCloud平臺架構
自研型
這種類型在眾多類型中更顯得孤獨,因為這種類型的方案更多是現象級,僅僅存在于為數不多的具有自研能力的公司中,或者說這種方案都是各公司根據自己的業務模型來進行定制化的.這類產品的一個共同特點是沒有使用Redis Cluster的全部功能,只是借鑒了Redis Cluster的某些核心功能,比如說failover和slot的遷移.作為國內使用Redis較早的公司之一,新浪微博就基于內部定制化的Redis版本研發出了微博Redis服務化系統Tribe.它支持動態路由、讀寫分離(從節點能夠處理讀哀求)、負載均衡、配置更新、數據聚集(相同前綴的數據落到同一個slot中)、動態擴縮容,以及數據落地存儲.同類型的還有百度的BDRP系統.
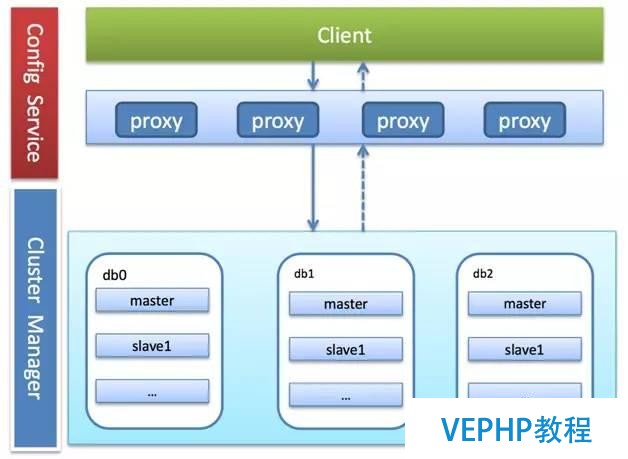
圖10 Tribe系統架構圖
Redis Cluster運維開發最佳實踐經驗
根據公司的業務模型選擇合適的架構,適合本身的才是最好的;
做好容錯機制,當連接或者哀求異常時進行連接retry或reconnect;
重試時間可設置大于cluster-node-time (默認15s),增強容錯性,減少不需要的failover;
避免發生hot-key,導致節點成為系統的短板;
避免發生big-key,導致網卡打爆和慢查詢;
設置合理的TTL,釋放內存.避免大量key在同一時間段過期,雖然Redis已經做了很多優化,仍然會導致哀求變慢;
避免使用阻塞操作(如save、flushall、flushdb、keys *等),不建議使用事務;
Redis Cluster不建議使用pipeline和multi-keys操作(如mset/mget. multi-key操作),減少max redirect的發生;
當數據量很大時,由于復制積壓緩沖區大小的限制,主從節點做一次全量復制導致網絡流量暴增,建議單實例容量不要分配過大或者借鑒微博的優化采納增量復制的方式來規避;
數據持久化建議在業務低峰期操作,關閉aofrewrite機制,aof的寫入操作放到bio線程中完成,辦理磁盤壓力較大時Redis阻塞的問題.設置系統參數vm.overcommit_memory=1,也可以避免bgsave/aofrewrite的失敗;
client buffer參數調整
client-output-buffer-limit normal 256mb 128mb 60
client-output-buffer-limit slave 512mb 256mb 180
對于版本升級的問題,修改源碼,將Redis的核心處理邏輯封裝到動態庫,內存中的數據保留在全局變量里,通過外部程序來調用動態庫里的相應函數來讀寫數據.版本升級時只需要替換成新的動態庫文件即可,無須重新載入數據,可毫秒級完成;
對付實現異地多活或實現數據中心級災備的要求(即實現集群間數據的實時同步),可以參考搜狐的實現:Redis Cluster => Redis-Port => Smart proxy => Redis Cluster;
從Redis 4.2的Roadmap來看,更值得等待(詳情:https://gist.github.com/antirez/a3787d538eec3db381a41654e214b31d):
加速key->hashslot的分派
更好更多的數據中心存儲
redis-trib的C代碼將移植到redis-cli,瘦身包體積
集群的備份/恢復
非阻塞的Migrate
更快的resharding
暗藏一個只Cache模式,當沒有Slave時,Masters當在有一個失敗后能夠自動重新分配slot
Cluster API和Redis Modules的改進,而且Disque分布式消息隊列將作為Redis Module加入Redis.
致謝:感謝好友陳群、李航和劉東輝的幫忙審稿和寶貴建議.
作者簡介
張冬洪,微博研發中心高檔DBA,Redis中國用戶組主席,多年Linux和數據庫運維經驗,專注于MySQL和NoSQL架構設計與運維以及自動化平臺的開發;目前在微博主要負責Feed核心系統相關業務的數據庫運維和業務保障工作.
歡迎參與《Redis Cluster探索與思考》討論,分享您的想法,維易PHP學院為您提供專業教程。
