德歌:PostgreSQL獨孤九式搞定物聯網
《德歌:PostgreSQL獨孤九式搞定物聯網》要點:
本文介紹了德歌:PostgreSQL獨孤九式搞定物聯網,希望對您有用。如果有疑問,可以聯系我們。
相關主題:PostgreSQL教程
【直播預告】5月27日,阿里云高級技術專家德歌將在云棲社區直播《云數據庫RDS for PostgreSQL最佳實踐》 : https://yq.aliyun.com/webinar/join/15 ,為你分享阿里云云數據庫PostgreSQL的最佳技術實戰,包含PostgreSQL使用技巧、上云實戰、數據遷移與同步、插件使用等內容,純干貨.
物聯網行業不再僅僅只是設備的接入,設備接入后數據的采集和融合,以及融合后的分析,會為整個社會帶來重要的價值.數據,讓我們更真實的了解社會與自然,讓人與自然、與社會更加的融合.但物聯網也遠沒你想的那么難,經典的物聯網架構分為感知層、網絡層和應用層.感知層主要包含傳感器網關、節點等數據采集工具;采集到的數據再經過互聯網、移動通信網等傳輸網傳遞到物聯網的“大腦”-應用層加以分析應用.隨著物聯網的越來越廣泛使用,特定應用場景的需求也越發明顯,如智能物流中需要對地理位置信息處理需求強烈;公安刑偵中的模糊化搜索等等.這不僅對物聯網中的硬件是個挑戰,同時對物聯網中數據庫管理系統也提出了更高的要求.
本文即為年夜家分享關于PostgreSQL如何搞定物聯網的“獨孤九式”——
總訣式-知己知彼、百戰不殆

圖一 總訣式-知己知彼、百戰不殆
正如兵家講究知己知彼,百戰不殆一樣,要真正實現萬物互聯、互通的物聯網,就要熟知特定場景的具體要求,有針對性地給出辦理方案.通過對智能家居、環境監測、城市交通、個人保健等具體場景的分析,可以對物聯網應用場景特性做一個小結:
數據量大 (壓縮、數據處理才能);
數據有時序、時空、文本屬性 (時序、地理位置、文本數據處理才能);
某些數據難以布局化,如圖像處理 (自定義能力、擴展能力、非布局化數據處理能力);
數據處理實時性高 (流式處理才能);
數據維度多,相關性復雜 (復雜查詢、統計分析才能);
有模糊、相似度查詢需求 (數據歸類、索引功力);
某些場景行鎖競爭強烈 (秒殺特性功能).
有了總訣式作為心法總綱,就可以針對特定的“招式”一一破解.
破劍式 - 搞定非布局化、定制數據對象

圖二 破劍式 - 搞定非布局化、定制數據對象
要知道很多數據是弗成以預先結構化的,或者是經過產品迭代過程后,預先結構化不再起作用,如圖像處理等.因此非結構化的處理在物聯網中顯得尤為重要.
PostgreSQL是這樣來應對非結構化數據場景的:首先PostgreSQL支持JSONB數據類型,該數據類型非常適合非結構化數據場景,例如傳感器采集的數據以JSON格式上傳;其次在定制數據對象方面,PostgreSQL開放了類型擴展和索引擴展兩類接口,使用者無需關注數據庫內核的實現方式,只需要關注業務自己.比如電路板的質量檢測場景,使用者只需要關注焊點是否虛焊,然后再通過開放的接口將其對象化到數據庫中;同時PostgreSQL中的自定義函數支持C、Python、Java等多種語言定義,擴展性極高.
破刀式 - 搞定文本、空間、時序流式數據

