從Oracle DBA到PostgreSQL布道者
《從Oracle DBA到PostgreSQL布道者》要點:
本文介紹了從Oracle DBA到PostgreSQL布道者,希望對您有用。如果有疑問,可以聯系我們。
相關主題:PostgreSQL教程
[來自IT168]
【IT168 專稿】本文根據【2016 第七屆中國數據庫技術大會】現場演講嘉賓周正中老師分享內容整理而成.錄音整理及筆墨編輯IT168@田曉旭,@老魚.
嘉賓介紹:

PostgreSQL 中國社區發起人 周正中
周正中,網名德哥 ( digoal ),PostgreSQL 中國社區發起人之一,PostgreSQL 象牙塔發起人之一,DBA+社群聯合發起人之一,10余項數據庫相關專利,曾就職于斯凱網絡,負責數據庫部門.主導了集團數據庫系統、存儲、主機、操作系統、多IDC的架構設計和建設;完成了對數據庫HA、容災、備份、恢復、分布式、數據倉庫架構設計和建設;數據庫管理和開發的尺度化體系建立.于納斯達克上市前成功使用PostgreSQL完成去O,并順利通過SOX審計.現就職于阿里云數據庫內核技術組.
正文:
大家好,本日我要給大家分享的話題是從Oracle DBA 到PostgreSQL布道者,首先先做一下自我介紹.
我是在2006、2007年開始接觸數據庫,09年的時候成為Oracle DBA,2010年,接觸到了PostergreSQL,之后就一直在做PostergreSQL的傳教工作.目前,我已經分享技術類文章2000余篇,我的目標是寫到1萬篇.

2005年,我從學校卒業拿到了我的第一份工作,是一份技術支持類的文章.為什么會去學Oracle呢?其實是有一個契機的,當時我們公司是乙方,甲方把數據庫的一些東西刪除了,數據庫就起不來了,然后Oracle的技術人員過來把數據庫恢復了.當時我就感覺真是太牛了,所以就開始接觸Oracle.

我的第一份DBA工作是在2008年,我在那家公司第一次聽到了PostgreSQL.PostgreSQL數據庫掛了之后業務還能繼續跑,它只會丟掉一部門數據,其它的數據庫還活著,可以繼續服務.Sharding是一個基于PostgreSQL的一個插件,最早是在國外流行起來的.

這家公司在之后大量使用PostgreSQL有原因的.因為在08年到09年的時候,PostergreSQL有了必定的發展,產品推陳出新,公司的業務也有了飛速的增長.下面就簡單介紹一下我們當時的應用系統.
當時我們的應用有基于地理位置的位置交友應用、社區,網游,虛擬的貨幣系統交易、游戲平臺.我們當時的數據量是普通的企業數據量,單庫的數據量是200GB到500GB,當時的服務器全是X86的機器.
在這使用的一年中,不管是從穩定性還是從性能、功能、可靠性的方面來講,PostergreSQL都滿足了我們的需求,另外我們還使用了其他數據庫所沒有的特性.
我們基于位置的交友應用,現在是有MongoDB支撐的,之前是由基于地理位置應用的插件支撐.我們的社交系統里面有比擬復雜的關系,所以會有比擬多的遞歸.如果當時我們沒有采用PostergreSQL,而是選用其它開源數據庫,恐怕是不能達到這個效果的.
當時PostergreSQL支撐了我們所有的業務應用,性能完全滿足要求,從未因數據庫問題crash,從未丟失數據,也沒有遇到bug.這也給我們之后全面應用PostergreSQL提供了信心.

2009年到2010年,我們公司準備在納斯達克上市,當時我們的商業數據庫在本錢核算方面是無法滿足上市的需求,所以當時我們CFO決定要用PostgreSQL替代商業數據庫.
如果公司上市的話,要替換本來的數據庫,就要評估這個數據庫能不能滿足上市的需求,尤其是在審計方面.
帳戶平安必須有一個密碼復雜度的詳細策略,包括用戶管理和認證管理,比如密碼的更改周期,賬戶鎖定等等.
鏈路平安,這是數據庫一定要滿足的,一般是通過鏈路加密來進行的.
數據平安,尤其是敏感數據一定要加密,加密的收到有很多,比如可以通過PostgreSQL加密的數據類型來存儲你的數據,或者是使用業務加密,把加密的階段放在業務存儲.
數據庫用戶操作審計,必要制訂內容策略,可以支持具體的業務.

