Apache Flink異軍突起受歡迎!
《Apache Flink異軍突起受歡迎!》要點:
本文介紹了Apache Flink異軍突起受歡迎!,希望對您有用。如果有疑問,可以聯系我們。
歡迎參與《Apache Flink異軍突起受歡迎!》討論,分享您的想法,維易PHP學院為您提供專業教程。
大數據產業興盛期,說到大數據分析引擎,不少人第一時間會想起Spark、Impala等,然而,作為Apache頂級項目的Flink也是不少企業的選擇.它到底有什么優勢呢?和Spark相比擬,它有什么更可取之處呢?且聽大圣眾包威客平臺一一道來.

一、寶劍露鋒芒——Apache Flink
作為Apache的頂級項目,Flink固然集眾多優點于一身,包含快速、可靠可擴展、完全兼容Hadoop、使用簡便、表現卓越.
1.快速
快,是Flink的主要特點.利用基于內存的數據流,并將迭代處置算法深度集成到系統的運行時中,這樣,Flink使得系統能夠以極快的速度處置數據密集型和迭代任務.
2.可靠、可擴展
得益于Flink包括自己的內存管理組件、序列化框架和類型推理引擎,所以,即使服務器內存被耗盡,Flink也能夠很好地運行.
3.完全兼容Hadoop
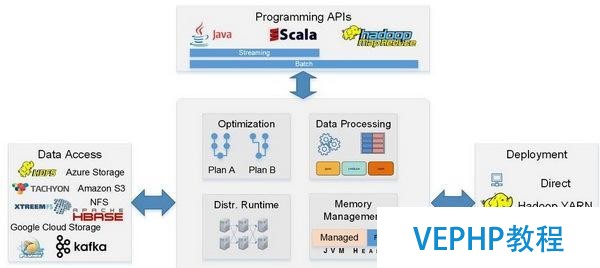
為什么開發者無需做任何修改,就能利用Flink運行歷史遺留的MapReduce操作?這是因為Flink支持所有Hadoop的所有輸入/輸出格式和數據類型.另外,Flink包含基于Java和Scala的用于批量和基于流數據分析的API、優化器和具有自定義內存管理功能的分布式運行時等,這也是它能夠完全兼容Hadoop的原因之一.
4.易用
讓人感到驚喜的是,在無需進行任何配置的情況下,Flink內置的優化器就能夠以最高效的方式在各種環境中執行程序.只必要三個命令,Flink就可以運行在Hadoop的新MapReduce框架Yarn上.
5.表示卓越
作為一款優秀的大數據分析引擎,Flink能夠利用Java或者Scala語言編寫出漂亮、類型平安和可為核心的代碼,并能夠在集群上運行所寫程序.這樣,使得開發者可以在無需額外處理的情況下使用Java和Scala數據類型.
一言以蔽之,ApacheFlink具有分布式MapReduce一類平臺的高效性、靈活性和擴展性,以及并行數據庫查詢優化方案,同時,它還支持批量和基于流的數據分析,并且提供了基于Java和Scala的API.總的來說,Flink是一個高效的、分布式的、基于Java實現的通用大數據分析引擎.
二、雙鋒互切磋——Apache Spark與Apache Flink
同樣作為流處理引擎,盡管ApacheSpark在大數據處理運用中已經十分著名,然而,沒有一款工具能夠處理所有問題.在一些特殊的情況下,ApacheFlink可能很好地彌補了ApacheSpark所未能涵蓋的地方.那么,應該選哪一款作為企業的大數據分析引擎呢?我們可以通過兩者的異同比擬,做出最優選擇.
相同之處:
1.兩者都能提供恰好一次的保證,即每條記錄都僅處置一次;
2.與其他處理系統(好比Storm)相比,它們都能提供一個非常高的吞吐量;
3.兩者都能夠提供自動內存管理;
4.它們的容錯開銷都非常低.
分歧之處:
事實上,ApacheSpark和ApacheFlink的主要差別,就在于計算模型不同.所以,對于選擇ApacheSpark,還是ApacheFlink的問題上,實際上就釀成了計算模型的選擇.

要了解ApacheSpark與ApacheFlink的相異之處,首先要對如下三種計算模型有一個初步的理解:
批處置——基本上處置靜態數據,一次讀入大量數據進行處置并生成輸出.
微批處理——結合了批處理和持續流操作符,將輸入分成多個微批次進行處理,從根本上講,微批處理是一個“收集然后處理”的計算模型.
持續流操作符——在數據到達時進行處理,沒有任何數據收集或處理延遲.
實際中,Spark采用的是微批處理模型,而Flink采用的是基于操作符的連續流模型.隨著數據處理能力的提高,企業開始認識到,信息的價值在數據產生的時候最高,他們希望在數據產生時處理數據,這就是說需要一個實時處理系統.當需要實時處理時,可以優先選擇ApacheFlink.但也不是所有情況都需要實時系統,這時,ApacheSpark則是更優的選擇.好比,在電信行業,統計特定用戶使用的帶寬,微批處理可能是一個更高效的方案.
至于具體應該怎么選,必要企業在延遲、吞吐量和可靠性等多個方面上去進行權衡.
縱使科技日新月異,然而,適合的,才是最好的.
(更多年夜數據與商業智能領域干貨、或電子書,可添加個人微信號(dashenghuaer))
