獨(dú)家|一文讀懂Apache Kudu
《獨(dú)家|一文讀懂Apache Kudu》要點(diǎn):
本文介紹了獨(dú)家|一文讀懂Apache Kudu,希望對您有用。如果有疑問,可以聯(lián)系我們。
相關(guān)主題:apache配置
維易PHP培訓(xùn)學(xué)院每天發(fā)布《獨(dú)家|一文讀懂Apache Kudu》等實(shí)戰(zhàn)技能,PHP、MYSQL、LINUX、APP、JS,CSS全面培養(yǎng)人才。

前言
Apache Kudu是由Cloudera開源的存儲引擎,可以同時(shí)提供低延遲的隨機(jī)讀寫和高效的數(shù)據(jù)分析能力.Kudu支持水平擴(kuò)展,使用Raft協(xié)議進(jìn)行一致性保證,并且與Cloudera Impala和Apache Spark等當(dāng)前流行的大數(shù)據(jù)查詢和分析工具結(jié) 合緊密.本文將為您介紹Kudu的一些基本概念和架構(gòu)以及在企業(yè)中的應(yīng)用,使您對Kudu有一個(gè)較為全面的了解.
一、為什么需要Kudu
Kudu這個(gè)名字聽起來可能有些奇怪,實(shí)際上,Kudu是一種非洲的大羚羊,中文名叫“捻角羚”,就是下圖這個(gè)樣子:

比擬有意思的是,同為Cloudera公司開源的另一款產(chǎn)品Impala,是另一種非洲的羚羊,叫做“黑斑羚”,也叫“高角羚”.不知道Cloudera公司為什么這么喜歡羚羊,也許是因?yàn)榱缪虻乃俣瓤彀?
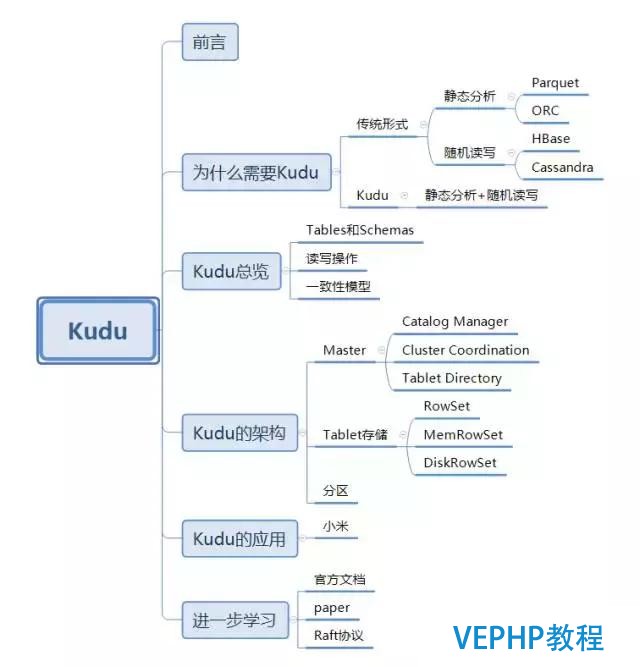
言歸正傳,現(xiàn)在提起大數(shù)據(jù)存儲,我們能想到的技術(shù)有很多,比如HDFS,以及在HDFS上的列式存儲技術(shù)Apache Parquet,Apache ORC,還有以KV形式存儲半結(jié)構(gòu)化數(shù)據(jù)的Apache HBase和Apache Cassandra等等.既然有了如此多的存儲技術(shù),Cloudera公司為什么要開發(fā)出一款全新的存儲引擎Kudu呢?
事實(shí)上,當(dāng)前的這些存儲技術(shù)都存在著一定的局限性.對于會被用來進(jìn)行分析的靜態(tài)數(shù)據(jù)集來說,使用Parquet或者ORC存儲是一種明智的選擇.但是目前的列式存儲技術(shù)都不能更新數(shù)據(jù),而且隨機(jī)讀寫性能感人.而可以進(jìn)行高效隨機(jī)讀寫的HBase、Cassandra等數(shù)據(jù)庫,卻并不適用于基于SQL的數(shù)據(jù)分析方向.