開源數據庫有很多,支持的數據類型也很多.很多企業都是有特殊的業務場景的需求,不能簡單用普通數據來描述,比如基因序列或者是化學方程式這類的數據常用數據庫是沒有方法來編碼的.這時候就需要一個擴展能力強的數據庫PostgreSQL提供了非常豐富的接口,可以自己編寫數據類型,也可以基于開放的索引接口定義數據類型.
雖然分數據庫發展了這么多年,性能的差別不是特別大,但是還是有些微差距的,所以還是必要根據業務場景建模測試、工業標準測試.
代碼成熟度對于一般的用戶來說難度是很高的,這里有一個小技巧,你去看社區發布的代碼數量,就可以推測你的產物代碼成熟度.
平臺的兼容性,目前PostergreSQL是可以兼容各個平臺的.
除了以上的才能,PostergreSQL還有兩個重要的才能,一個是scale up,另一個是scale out.scale up才能主要考量的是是否能夠充分利用計算機資源.scale out才能主要是指是否支持讀寫分離,sharding.
社區的活躍度和生態也是要考慮的因素.很多公司都會忽略掉生態,其實生態是很重要的,傳統企業和互聯網企業的需求是紛歧樣的.社區的軟件開發商、數據庫的廠商以及服務的提供商,人才儲備,國家整體的軟件研發能力都要納入考量的范圍.
很多企業也是很關注案例的,他們會關注同行業的競爭對手在使用哪款數據庫產物.
學習本錢和開發本錢,如果你要獨立研究的話,這方面的支出就會很大,所以很多企業都選擇投身參與到社區中.


我為什么要做PostgreSQL布道,其實和傳教士為什么跑到偏遠的地方傳道是有必定的相互性,PostgreSQL確實是非常好的產品,我們企業也從中獲益很多,它的代碼優雅,穩定性好、性能佳、擴展性強、接口豐富等等,這么多的優點都值得我們宣揚.最主要的是當時我們成立中國用戶會的時候,中國對PostgreSQL數據庫認知非常少,酒香巷子深,從現在看,也證明了我們當時的選擇是沒有錯的.
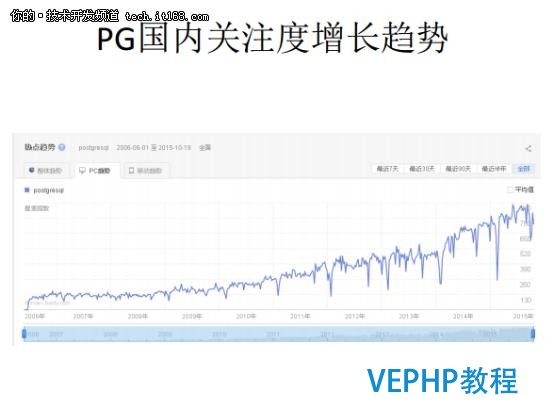
PG在國內關注的增長趨勢是在往上走的.
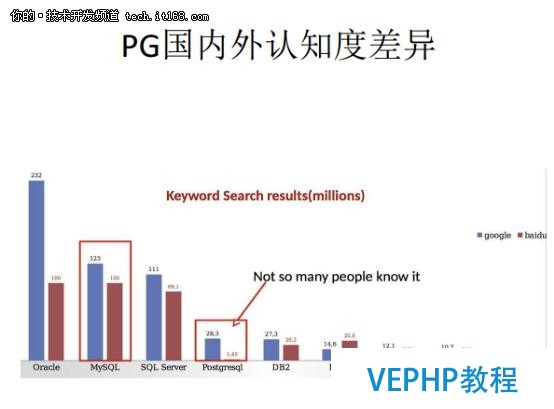
百度的搜索指數代表中國市場,谷歌的搜索指數代表國際市場,從全球的角度來看,中國市場對PostgreSQL的認知和國外市場還有必定的差距.