圖三 破刀式 - 搞定文本、空間、時序流式數據
在模糊查詢、分詞等文本處理方面,PostgreSQL天然支持分詞的特性,包含中文分詞和英文分詞,性能上能夠做到每秒處理千萬詞匯的級別,足夠滿足使用者的需求.
空間地理位置數據管理方面,PostgreSQL支持PostGIS和Pgrouting兩種位置處置的插件,PostGIS是全球使用范圍最廣的地理位置信息處置插件,在美國宇航局、歐洲宇航局等企業中得到了廣泛使用;Pgrouting是基于位置信息完成最短路徑運算的插件.
流式處理方面,PostgreSQL 9.5以后的版本支持BRIN索引,非常適合帶有時序屬性的流式數據.如果依照時間來訪問流式日志數據,以往需要創建B-tree索引進行范圍查詢或者精確匹配,但是B-tree索引會因為需要存儲的較大信息量導致索引也很龐大;而BRIN記錄的是每(連續)塊元數據,索引變得很小.下圖是兩種索引之間差別詳細對比:
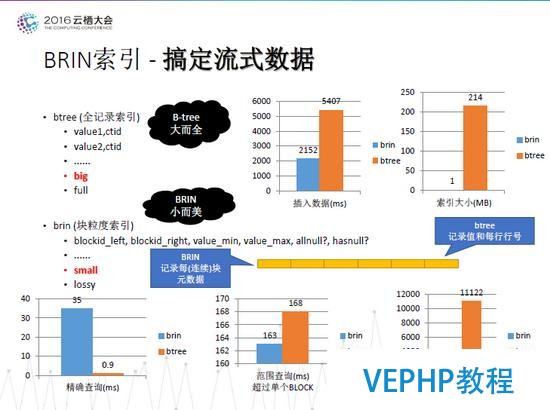
圖四 BRIN索引與B-TREE 索引性能對比
破槍式 - 搞定實時流處置

圖五 破槍式 - 搞定實時流處置
實時流處理的實時性要求很高,同時傳統的流式計算開發門檻高.但采用PostgreSQL,僅一條SQL就可以搞定流失實時處理.在數據源源不斷地往數據庫持續插入過程中,只必要定義好必要實時統計的窗口或者是流視圖,數據庫后臺就可以實時地進行數據統計.查詢流失處理結果的響應時間是在毫秒級別的.PostgreSQL在流式處理方面大大簡化了開發這一環節.其處理能力相當強大,一臺8G CPU的服務器每天能夠處理百億級別的流式數據.
破鞭式 - 搞定復雜查詢

圖六 破鞭式 - 搞定復雜查詢
在物聯網中,因為數據維度多、相關性復雜,所以復雜查詢也是一個不容忽視的問題.PostgreSQL中通過支持遺傳算法、HASH JOIN、HASH 聚合,辦理了多表查詢的效率問題,在分析場景中比傳統的嵌套循環性能提升100倍以上.
除此之外,在監測場景中,傳統基于閥值或狀態的監測方式是無法發現監測過程中存在抖動、趨勢異常的情況.PostgreSQL中采納基于方差的監測方式用于抖動檢測;同時基于時間或屬性相關性,進行趨勢檢測,防患于未然.
破索式 - 搞定數據闡發
PostgreSQL具有強大的數據挖掘才能,可以通過一條SQL搞定數據挖掘,例如:
SELECT kmeans(ARRAY[x, y, z], K) OVER , * FROM samples;
這條語句就可以實現聚類分析;同時PostgreSQL支持GPU,CPU并行計算,處理才能達到25GB/s,已經達到目前內存極限;此外PostgreSQL還兼容MADLib庫(支持幾百個機器學習庫函數、對應各種數學模型)、PL/R,、PL/Python.
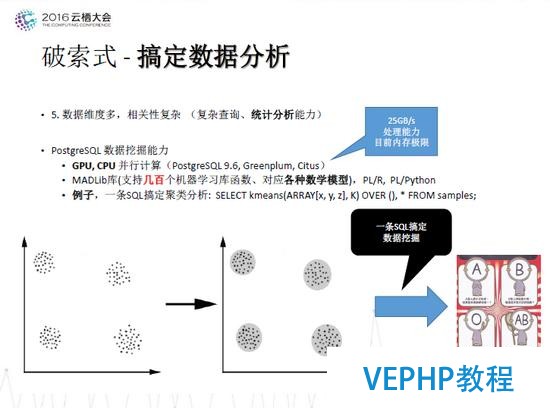
圖七 破索式 - 搞定數據闡發
破掌式 - 搞定秒殺(高并發行鎖競爭)
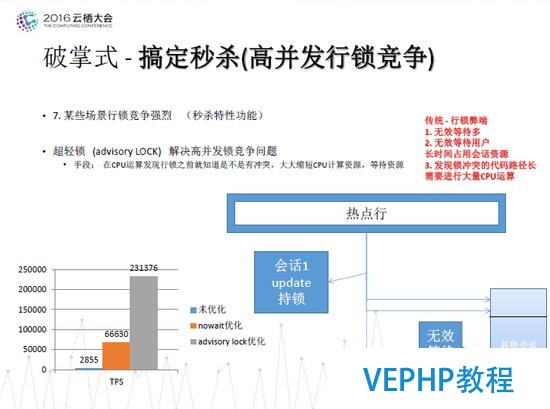
圖八 破掌式 - 搞定秒殺(高并發行鎖競爭)
在物聯網領域,例如秒殺等場景行鎖競爭強烈.傳統的行鎖具有無效等待多、無效等待用戶長時間占用會話資源、發現鎖沖突的代碼路徑長,需進行大量CPU運算等弊端.PostgreSQL提供了超輕鎖((advisory LOCK))來辦理高并發鎖競爭問題,通過CPU運算發現行鎖之前就知道是不是存在沖突,大大縮短CPU計算、等待資源,比如在秒殺搶手機的活動中,給定每個手機一個編號,拿到編號的用戶才可以進行搶手機,這樣就辦理了并行度的問題,整體性能得到了近百倍的提升.
破箭式 - 搞定模糊、正則查詢