所以現(xiàn)在的企業(yè)中,經(jīng)常會存儲兩套數(shù)據(jù)分別用于實(shí)時(shí)讀寫與數(shù)據(jù)分析,先將數(shù)據(jù)寫入HBase中,再定期通過ETL到Parquet進(jìn)行數(shù)據(jù)同步.但是這樣做有很多缺點(diǎn):
用戶需要在兩套系統(tǒng)間編寫和維護(hù)復(fù)雜的ETL邏輯.
時(shí)效性較差.因?yàn)镋TL通常是一個(gè)小時(shí)、幾個(gè)小時(shí)甚至是一天一次,那么可供分析的數(shù)據(jù)就需要一個(gè)小時(shí)至一天的時(shí)間后才進(jìn)入到可用狀態(tài),也就是說從數(shù)據(jù)到達(dá)到可被分析之間是會存在一個(gè)較為明顯的“空檔期”的.
更新需求難以滿足.在實(shí)際情況中可能會有一些對已經(jīng)寫入的數(shù)據(jù)的更新需求,這種情況往往需要對歷史數(shù)據(jù)進(jìn)行更新,而對Parquet這種靜態(tài)數(shù)據(jù)集的更新操作,代價(jià)是非常昂貴的.
存儲資源浪費(fèi).兩套存儲系統(tǒng)意味著占用的磁盤資源翻倍了,造成了本錢的提升.
我們知道,基于HDFS的存儲技術(shù),比如Parquet,具有高吞吐量連續(xù)讀取數(shù)據(jù)的能力;而HBase和Cassandra等技術(shù)適用于低延遲的隨機(jī)讀寫場景,那么有沒有一種技術(shù)可以同時(shí)具備這兩種優(yōu)點(diǎn)呢?Kudu提供了一種“happy medium”的選擇:
Kudu不但提供了行級的插入、更新、刪除API,同時(shí)也提供了接近Parquet性能的批量掃描操作.使用同一份存儲,既可以進(jìn)行隨機(jī)讀寫,也可以滿足數(shù)據(jù)分析的要求.
二、Kudu總覽
Tables和Schemas
從用戶角度來看,Kudu是一種存儲結(jié)構(gòu)化數(shù)據(jù)表的存儲系統(tǒng).在一個(gè)Kudu集群中可以定義任意數(shù)量的table,每個(gè)table都需要預(yù)先定義好schema.每個(gè)table的列數(shù)是確定的,每一列都需要有名字和類型,每個(gè)表中可以把其中一列或多列定義為主鍵.這么看來,Kudu更像關(guān)系型數(shù)據(jù)庫,而不是像HBase、Cassandra和MongoDB這些NoSQL數(shù)據(jù)庫.不過Kudu目前還不能像關(guān)系型數(shù)據(jù)一樣支持二級索引. Kudu使用確定的列類型,而不是類似于NoSQL的“everything is byte”.這可以帶來兩點(diǎn)好處:
確定的列類型使Kudu可以進(jìn)行類型特有的編碼.
可以提供 SQL-like 元數(shù)據(jù)給其他上層查詢工具,比如BI工具.
讀寫操作
用戶可以使用 Insert,Update和Delete API對表進(jìn)行寫操作.不論使用哪種API,都必須指定主鍵.但批量的刪除和更新操作需要依賴更高層次的組件(比如Impala、Spark).Kudu目前還不支持多行事務(wù). 而在讀操作方面,Kudu只提供了Scan操作來獲取數(shù)據(jù).用戶可以通過指定過濾條件來獲取本身想要讀取的數(shù)據(jù),但目前只提供了兩種類型的過濾條件:主鍵范圍和列值與常數(shù)的比較.由于Kudu在硬盤中的數(shù)據(jù)采用列式存儲,所以只掃描需要的列將極大地提高讀取性能.