國內的用戶沒有聽說過PostgreSQL,那么就會對PostgreSQL充滿疑問.例如它的性能怎么樣,它能管理多大的數據量,它能不克不及用好硬件資源,使用哪些方式來提升我的性能,以及和其它的數據庫相比有哪些優缺點.以上疑問都是我們布道者要做的工作.
接下來給大家來遍及幾個PostgreSQL的案例,可能會顛覆大家對數據庫產品的認知.
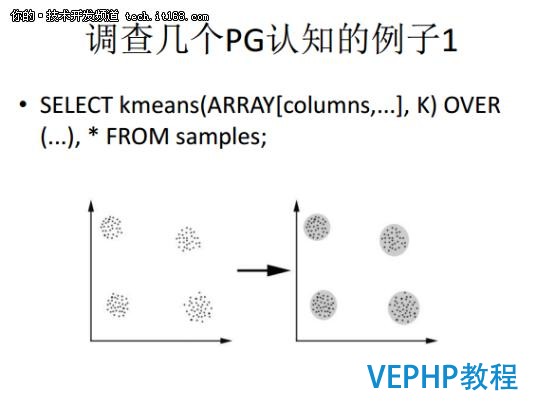
第一個例子,我們看這個圖,從左邊到右邊是一個數據聚集的過程,這個在數據分析或者數據挖掘領域是非常常見的案例.好比說我對一些用戶的行為做分類,在PG里面可以通過kmeans做到.

實時計算某WEB站點的哀求延遲, 90%的哀求低于多少毫秒, 95%的哀求低于多少毫秒,99%的哀求低于多少毫秒.這個的處理方法也是很簡單,數據采集到性能數據,我只要建一個模式統計就可以了.除此之外,在加一個窗口查詢,就能得到我們想要的結果.

第三個例子,我在數據庫里面能不克不及做多元的信息反饋,這個在數據倉庫或者是一些BI系統里面也是非常常見的,但是在關系型數據庫里是不常見的.P元線性回歸,通過圖上的公式求得截距和斜率,然后就可以預測yn.

這里用到linregr訓練辦法,訓練source_table然后放到out_table里,通過這樣的一個函數就可以解決這樣的應用需求.
除了剛剛舉的例子之外,madlib庫還有很多作用,它將很多東西封裝成了函數,通過這些函數就能夠實現深度學習的某些東西.

第四個例子顛覆了大家對數據類型的理解,大家可能認為數據庫只能存儲long、int、text這類的數據,實際上數據庫還可以存儲更多的數據類型.好比范圍搜索的數據,可能在傳統數據庫里面是兩個字段,startvalue和endvalue,但是在PostgreSQL只需存儲一個字段,就可以表示一個數據范圍,甚至就可以建索引.這個索引是基于range建立的,在做范圍搜索的時候查詢效益非常高.
下面是一個查詢效益差其余對比.
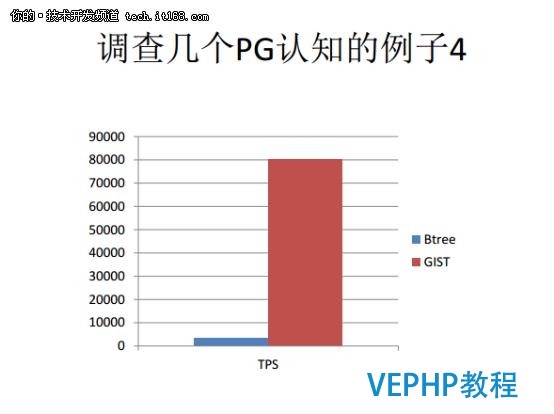

第五個例子是一個流式數據的應用場景.這個應用場景在物聯網的大配景下的用戶需求也是非常大的.這種場景有兩個特點,第一個特點是大量的數據積累,第二個是要基于時間分析.