圖九 破箭式 - 搞定模糊、正則查詢
物聯網中,對高效的模糊、相近度查詢需求,較大傳統查詢方式是采用全表掃描的方式,百億數據的查詢響應至少是小時級其余.在PostgreSQL中,通過使用GIN R-TREE索引可以將查詢時間縮短到秒級.
這里舉一個模糊查詢的例子,如上圖所示的車牌,盡管對其中一部門做了遮擋,在PostgreSQL中,通過下幾行語句,就可以輕松查出車主的個人信息:
select 'postregsql' % 'postgresql';
postgres=# select similarity('postregsql','postgresql');
similarity
------------
0.375
(1 row)
select * from tbl where info ~ '^???6888$';
select * from tbl where info ~ '^???688?$';
PostgreSQL 這一特性,也是其廣泛地用于公安刑偵、車牌、地址、郵箱等查詢中.
破氣式 - 搞定大數據處理才能

圖十 破氣式 - 搞定大數據處理才能
隨著數據量的增大,會衍生出非常多的問題.在PostgreSQL采取了以下幾種方式處置大數據:
對于單機節點,采納基于CPU和GPU的計算;
PostgreSQL 添加了FDW插件用于數據的冷熱分離,可以將數據放置在Hadoop或者Spark,通過 PostgreSQL 提供的統一拜訪接口,實現HTAP(在線與離線處理一份數據);
支持OLTP分庫分表;
支持讀寫分離、一主多備、多副本強同步;
通過級聯復制,辦理主庫壓力問題和跨機房的多份數據傳輸問題;
服務端編程能力,辦理move data帶來的網絡延遲問題;
支持多主復制,辦理物聯網地區節點和中心節點的數據相互同步問題.
接下來,針對幾個特殊的特性具體闡發下它們的實現過程:
FDW - 搞定HTAP
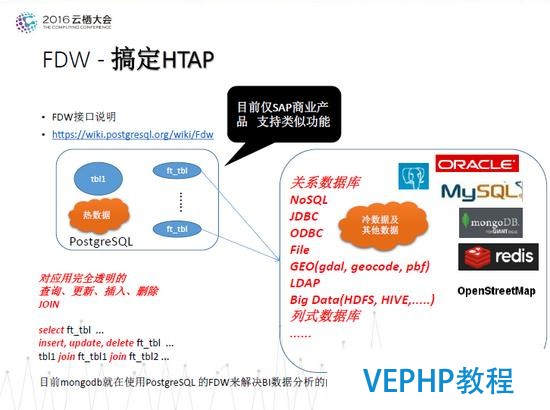
圖十一 FDW - 搞定HTAP
FDW目前僅在開源數據庫中支持;對于商用數據庫,目前僅SAP商業產品支持類似的功能.FDW可以實現數據的冷熱分離和跨界拜訪.比如,可以將熱數據存儲在PostgreSQL本地,冷數據存在Hadoop或者Spark、MySQL中,通過PostgreSQL提供的統一的接口完成數據的跨界拜訪.目前mongodb就在使用PostgreSQL 的FDW來解決BI數據分析的問題.
數據庫端編程 - 搞定網絡瓶頸

