細(xì)數(shù)5款主流NoSQL數(shù)據(jù)庫(kù)到底哪家強(qiáng)?
《細(xì)數(shù)5款主流NoSQL數(shù)據(jù)庫(kù)到底哪家強(qiáng)?》要點(diǎn):
本文介紹了細(xì)數(shù)5款主流NoSQL數(shù)據(jù)庫(kù)到底哪家強(qiáng)?,希望對(duì)您有用。如果有疑問(wèn),可以聯(lián)系我們。
最近小組準(zhǔn)備啟動(dòng)一個(gè) node 開(kāi)源項(xiàng)目,從前端親和力、大數(shù)據(jù)下的IO性能、可擴(kuò)展性幾點(diǎn)入手挑選了 NoSQL 數(shù)據(jù)庫(kù),但具體使用哪一款產(chǎn)品還必要做一次選型.
我們最終把選項(xiàng)范圍縮窄在 HBase、Redis、MongoDB、Couchbase、LevelDB 五款較主流的數(shù)據(jù)庫(kù)產(chǎn)物中,本文將主要對(duì)它們進(jìn)行分析對(duì)比.
鑒于缺乏項(xiàng)目中的實(shí)戰(zhàn)經(jīng)驗(yàn)沉淀,本文內(nèi)容和觀點(diǎn)主要是從各平臺(tái)資料包羅匯總,所引用的資料來(lái)源將示于文末.所匯總的內(nèi)容僅供參考,若有異議望指正.
HBase
HBase 是 Apache Hadoop 中的一個(gè)子項(xiàng)目,屬于 bigtable 的開(kāi)源版本,所實(shí)現(xiàn)的語(yǔ)言為Java(故依賴 Java SDK).HBase 依托于 Hadoop 的 HDFS(分布式文件系統(tǒng))作為最基本存儲(chǔ)基礎(chǔ)單位.
HBase在列上實(shí)現(xiàn)了 BigTable 論文提到的壓縮算法、內(nèi)存操作和布隆過(guò)濾器.HBase的表能夠作為 MapReduce(https://zh.wikipedia.org/wiki/MapReduce)任務(wù)的輸入和輸出,可以通過(guò)Java API來(lái)拜訪數(shù)據(jù),也可以通過(guò)REST、Avro或者Thrift的API來(lái)拜訪.
1. 特色
1.1 數(shù)據(jù)格局
HBash 的數(shù)據(jù)存儲(chǔ)是基于列(ColumnFamily)的,且非常松散—— 分歧于傳統(tǒng)的關(guān)系型數(shù)據(jù)庫(kù)(RDBMS),HBase 允許表下某行某列值為空時(shí)不做任何存儲(chǔ)(也不占位),減少了空間占用也提高了讀性能.
不外鑒于其它NoSql數(shù)據(jù)庫(kù)也具有同樣靈活的數(shù)據(jù)存儲(chǔ)結(jié)構(gòu),該優(yōu)勢(shì)在本次選型中并不出彩.
我們以一個(gè)簡(jiǎn)單的例子來(lái)了解使用 RDBMS 和 HBase 各自的辦理方式:
1)RDBMS計(jì)劃:
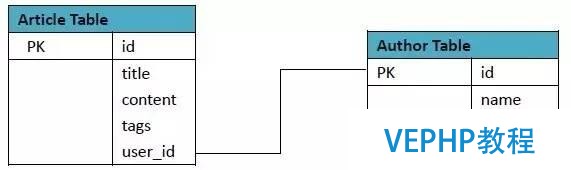
此中Article表格式:
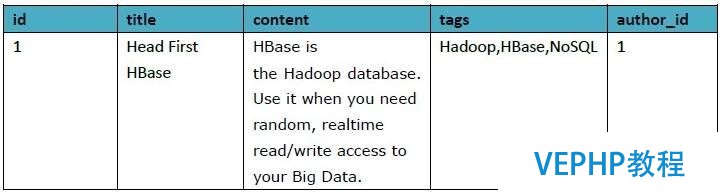
Author表格局:

2)等價(jià)的HBase計(jì)劃:

對(duì)付前端而言,這里的 Column Keys 和 Column Family 可以看為這樣的關(guān)系:

1.2 性能
HStore存儲(chǔ)是HBase存儲(chǔ)的核心,它由兩部門(mén)組成,一部門(mén)是MemStore,一部門(mén)是StoreFiles.
MemStore 是 Sorted Memory Buffer,用戶寫(xiě)入的數(shù)據(jù)首先會(huì)放入MemStore,當(dāng)MemStore滿了以后會(huì)Flush成一個(gè)StoreFile(底層實(shí)現(xiàn)是HFile),當(dāng)StoreFile文件數(shù)量增長(zhǎng)到必定閾值,會(huì)觸發(fā)Compact合并操作,將多個(gè)StoreFiles合并成一個(gè)StoreFile,合并過(guò)程中會(huì)進(jìn)行版本合并和數(shù)據(jù)刪除,因此可以看出HBase其實(shí)只有增加數(shù)據(jù),所有的更新和刪除操作都是在后續(xù)的compact過(guò)程中進(jìn)行的,這使得用戶的寫(xiě)操作只要進(jìn)入內(nèi)存中就可以立即返回,保證了HBase I/O的高性能.
1.3 數(shù)據(jù)版本
Hbase 還能直接檢索到往昔版本的數(shù)據(jù),這意味著我們更新數(shù)據(jù)時(shí),舊數(shù)據(jù)并沒(méi)有即時(shí)被清除,而是保存著:
Hbase 中通過(guò) row+columns 所指定的一個(gè)存貯單元稱為cell.每個(gè) cell都保留著同一份數(shù)據(jù)的多個(gè)版本——版本通過(guò)時(shí)間戳來(lái)索引.
時(shí)間戳的類型是 64位整型.時(shí)間戳可以由Hbase(在數(shù)據(jù)寫(xiě)入時(shí)自動(dòng) )賦值,此時(shí)時(shí)間戳是精確到毫秒的當(dāng)前系統(tǒng)時(shí)間.時(shí)間戳也可以由客戶顯式賦值.如果應(yīng)用程序要避免數(shù)據(jù)版本沖突,就必須自己生成具有唯一性的時(shí)間戳.每個(gè) cell中,不同版本的數(shù)據(jù)依照時(shí)間倒序排序,即最新的數(shù)據(jù)排在最前面.
為了避免數(shù)據(jù)存在過(guò)多版本造成的的管理 (包含存貯和索引)負(fù)擔(dān),Hbase提供了兩種數(shù)據(jù)版本回收方式.一是保存數(shù)據(jù)的最后n個(gè)版本,二是保存最近一段時(shí)間內(nèi)的版本(比如最近七天).用戶可以針對(duì)每個(gè)列族進(jìn)行設(shè)置.
1.4 CAP類別
2. Node下的使用
HBase的相關(guān)操作可參考下表:

在node環(huán)境下,可通過(guò) node-hbase(https://github.com/wdavidw/node-hbase)來(lái)實(shí)現(xiàn)相關(guān)拜訪和操作,注意該工具包依賴于 PHYTHON2.X(3.X不支持)和Coffee.
假如是在 window 系統(tǒng)下還需依賴 .NET framwork2.0,64位系統(tǒng)可能無(wú)法直接通過(guò)安裝包安裝.
官方示例:

數(shù)據(jù)檢索:

尚有 hbase-client(https://github.com/alibaba/node-hbase-client)也是一個(gè)不錯(cuò)的選擇,具體API參照其文檔.
3. 優(yōu)毛病
長(zhǎng)處:
存儲(chǔ)容量年夜,一個(gè)表可以容納上億行,上百萬(wàn)列;
可通過(guò)版本進(jìn)行檢索,能搜到所需的汗青版本數(shù)據(jù);
負(fù)載高時(shí),可通過(guò)簡(jiǎn)單的添加機(jī)器來(lái)實(shí)現(xiàn)水平切分?jǐn)U展,跟Hadoop的無(wú)縫集成保障了其數(shù)據(jù)可靠性(HDFS)和海量數(shù)據(jù)闡發(fā)的高性能(MapReduce);
在第3點(diǎn)的基礎(chǔ)上可有效避免單點(diǎn)故障的產(chǎn)生.
毛病:
基于Java語(yǔ)言實(shí)現(xiàn)及Hadoop架構(gòu)意味著其API更實(shí)用于Java項(xiàng)目;
node開(kāi)發(fā)環(huán)境下所需依賴項(xiàng)較多、配置麻煩(或不知如何配置,如持久化配置),短缺文檔;
占用內(nèi)存很大,且鑒于建立在為批量闡發(fā)而優(yōu)化的HDFS上,導(dǎo)致讀取性能不高;
API相比其它 NoSQL 的相對(duì)愚笨.
實(shí)用場(chǎng)景:
bigtable類型的數(shù)據(jù)存儲(chǔ);
對(duì)數(shù)據(jù)有版本查詢需求;
應(yīng)對(duì)超年夜數(shù)據(jù)量要求擴(kuò)展簡(jiǎn)單的需求.
Redis
Redis 是一個(gè)開(kāi)源的使用ANSI C語(yǔ)言編寫(xiě)、支持網(wǎng)絡(luò)、可基于內(nèi)存亦可持久化的日志型、Key-Value數(shù)據(jù)庫(kù),并提供多種語(yǔ)言的API.今朝由VMware主持開(kāi)發(fā)工作.
Redis 通常被稱為數(shù)據(jù)結(jié)構(gòu)服務(wù)器,因?yàn)橹?value)可以是 字符串(String), 哈希(Hash/Map), 列表(list), 集合(sets) 和 有序集合(sorted sets)五種類型,操作非常方便.比如,如果你在做好友系統(tǒng),查看本身的好友關(guān)系,如果采用其他的key-value系統(tǒng),則必須把對(duì)應(yīng)的好友拼接成字符串,然后在提取好友時(shí),再把value進(jìn)行解析,而redis則相對(duì)簡(jiǎn)單,直接支持list的存儲(chǔ)(采用雙向鏈表或者壓縮鏈表的存儲(chǔ)方式).
我們來(lái)看下這五種數(shù)據(jù)類型.
1)String
string 是 Redis 最基本的類型,你可以懂得成與 Memcached 一模一樣的類型,一個(gè)key對(duì)應(yīng)一個(gè)value.
string 類型是二進(jìn)制平安的.意思是 Redis 的 string 可以包含任何數(shù)據(jù).比如 jpg 圖片或者序列化的對(duì)象 .
string 類型是 Redis 最基本的數(shù)據(jù)類型,一個(gè)鍵最年夜能存儲(chǔ)512MB.
實(shí)例:

在以上實(shí)例中我們使用了 Redis 的 SET 和 GET 命令.鍵為 name,對(duì)應(yīng)的值為"zfpx". 注意:一個(gè)鍵最年夜能存儲(chǔ)512MB.
2)Hash
Redis hash 是一個(gè)鍵值對(duì)聚攏.
Redis hash 是一個(gè) string 類型的 field 和 value 的映射表,hash 特別得當(dāng)用于存儲(chǔ)對(duì)象.
實(shí)例:

以上實(shí)例中 hash 數(shù)據(jù)類型存儲(chǔ)了包括用戶腳本信息的用戶對(duì)象. 實(shí)例中我們使用了 Redis HMSET, HGETALL 命令,user:1 為鍵值. 每個(gè) hash 可以存儲(chǔ) 232- 1 鍵值對(duì)(40多億).
3)List
Redis 列表是簡(jiǎn)單的字符串列表,依照插入順序排序.你可以添加一個(gè)元素導(dǎo)列表的頭部(左邊)或者尾部(右邊).
實(shí)例:

列表最多可存儲(chǔ) 232- 1 元素 (4294967295, 每個(gè)列表可存儲(chǔ)40多億).
4)Sets
Redis的Set是string類型的無(wú)序集合. 集合是通過(guò)哈希表實(shí)現(xiàn)的,所以添加,刪除,查找的繁雜度都是O(1).
添加一個(gè)string元素到 key 對(duì)應(yīng)的 set 集合中,成功返回1,如果元素已經(jīng)在集合中返回0,key對(duì)應(yīng)的set不存在返回差錯(cuò),指令格式為
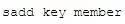
實(shí)例:

注意:以上實(shí)例中 zfpx1 添加了兩次,但根據(jù)集合內(nèi)元素的唯一性,第二次插入的元素將被忽略. 集合中最年夜的成員數(shù)為 232- 1 (4294967295, 每個(gè)集合可存儲(chǔ)40多億個(gè)成員).
5)sorted sets/zset
Redis zset 和 set 一樣也是string類型元素的集合,且不允許重復(fù)的成員.分歧的是每個(gè)元素都會(huì)關(guān)聯(lián)一個(gè)double類型的分?jǐn)?shù).redis正是通過(guò)分?jǐn)?shù)來(lái)為集合中的成員進(jìn)行從小到大的排序.
zset的成員是唯一的,但分?jǐn)?shù)(score)卻可以反復(fù).可以通過(guò) zadd 命令(格式如下) 添加元素到集合,若元素在集合中存在則更新對(duì)應(yīng)score
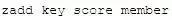
實(shí)例:

1.2 性能
Redis數(shù)據(jù)庫(kù)完全在內(nèi)存中,因此處置速度非常快,每秒能執(zhí)行約11萬(wàn)集合,每秒約81000+條記錄(測(cè)試數(shù)據(jù)的可參考這篇《Redis千萬(wàn)級(jí)的數(shù)據(jù)量的性能測(cè)試》www.cnblogs.com/lovecindywang/archive/2011/03/03/1969633.html).
Redis的數(shù)據(jù)能確保一致性——所有Redis操作是原子性(Atomicity,意味著操作的不可再分,要么執(zhí)行要么不執(zhí)行)的,這保證了如果兩個(gè)客戶端同時(shí)拜訪的Redis服務(wù)器將獲得更新后的值.
1.3 持久化
通過(guò)定時(shí)快照(snapshot)和基于語(yǔ)句的追加(AppendOnlyFile,aof)兩種方式,redis可以支持?jǐn)?shù)據(jù)持久化——將內(nèi)存中的數(shù)據(jù)存儲(chǔ)到磁盤(pán)上,便利在宕機(jī)等突發(fā)情況下快速恢復(fù).
1.4 CAP類別
屬于CP類型(相識(shí)更多:www.quora.com/What-is-Redis-in-the-context-of-the-CAP-Theorem).
2. Node下的使用
node 下可使用 node_redis(https://github.com/NodeRedis/node_redis)來(lái)實(shí)現(xiàn) redis 客戶端操作:

非常豐富的數(shù)據(jù)布局;
Redis提供了事務(wù)的功效,可以保證一串 命令的原子性,中間不會(huì)被任何操作打斷;
數(shù)據(jù)存在內(nèi)存中,讀寫(xiě)非常的高速,可以到達(dá)10w/s的頻率.
毛病:
Redis3.0后才出來(lái)官方的集群計(jì)劃,但仍存在一些架構(gòu)上的問(wèn)題(http://sunxiang0918.cn/2015/10/03/Redis%E9%9B%86%E7%BE%A4%E9%83%A8%E7%BD%B2/);
持久化功能體驗(yàn)不佳——通過(guò)快照辦法實(shí)現(xiàn)的話,需要每隔一段時(shí)間將整個(gè)數(shù)據(jù)庫(kù)的數(shù)據(jù)寫(xiě)到磁盤(pán)上,代價(jià)非常高;而aof辦法只追蹤變化的數(shù)據(jù),類似于mysql的binlog辦法,但追加log可能過(guò)大,同時(shí)所有操作均要重新執(zhí)行一遍,恢復(fù)速度慢;
由于是內(nèi)存數(shù)據(jù)庫(kù),所以,單臺(tái)機(jī)器,存儲(chǔ)的數(shù)據(jù)量,跟機(jī)器自己的內(nèi)存大小.雖然redis自己有key過(guò)期策略,但是還是需要提前預(yù)估和節(jié)約內(nèi)存.如果內(nèi)存增長(zhǎng)過(guò)快,需要定期刪除數(shù)據(jù).
實(shí)用場(chǎng)景:
適用于數(shù)據(jù)變化快且數(shù)據(jù)庫(kù)大小可遇見(jiàn)(適合內(nèi)存容量)的應(yīng)用法式.更具體的可參照這篇《Redis 的 5 個(gè)常見(jiàn)使用場(chǎng)景》譯文(http://blog.jobbole.com/88383/).
MongoDB
MongoDB 是一個(gè)高性能,開(kāi)源,無(wú)模式的文檔型數(shù)據(jù)庫(kù),開(kāi)發(fā)語(yǔ)言是C++.它在很多場(chǎng)景下可用于替代傳統(tǒng)的關(guān)系型數(shù)據(jù)庫(kù)或鍵/值存儲(chǔ)方式.
在 MongoDB 中,文檔是對(duì)數(shù)據(jù)的抽象,它的表現(xiàn)形式便是我們常說(shuō)的 BSON(Binary JSON ).
BSON 是一個(gè)輕量級(jí)的二進(jìn)制數(shù)據(jù)格式.MongoDB 能夠使用 BSON,并將 BSON 作為數(shù)據(jù)的存儲(chǔ)寄存在磁盤(pán)中.
BSON 是為效率而設(shè)計(jì)的,它只必要使用很少的空間,同時(shí)其編碼和解碼都是非常快速的.即使在最壞的情況下,BSON格式也比JSON格式再最好的情況下存儲(chǔ)效率高.
對(duì)付前端開(kāi)發(fā)者來(lái)說(shuō),一個(gè)“文檔”就相當(dāng)于一個(gè)對(duì)象:
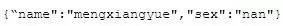
對(duì)于文檔是有一些限制的:有序、區(qū)分大小寫(xiě)的,所以下面的兩個(gè)文檔是與上面分歧的:

另外,對(duì)付文檔的字段 MongoDB 有如下的限制:
_id必需存在,如果你插入的文檔中沒(méi)有該字段,那么 MongoDB 會(huì)為該文檔創(chuàng)建一個(gè)ObjectId作為其值._id的值必需在本集合中是唯一的.
多個(gè)文檔則組合為一個(gè)“集合”.在 MongoDB 中的集合是無(wú)模式的,也就是說(shuō)集合中存儲(chǔ)的文檔的結(jié)構(gòu)可以是不同的,好比下面的兩個(gè)文檔可以同時(shí)存入到一個(gè)集合中:
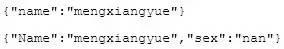
1.2 性能
MongoDB 今朝支持的存儲(chǔ)引擎為內(nèi)存映射引擎.當(dāng) MongoDB 啟動(dòng)的時(shí)候,會(huì)將所有的數(shù)據(jù)文件映射到內(nèi)存中,然后操作系統(tǒng)會(huì)托管所有的磁盤(pán)操作.這種存儲(chǔ)引擎有以下幾種特點(diǎn):
MongoDB 中關(guān)于內(nèi)存管理的代碼非常精簡(jiǎn),究竟相關(guān)的工作已經(jīng)有操作系統(tǒng)進(jìn)行托管.
MongoDB 服務(wù)器使用的虛擬內(nèi)存將非常巨大,并將超過(guò)整個(gè)數(shù)據(jù)文件的大小.不消擔(dān)心,操作系統(tǒng)會(huì)去處理這一切.
在《Mongodb億級(jí)數(shù)據(jù)量的性能測(cè)試》(www.cnblogs.com/lovecindywang/archive/2011/03/02/1969324.html)一文中,MongoDB 展現(xiàn)了強(qiáng)勁的大數(shù)據(jù)處置性能(數(shù)據(jù)甚至比Redis的漂亮的多).
另外,MongoDB 提供了全索引支持(www.cnblogs.com/yangecnu/archive/2011/07/19/2110989.html):包含文檔內(nèi)嵌對(duì)象及數(shù)組.Mongo的查詢優(yōu)化器會(huì)分析查詢表達(dá)式,并生成一個(gè)高效的查詢計(jì)劃.通常能夠極大的提高查詢的效率.
1.3 持久化
MongoDB 在1.8版本之后開(kāi)始支持 journal,便是我們常說(shuō)的 redo log,用于故障恢復(fù)和持久化.
當(dāng)系統(tǒng)啟動(dòng)時(shí),MongoDB 會(huì)將數(shù)據(jù)文件映射到一塊內(nèi)存區(qū)域,稱之為Shared view,在不開(kāi)啟 journal 的系統(tǒng)中,數(shù)據(jù)直接寫(xiě)入shared view,然后返回,系統(tǒng)每60s刷新這塊內(nèi)存到磁盤(pán),這樣,如果斷電或down機(jī),就會(huì)喪失很多內(nèi)存中未持久化的數(shù)據(jù).
當(dāng)系統(tǒng)開(kāi)啟了 journal 功能,系統(tǒng)會(huì)再映射一塊內(nèi)存區(qū)域供 journal 使用,稱之為 private view,MongoDB 默認(rèn)每100ms刷新 privateView 到 journal,也便是說(shuō),斷電或宕機(jī),有可能丟失這100ms數(shù)據(jù),一般都是可以忍受的,如果不能忍受,那就用程序?qū)憀og吧(但開(kāi)啟journal后使用的虛擬內(nèi)存是之前的兩倍).
1.4 CAP類別
MongoDB 比擬靈活,可以設(shè)置成 strong consistent (CP類型)或者 eventual consistent(AP類型).
2. Node下的使用
MongoDB 在 node 情況下的驅(qū)動(dòng)引擎是 node-mongodb-native(http://github.com/mongodb/node-mongodb-native),作為依賴封裝到 mongodb 包里,我們直接安裝即可:
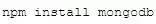
實(shí)例:

另外我們也可以使用MongoDB的ODM(面向工具數(shù)據(jù)庫(kù)管理器) —— mongoose(http://mongoosejs.com/docs/index.html)來(lái)做數(shù)據(jù)庫(kù)管理,具體參照其API文檔.
強(qiáng)年夜的自動(dòng)化 shading 功能(了解更多:http://xiezhenye.com/2012/12/mongodb-sharding-%E6%9C%BA%E5%88%B6%E5%88%86%E6%9E%90.html);
全索引支持,查詢異常高效;
面向文檔(BSON)存儲(chǔ),數(shù)據(jù)模式簡(jiǎn)單而強(qiáng)年夜;
支持動(dòng)態(tài)查詢,查詢指令也使用JSON形式的標(biāo)志,可輕易查詢文檔中內(nèi)嵌的對(duì)象及數(shù)組;
支持 javascript 表達(dá)式查詢,可在服務(wù)器端執(zhí)行隨意率性的 javascript函數(shù).
毛病:
單個(gè)文檔年夜小限制為16M,32位系統(tǒng)上,不支持年夜于2.5G的數(shù)據(jù);
對(duì)內(nèi)存要求比擬大,至少要保證熱數(shù)據(jù)(索引,數(shù)據(jù)及系統(tǒng)其它開(kāi)銷)都能裝進(jìn)內(nèi)存;
非事務(wù)機(jī)制,無(wú)法保證變亂的原子性.
實(shí)用場(chǎng)景:
適用于實(shí)時(shí)的插入、更新與查詢的需求,并具備應(yīng)用法式實(shí)時(shí)數(shù)據(jù)存儲(chǔ)所需的復(fù)制及高度伸縮性;
非常得當(dāng)文檔化格式的存儲(chǔ)及查詢;
高伸縮性的場(chǎng)景:MongoDB 非常得當(dāng)由數(shù)十或者數(shù)百臺(tái)服務(wù)器組成的數(shù)據(jù)庫(kù);
對(duì)性能的關(guān)注跨越對(duì)功能的要求.
Couchbase
本文之所以沒(méi)有介紹 CouchDB 或 Membase,是因?yàn)樗鼈兒喜⒘?合并之后的公司基于 Membase 與 CouchDB 開(kāi)發(fā)了一款新產(chǎn)物,新產(chǎn)物的名字叫做 Couchbase.
Couchbase 可以說(shuō)是聚攏眾家之長(zhǎng),目前應(yīng)該是最先進(jìn)的Cache系統(tǒng),其開(kāi)發(fā)語(yǔ)言是 C/C++.
Couchbase Server 是個(gè)面向文檔的數(shù)據(jù)庫(kù)(其所用的技術(shù)來(lái)自于Apache CouchDB項(xiàng)目),能夠?qū)崿F(xiàn)水平伸縮,并且對(duì)于數(shù)據(jù)的讀寫(xiě)來(lái)說(shuō)都能提供低延遲的拜訪(這要?dú)w功于Membase技術(shù)).
Couchbase 跟 MongoDB 一樣都是面向文檔的數(shù)據(jù)庫(kù),不過(guò)在往 Couchbase 插入數(shù)據(jù)前,必要先建立 bucket —— 可以把它理解為“庫(kù)”或“表”.
因?yàn)?Couchbase 數(shù)據(jù)基于 Bucket 而導(dǎo)致缺乏表結(jié)構(gòu)的邏輯,故如果必要查詢數(shù)據(jù),得先建立 view(跟RDBMS的視圖不同,view是將數(shù)據(jù)轉(zhuǎn)換為特定格式結(jié)構(gòu)的數(shù)據(jù)形式如JSON)來(lái)執(zhí)行.
Bucket的意義 —— 在于將數(shù)據(jù)進(jìn)行分隔,好比:任何 view 就是基于一個(gè) Bucket 的,僅對(duì) Bucket 內(nèi)的數(shù)據(jù)進(jìn)行處理.一個(gè)server上可以有多個(gè)Bucket,每個(gè)Bucket的存儲(chǔ)類型、內(nèi)容占用、數(shù)據(jù)復(fù)制數(shù)量等,都需要分別指定.從這個(gè)意義上看,每個(gè)Bucket都相當(dāng)于一個(gè)獨(dú)立的實(shí)例.在集群狀態(tài)下,我們需要對(duì)server進(jìn)行集群設(shè)置,Bucket只側(cè)重?cái)?shù)據(jù)的保管.
每當(dāng)views建立時(shí), 就會(huì)建立indexes, index的更新和以往的數(shù)據(jù)庫(kù)索引更新區(qū)別很大. 好比現(xiàn)在有1W數(shù)據(jù),更新了200條,索引只需要更新200條,而不需要更新所有數(shù)據(jù),map/reduce功能基于index的懶更新行為,大大得益.
要把穩(wěn)的是,對(duì)于所有文件,couchbase 都會(huì)建立一個(gè)額外的 56byte 的 metadata,這個(gè) metadata 功能之一就是表明數(shù)據(jù)狀態(tài),是否活動(dòng)在內(nèi)存中.同時(shí)文件的 key 也作為標(biāo)識(shí)符和 metadata 一起長(zhǎng)期活動(dòng)在內(nèi)存中.
1.2 性能
couchbase 的精髓就在于依賴內(nèi)存最大化降低硬盤(pán)I/O對(duì)吞吐量的負(fù)面影響,所以其讀寫(xiě)速度非常快,可以到達(dá)亞毫秒級(jí)的響應(yīng).