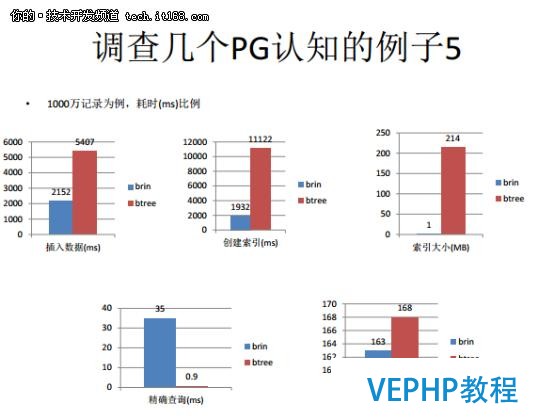
我們以往是使用Btree索引來實現的,我們發現數據量是非常龐大的,執行效率并不是很高.后來我們采納了BRIN的索引.
下圖是兩種索引性能差別的對比.
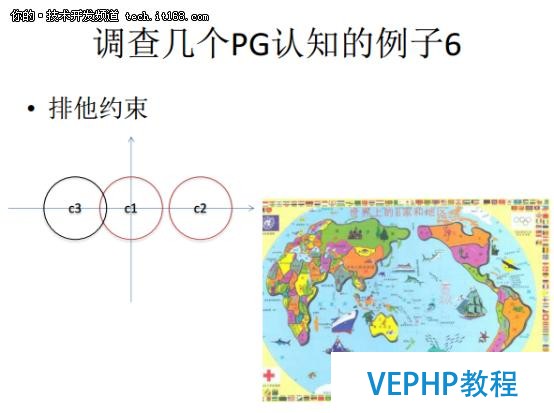
第六個例子是排他約束,排他約束和唯一約束也是相關的,唯一約束是根據排他約束來建立的.
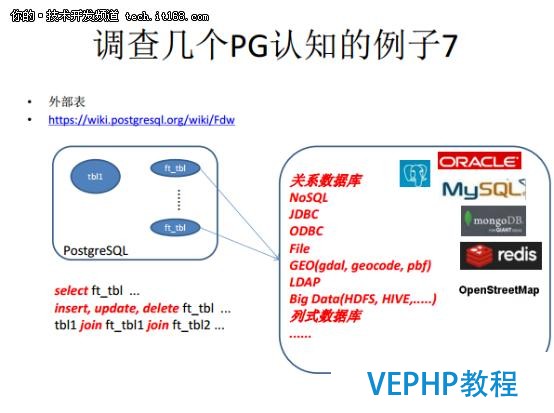
第七個例子是外部表,PostgreSQL通過接口連接到后端的數據源,數據源的類型十分多樣化.
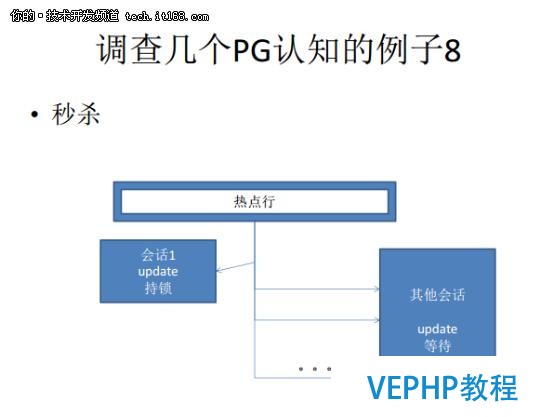
第八個例子是秒殺,這里講的是PostgreSQL自帶的一個類似于自選鎖的功能,這個鎖是非常短暫,用于秒殺的網站的話,能夠提升近百倍的性能.
所謂布道不僅僅只是分享案例,還包括貢獻核心代碼、review代碼、報告BUG、開發插件、開發驅動、維護打包程序(bin,rpm,deb....)、port流行的軟件到PostgreSQL、開發支持PostgreSQL的程序、翻譯文檔、維護官網手冊和插件手冊、維護HOWTO、維護遷移guide(mysql,oracle,infomix,sqlserver,....to PostgreSQL)、分享文檔、寫書、寫博客、組織用戶會議、贊助其他用戶、測試patch、測試性能等等.

PostgreSQL是從伯克利寫的 POSTGRES 軟件包發展而來,在1995年的時候有了社區管理的概念,目前PostgreSQL的大版本更新幾乎是一年一迭代.
PostgreSQL的代碼活躍度做的也是比擬好,比如我提交一個代碼,里面會有代碼審核,告訴你哪有問題,然后針對性的修改代碼.

上圖是PostgreSQL近幾年的里程碑,我們可以看到每一年新版本的發布都有分歧的東西.很多功能的實現都是一次次迭代出來的.

本次測試模型選用的PostgreSQL的8.4到9.5版本,數據量為305GB,測試結果發現各個版本的性能差別不是特別大,原因是IO的瓶頸.