一致性模型
Kudu為用戶提供了兩種一致性模型.默認(rèn)的一致性模型是snapshot consistency.這種一致性模型保證用戶每次讀取出來的都是一個(gè)可用的快照,但這種一致性模型只能保證單個(gè)client可以看到最新的數(shù)據(jù),但不能保證多個(gè)client每次取出的都是最新的數(shù)據(jù).
另一種一致性模型external consistency可以在多個(gè)client之間保證每次取到的都是最新數(shù)據(jù),但是Kudu沒有提供默認(rèn)的實(shí)現(xiàn),需要用戶做一些額外工作.
為了實(shí)現(xiàn)external consistency,Kudu提供了兩種方式:
在client之間傳播timestamp token.在一個(gè)client完成一次寫入后,會得到一個(gè)timestamp token,然后這個(gè)client把這個(gè)token傳播到其他client,這樣其他client就可以通過token取到最新數(shù)據(jù)了.不過這個(gè)方式的復(fù)雜度很高.
通過commit-wait方式,這有些類似于Google的Spanner.但是目前基于NTP的commit-wait方式延遲實(shí)在有點(diǎn)高.不過Kudu相信,隨著Spanner的出現(xiàn),未來幾年內(nèi)基于real-time clock的技術(shù)將會逐漸成熟.
三、Kudu的架構(gòu)
與HDFS和HBase相似,Kudu使用單個(gè)的Master節(jié)點(diǎn),用來管理集群的元數(shù)據(jù),并且使用任意數(shù)量的Tablet Server節(jié)點(diǎn)用來存儲實(shí)際數(shù)據(jù).可以部署多個(gè)Master節(jié)點(diǎn)來提高容錯(cuò)性.
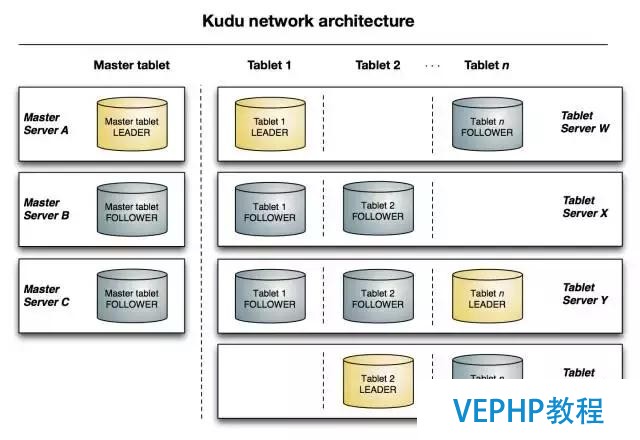
Master
Kudu的master節(jié)點(diǎn)負(fù)責(zé)整個(gè)集群的元數(shù)據(jù)管理和服務(wù)協(xié)調(diào).它承擔(dān)著以下功能:
作為catalog manager,master節(jié)點(diǎn)管理著集群中所有table和tablet的schema及一些其他的元數(shù)據(jù).
作為cluster coordinator,master節(jié)點(diǎn)追蹤著所有server節(jié)點(diǎn)是否存活,并且當(dāng)server節(jié)點(diǎn)掛掉后協(xié)調(diào)數(shù)據(jù)的重新分布.
作為tablet directory,master跟蹤每個(gè)tablet的位置.
Catalog Manager
Kudu的master節(jié)點(diǎn)會持有一個(gè)單tablet的table——catalog table,但是用戶是不能直接拜訪的.master將內(nèi)部的catalog信息寫入該tablet,并且將整個(gè)catalog的信息緩存到內(nèi)存中.隨著現(xiàn)在商用服務(wù)器上的內(nèi)存越來越大,并且元數(shù)據(jù)信息占用的空間其實(shí)并不大,所以master不容易存在性能瓶頸.catalog table保存了所有table的schema的版本以及table的狀態(tài)(創(chuàng)建、運(yùn)行、刪除等).