圖十二 數據庫端編程 - 搞定網絡瓶頸
在目前的硬件條件下,普通的服務器都能達到上百核,內存達到PB級別.在這種硬件設備下,一臺主機就能達到千萬級別的QPS.這樣就帶來了一個問題,在數據庫中us級別可處理的數據量,在網絡中才傳輸可能會花費ms的時間.傳統的辦理方式將業務邏輯放到應用程序端實現,然后將數據庫做的盡量簡單.現在通過PostgreSQL,可以將代碼放到數據庫端,PostgreSQL提供了C、Python、R、Perl等語言的開發接口,通過數據庫端編程辦理數據移動帶來的網絡RT瓶頸.
rank 化和相關性計算 - 搞定最強壓縮比

圖十三 rank化和相關性計算 - 搞定最強壓縮比
隨著數據量的增大,數據的存放本錢也隨之增大.PostgreSQL 中提供了列存儲、壓縮插件,可自動整理數據壓縮.
本文所提到的所有案例的詳細介紹文章鏈接如下:
JSONB 非結構化類型使用辦法
時間序列 與 流式實時處置 , 實時流式數據處置案例 ( 萬億每天 )
https://yq.aliyun.com/articles/166
地理位置信息處理才能
https://yq.aliyun.com/articles/2999
中文分詞
https://github.com/jaiminpan/pg_jieba
https://github.com/jaiminpan/pg_scws
模糊查詢,正則查詢 (1000 億級 , 5 秒內返回 )
https://yq.aliyun.com/articles/7549
BRIN 索引,非常適合帶有時序屬性的流式數據
標簽系統,例如人物畫像
秒殺 (TPS 從 2855 優化到 231376 的手段 )
https://yq.aliyun.com/articles/3010
高并發 ( 8000 個并發會話,隨機更新 500 萬記錄表中的 1 條記錄 )
https://yq.aliyun.com/articles/102
列存儲、提升壓縮比.節約 98% 空間的例子
https://yq.aliyun.com/articles/18042
結尾
針對PostgreSQL,阿里云也做了很多工作,為了便于大家使用PostgreSQL,阿里云中特推出了ApsaraDB for RDS (PG),提供7*24小時的頂級專家服務,同時也基于PostgreSQL的社區版本做了必定的優化工作.
本文根據 阿里云 飛天八部數據庫技術組技術專家德歌 在5月17日舉辦的2016云棲年夜會·武漢峰會上《 PostgreSQL數據庫之物聯網的應用 》演講整理而成.
歡迎參與《德歌:PostgreSQL獨孤九式搞定物聯網》討論,分享您的想法,維易PHP學院為您提供專業教程。
同類教程排行
- 小白入門-新手學習-網絡基礎-ms17-
- 如何找對業務G點, 體驗酸爽?Postg
- 在Kubernetes部署可用的Post
- Oracle和PostgreSQL的最新
- 針對PostgreSQL的最佳Java
- 解讀數據庫《超體》PostgreSQL
- MySQL和PostgreSQL:國內外
- 為PostgreSQL討說法:淺析Ube
- PostgreSQL測試工具PGbenc
- 白帽黑客教程2.5Metasploit中
- 當物流調度遇見PostgreSQL-機器
- go 語言操作數據庫 CRUD
- 德歌:PostgreSQL獨孤九式搞定物
- JIRA使用教程:連接數據庫-Postg
- 大數據最大難關之模糊檢索,Postgre