第二次測試我們采納的是一億的數據量,數據全部在內存中,考量的是數據庫的代碼效率,我們看到從8.4到9.5,性能幾乎翻了一倍.

這是另外一個場景,一共有64張表,每張表有1000萬的數據,64個并發連續壓測2個小時,壓測結果大家可以參考上圖.

自從我們成立中國用戶會以后,我們中國的用戶發生了非常巨大的變化.之前我了解到幾乎沒有公司在使用PostgreSQL,但是我們現在看,已經有這么多的公司都在用PostgreSQL,并且很多是國字頭的.我們可以看到PostgreSQL在中國發展勢頭非常好.

整個PostgreSQL社區的核心成員是六個,主要貢獻者有40多個.PostgreSQL在中國的發張最早可以追溯到1999年,那時我們只是在做一些文檔的推廣,直到2011年PostgreSQL社區成立,這期間是完全沒有社區的概念.現在,我們每年會在各地舉辦會議、會有免費的DBA培訓,也會和高效合作項目.用戶會把整個生態的用戶、企業集合起來,大家一起把這個產物做好.
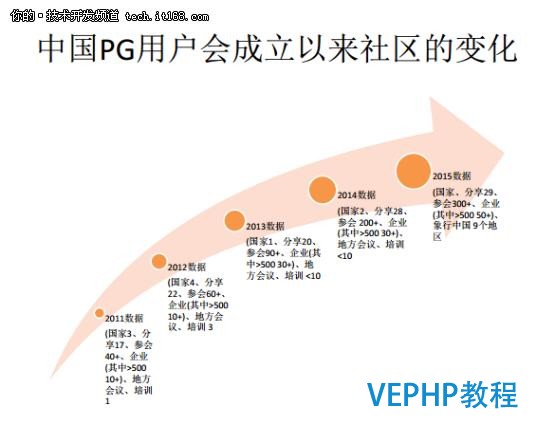
我們看一下截止到現在,社區發生什么變化.目前整個社區在中國大概有超過一萬的人員,研發人員超過三百個.為什么說研發人員的占比這么少呢?因為PostgreSQL數據庫的開源協議是BSD,你把PostgreSQL數據庫拿過來一行代碼不改,可以直接包裝成本身的產品拿去售賣,但如果你把MySQL數據拿過來一行代碼不改直接使用是要追究你的法律責任的.
用戶會的主要工作是維持生態,當然也會有很多文檔翻譯,案例分享,主持會議,聯合其它的社區一起來推動PostgreSQL等等的工作來做.從用戶會參會來看,基本上已經接近十倍的增長.

學習任何一個產品都是多實踐、多分享、有問題多翻手冊和源碼、多和社區小伙伴交流,開源的產品可以參與到社區中,這時你會發現你要成為一個PostgreSQL DBA花費的時間本錢不是很多,比如說你是一個有一定數據庫基礎的DBA,你花一個月時間去學,肯定沒問題.如果你是有Linux管理基礎的SA或者是有服務端開發經驗的開發人員,那么差不多需要三個月.如果你是完全沒有基礎,半年的時間你基本也可以上手了.

最后是給大家分享一下我對PostgreSQL市場的判斷.商業數據庫這塊主要憑借PostgreSQL BSD許可,其實有很多國產數據庫是基于PostgreSQL,另一塊是MPP DB市場,有超過一半的MPP數據庫是基于PostgreSQL,好比Greenplum、Deepgreen、redshift、PG-XL、ASTERDATA、ParStream、ParAccel等等,如果大家有興趣或者是有很好的渠道,可以考慮一下MPP PostgreSQL.高校方向主要是科研.公有云市場也大有可為,好比上云、中間件、培訓等等.其實現在在國內還沒有一家做PostgreSQL的培訓,這是空白的市場,發展空間巨大,大家可以去嘗試.

阿里云的ApsaraDB PostgreSQL團隊擁有很多PG源碼專家,我們基于PostgreSQL做了很多優化,另外還提供一個高度兼容Oracle的產物PPAS.
歡迎參與《從Oracle DBA到PostgreSQL布道者》討論,分享您的想法,維易PHP學院為您提供專業教程。