Cluster Coordination
Kudu集群中的每個(gè)tablet server都需要配置master的主機(jī)名列表.當(dāng)集群啟動時(shí),tablet server會向master注冊,并發(fā)送所有tablet的信息.tablet server第一次向master發(fā)送信息時(shí)會發(fā)送所有tablet的全量信息,后續(xù)每次發(fā)送則只會發(fā)送增量信息,僅包括新創(chuàng)建、刪除或修改的tablet的信息. 作為cluster coordination,master只是集群狀態(tài)的觀察者.對于tablet server中tablet的副本位置、Raft配置和schema版本等信息的控制和修改由tablet server自身完成.master只需要下發(fā)命令,tablet server執(zhí)行成功后會自動上報(bào)處理的結(jié)果.
Tablet Directory
因?yàn)閙aster上緩存了集群的元數(shù)據(jù),所以client讀寫數(shù)據(jù)的時(shí)候,肯定是要通過master才能獲取到tablet的位置等信息.但是如果每次讀寫都要通過master節(jié)點(diǎn)的話,那master就會變成這個(gè)集群的性能瓶頸,所以client會在本地緩存一份它需要拜訪的tablet的位置信息,這樣就不用每次讀寫都從master中獲取. 因?yàn)閠ablet的位置可能也會發(fā)生變化(比如某個(gè)tablet server節(jié)點(diǎn)crash掉了),所以當(dāng)tablet的位置發(fā)生變化的時(shí)候,client會收到相應(yīng)的通知,然后再去master上獲取一份新的元數(shù)據(jù)信息.
Tablet存儲
在數(shù)據(jù)存儲方面,Kudu選擇完全由本身實(shí)現(xiàn),而沒有借助于已有的開源方案.tablet存儲主要想要實(shí)現(xiàn)的目標(biāo)為:
快速的列掃描
低延遲的隨機(jī)讀寫
一致性的性能
RowSets
在Kudu中,tablet被細(xì)分為更小的單元,叫做RowSets.一些RowSet僅存在于內(nèi)存中,被稱為MemRowSets,而另一些則同時(shí)使用內(nèi)存和硬盤,被稱為DiskRowSets.任何一行未被刪除的數(shù)據(jù)都只能存在于一個(gè)RowSet中. 無論任何時(shí)候,一個(gè)tablet僅有一個(gè)MemRowSet用來保留最新插入的數(shù)據(jù),并且有一個(gè)后臺線程會定期把內(nèi)存中的數(shù)據(jù)flush到硬盤上. 當(dāng)一個(gè)MemRowSet被flush到硬盤上以后,一個(gè)新的MemRowSet會替代它.而原有的MemRowSet會變成一到多個(gè)DiskRowSet.flush操作是完全同步進(jìn)行的,在進(jìn)行flush時(shí),client同樣可以進(jìn)行讀寫操作.
MemRowSet
MemRowSets是一個(gè)可以被并發(fā)拜訪并進(jìn)行過鎖優(yōu)化的B-tree,主要是基于MassTree來設(shè)計(jì)的,但存在幾點(diǎn)不同:
Kudu并不支持直接刪除操作,由于使用了MVCC,所以在Kudu中刪除操作其實(shí)是插入一條標(biāo)志著刪除的數(shù)據(jù),這樣就可以推遲刪除操作.
類似刪除操作,Kudu也不支持原地更新操作.
將tree的leaf鏈接起來,就像B+-tree.這一步關(guān)鍵的操作可以明顯地提升scan操作的性能.
沒有實(shí)現(xiàn)字典樹(trie樹),而是只用了單個(gè)tree,因?yàn)镵udu并不適用于極高的隨機(jī)讀寫的場景.
與Kudu中其他模塊中的數(shù)據(jù)結(jié)構(gòu)不同,MemRowSet中的數(shù)據(jù)使用行式存儲.因?yàn)閿?shù)據(jù)都在內(nèi)存中,所以性能也是可以接受的,而且Kudu對在MemRowSet中的數(shù)據(jù)結(jié)構(gòu)進(jìn)行了一定的優(yōu)化.
DiskRowSet
當(dāng)MemRowSet被flush到硬盤上,就變成了DiskRowSet.當(dāng)MemRowSet被flush到硬盤的時(shí)候,每32M就會形成一個(gè)新的DiskRowSet,這主要是為了保證每個(gè)DiskRowSet不會太大,便于后續(xù)的增量compaction操作.Kudu通過將數(shù)據(jù)分為base data和delta data,來實(shí)現(xiàn)數(shù)據(jù)的更新操作.Kudu會將數(shù)據(jù)按列存儲,數(shù)據(jù)被切分成多個(gè)page,并使用B-tree進(jìn)行索引.除了用戶寫入的數(shù)據(jù),Kudu還會將主鍵索引存入一個(gè)列中,并且提供布隆過濾器來進(jìn)行高效查找.
Compaction
為了提高查詢性能,Kudu會定期進(jìn)行compaction操作,合并delta data與base data,對標(biāo)記了刪除的數(shù)據(jù)進(jìn)行刪除,并且會合并一些DiskRowSet.
分區(qū)
和許多分布式存儲系統(tǒng)一樣,Kudu的table是水平分區(qū)的.BigTable只提供了range分區(qū),Cassandra只提供hash分區(qū),而Kudu提供了較為靈活的分區(qū)方式.當(dāng)用戶創(chuàng)建一個(gè)table時(shí),可以同時(shí)指定table的的partition schema,partition schema會將primary key映射為partition key.一個(gè)partition schema包含0到多個(gè)hash-partitioning規(guī)則和一個(gè)range-partitioning規(guī)則.通過靈活地組合各種partition規(guī)則,用戶可以創(chuàng)造適用于自己業(yè)務(wù)場景的分區(qū)方式.
四、Kudu的應(yīng)用
Kudu的應(yīng)用場景很廣泛,比如可以進(jìn)行實(shí)時(shí)的數(shù)據(jù)分析,用于數(shù)據(jù)可能會存在變化的時(shí)序數(shù)據(jù)應(yīng)用等,甚至還有人探討過使用Kudu替代Kafka的可行性(詳情請戳 http://blog.rodeo.io/2016/01/24/kudu-as-a-more-flexible-kafka.html).不過Kudu最有名和最成功的應(yīng)用案例,還是國內(nèi)的小米.小米公司不僅使用Kudu,還深度參與了Kudu的開發(fā).Kudu項(xiàng)目在2012年10月由Cloudera公司發(fā)起,2015年10月對外頒布,2015年12月進(jìn)入Apache孵化器,但是小米公司早在2014年9月就加入到Kudu的開發(fā)中了. 下面我們可以跟隨Cloudera在宣傳Kudu時(shí)使用的ppt來看一看Kudu在小米的使用.

從上圖中我們可以看到,Kudu在小米主要用來對手機(jī)app和后端服務(wù)的RPC調(diào)用事件進(jìn)行追蹤,以及對服務(wù)進(jìn)行監(jiān)控.在小米的使用場景下,Kudu集群已經(jīng)達(dá)到每天200億次寫入,并且還在增長. Kudu除了優(yōu)秀的性能,更為重要的是可以簡化數(shù)據(jù)處理的流程.
在使用Kudu以前,小米的數(shù)據(jù)處理流程是這樣的:
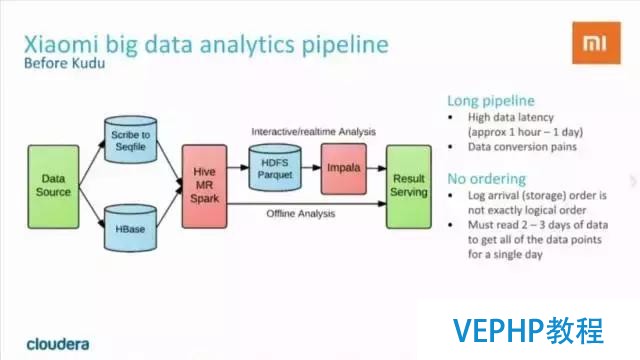
可以看到,數(shù)據(jù)處理的流程很長.這種處理模式不但較為復(fù)雜,而且latency較高,通常需要等待較長的時(shí)間(1 hour - 1day)才能得到分析結(jié)果.
下面再來看看使用Kudu以后的數(shù)據(jù)處理流程是怎樣的:
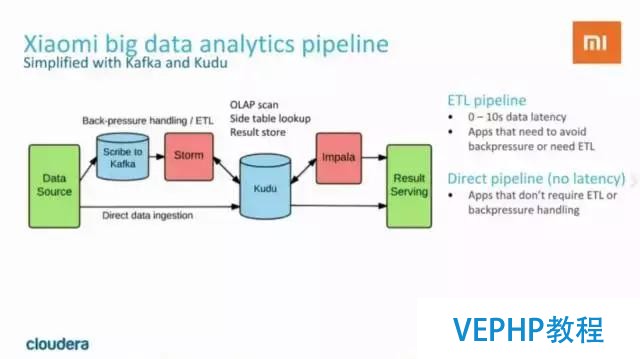
使用Kudu以后,數(shù)據(jù)處理的鏈路被簡化了,而且得益于Kudu對隨機(jī)讀寫和數(shù)據(jù)分析操作的支持都很好,可以直接對Kudu中的數(shù)據(jù)進(jìn)行交互式分析,降低了系統(tǒng)復(fù)雜度,并且latency被大大縮短(0 ~ 10s).
五、進(jìn)一步學(xué)習(xí)
如果您看了本文的介紹后想進(jìn)一步學(xué)習(xí)Kudu,以下途徑可以贊助您快速入門:
Documentation(http://kudu.apache.org/docs/),官方文檔永遠(yuǎn)是學(xué)習(xí)開源項(xiàng)目的最好去處.
Paper(http://kudu.apache.org/kudu.pdf),Kudu的論文可以贊助您深入了解Kudu的設(shè)計(jì)思想.
Raft協(xié)議(https://raft.github.io/),雖然不屬于Kudu的內(nèi)容,但是Kudu的一致性協(xié)議使用了Raft協(xié)議,了解Raft協(xié)議可以贊助您更好地了解Kudu及其他分布式開源系統(tǒng).
Apache Kudu as a More Flexible And Reliable Kafka-style Queue (http://blog.rodeo.io/2016/01/24/kudu-as-a-more-flexible-kafka.html),
這篇博客也許能對您在如何使用Kudu的問題上有一些啟發(fā).
比擬遺憾的是,由于Kudu還很年輕,所以并沒有比擬好的相關(guān)書籍出版.計(jì)算機(jī)是一門實(shí)踐性較強(qiáng)的學(xué)科,所以動手實(shí)踐是成為Kudu專家的必經(jīng)之路:github地址(https://github.com/apache/kudu).
轉(zhuǎn)載請注明本頁網(wǎng)址:
http://www.fzlkiss.com/jiaocheng/11768.html
同類教程排行
- apache常用配置指令說明
- Hive實(shí)戰(zhàn)—通過指定經(jīng)緯度點(diǎn)找出周圍的
- Apache2.2之httpd.conf
- apache怎么做rewrite運(yùn)行th
- 獨(dú)家|一文讀懂Apache Kudu
- Apache 崩潰解決 -- 修改堆棧大
- Apache 個(gè)人主頁搭建
- Apache OpenWhisk架構(gòu)概述
- Apache自動跳轉(zhuǎn)到 HTTPS
- 深入理解Apache Flink核心技術(shù)
- Apache Kylin查詢性能優(yōu)化
- Apache Flume 大數(shù)據(jù)ETL工
- Apache Flink異軍突起受歡迎!
- apache常見錯(cuò)誤代碼
- Apache MADlib成功晉升為Ap