couchbase在對(duì)數(shù)據(jù)進(jìn)行增刪時(shí)會(huì)先體現(xiàn)在內(nèi)存中,而不會(huì)立刻體現(xiàn)在硬盤(pán)上,從內(nèi)存的修改到硬盤(pán)的修改這一步驟是由 couchbase 自動(dòng)完成,等待執(zhí)行的硬盤(pán)操作會(huì)以write queue的形式排隊(duì)等待執(zhí)行,也正是通過(guò)這個(gè)辦法,硬盤(pán)的I/O效率在 write queue 滿之前是不會(huì)影響 couchbase 的吞吐效率的.
鑒于內(nèi)存資源肯定遠(yuǎn)遠(yuǎn)少于硬盤(pán)資源,所以如果數(shù)據(jù)量小,那么全部數(shù)據(jù)都放在內(nèi)存上自然是最優(yōu)選擇,這時(shí)候couchbase的效率也是非常高.
但是數(shù)據(jù)量大的時(shí)候過(guò)多的數(shù)據(jù)就會(huì)被放在硬盤(pán)之中.當(dāng)然,最終所有數(shù)據(jù)都會(huì)寫(xiě)入硬盤(pán),不外有些頻繁使用的數(shù)據(jù)提前放在內(nèi)存中自然會(huì)提高效率.
1.3 持久化
其前身之一 memcached 是完全不支持持久化的,而 Couchbase 添加了對(duì)異步持久化的支持:
Couchbase提供兩種核心類型的buckets —— Couchbase 類型和 Memcached 類型.此中 Couchbase 類型提供了高可用和動(dòng)態(tài)重配置的分布式數(shù)據(jù)存儲(chǔ),提供持久化存儲(chǔ)和復(fù)制服務(wù).
Couchbase bucket 具有持久性 —— 數(shù)據(jù)單元異步從內(nèi)存寫(xiě)往磁盤(pán),防范服務(wù)重啟或較小的故障產(chǎn)生時(shí)數(shù)據(jù)丟失.持久性屬性是在 bucket 級(jí)設(shè)置的.
1.4 CAP類型
Couchbase 群集所有點(diǎn)都是對(duì)等的,只是在創(chuàng)建群或者加入集群時(shí)必要指定一個(gè)主節(jié)點(diǎn),一旦結(jié)點(diǎn)成功加入集群,所有的結(jié)點(diǎn)對(duì)等.
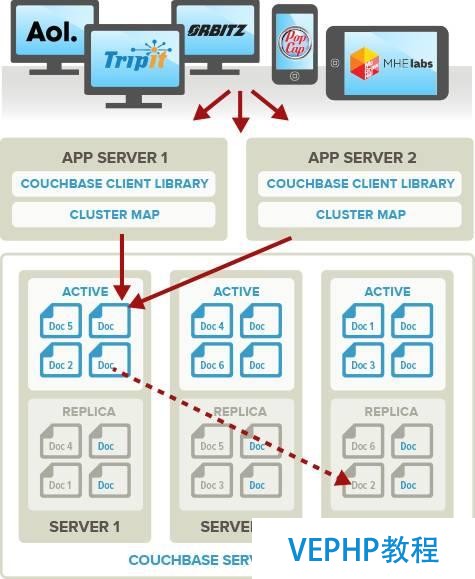
對(duì)等網(wǎng)的長(zhǎng)處是,集群中的任何節(jié)點(diǎn)失效,集群對(duì)外提供服務(wù)完全不會(huì)中斷,只是集群的容量受影響.
由于 couchbase 是對(duì)等網(wǎng)集群,所有的節(jié)點(diǎn)都可以同時(shí)對(duì)客戶端提供服務(wù),這就需要有辦法把集群的節(jié)點(diǎn)信息暴露給客戶端,couchbase 提供了一套機(jī)制,客戶端可以獲取所有節(jié)點(diǎn)的狀態(tài)以及節(jié)點(diǎn)的變動(dòng),由客戶端根據(jù)集群的當(dāng)前狀態(tài)計(jì)算 key 所在的位置.
就上述的介紹,Couchbase 顯著屬于 CP 類型.
2. Node下的使用
實(shí)例:
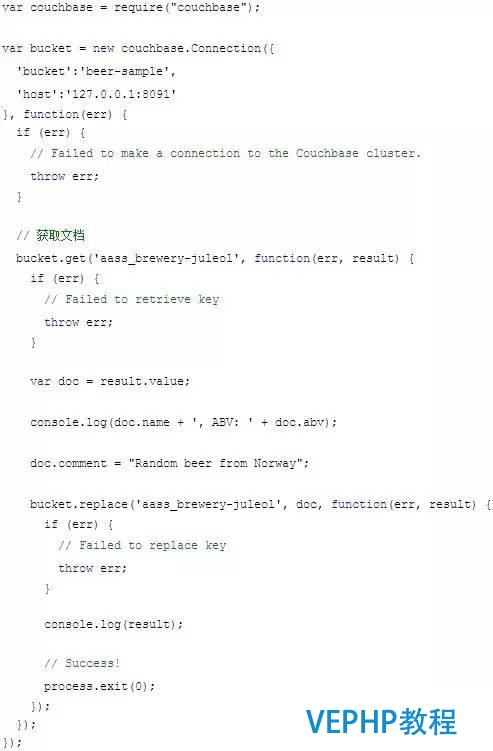
高并發(fā)性,高機(jī)動(dòng)性,高拓展性,容錯(cuò)性好;
以 vBucket 的概念實(shí)現(xiàn)更抱負(fù)化的自動(dòng)分片以及動(dòng)態(tài)擴(kuò)容(了解更多:http://jolestar.com/couchbase/);
毛病:
Couchbase 的存儲(chǔ)方式為 Key/Value,但 Value 的類型很為單一,不支持?jǐn)?shù)組.另外也不會(huì)自動(dòng)創(chuàng)建doc id,必要為每一文檔指定一個(gè)用于存儲(chǔ)的 Document Indentifer;
各種組件拼接而成,都是c++實(shí)現(xiàn),導(dǎo)致復(fù)雜度過(guò)高,遇到奇怪的性能問(wèn)題排查比擬困難,(中文)文檔比擬欠缺;
采用緩存全部key的策略,必要大量?jī)?nèi)存.節(jié)點(diǎn)宕機(jī)時(shí) failover 過(guò)程有不可用時(shí)間,并且有部分?jǐn)?shù)據(jù)丟失的可能,在高負(fù)載系統(tǒng)上有假死現(xiàn)象;
逐漸傾向于閉源,社區(qū)版本(免費(fèi),但不提供官方維護(hù)升級(jí))和商業(yè)版本之間差距比擬大.
實(shí)用場(chǎng)景:
得當(dāng)對(duì)讀寫(xiě)速度要求較高,但服務(wù)器負(fù)荷和內(nèi)存花銷可遇見(jiàn)的需求;
必要支持 memcached 協(xié)議的需求.
LevelDB
LevelDB 是由谷歌重量級(jí)工程師(Jeff Dean 和 Sanjay Ghemawat)開(kāi)發(fā)的開(kāi)源項(xiàng)目,它是能處理十億級(jí)別規(guī)模 key-value 型數(shù)據(jù)持久性存儲(chǔ)的法式庫(kù),開(kāi)發(fā)語(yǔ)言是C++.
除了持久性存儲(chǔ),LevelDB 還有一個(gè)特色是 —— 寫(xiě)性能遠(yuǎn)高于讀性能(當(dāng)然讀性能也不差).
1. 特色
LevelDB 作為存儲(chǔ)系統(tǒng),數(shù)據(jù)記錄的存儲(chǔ)介質(zhì)包含內(nèi)存以及磁盤(pán)文件,當(dāng)LevelDB運(yùn)行了一段時(shí)間,此時(shí)我們給LevelDb進(jìn)行透視拍照,那么您會(huì)看到如下一番景象:

(圖1)
LevelDB 所寫(xiě)入的數(shù)據(jù)會(huì)先插入到內(nèi)存的 Mem Table 中,再由 Mem Table 合并到只讀且鍵值有序的 Disk Table(SSTable) 中,再由后臺(tái)線程不時(shí)的對(duì) Disk Table 進(jìn)行合并.
內(nèi)存中存在兩個(gè) Mem Table —— 一個(gè)是可以往里面寫(xiě)數(shù)據(jù)的table A,另一個(gè)是正在歸并到硬盤(pán)的 table B.
Mem Table 用 skiplist(http://blog.csdn.net/ict2014/article/details/17394259)實(shí)現(xiàn),寫(xiě)數(shù)據(jù)時(shí),先寫(xiě)日志(.log),再往A插入,因?yàn)橐淮螌?xiě)入操作只涉及一次磁盤(pán)順序?qū)懞鸵淮蝺?nèi)存寫(xiě)入,所以這是為何說(shuō)LevelDb寫(xiě)入速度極快的主要原因.如果當(dāng)B還沒(méi)完成合并,而A已經(jīng)寫(xiě)滿時(shí),寫(xiě)操作必需等待.
DiskTable(SSTable,格式為.sst)是分層的(leveldb的名稱起源),每一個(gè)大小不超過(guò)2M.最先 dump 到硬盤(pán)的 SSTable 的層級(jí)為0,層級(jí)為0的 SSTable 的鍵值范圍可能有重疊.如果這樣的 SSTable 太多,那么每次都必要從多個(gè) SSTable 讀取數(shù)據(jù),所以LevelDB 會(huì)在適當(dāng)?shù)臅r(shí)候?qū)?SSTable 進(jìn)行 Compaction,使得新生成的 SSTable 的鍵值范圍互不重疊.
進(jìn)行對(duì)層級(jí)為 level 的 SSTable 做 Compaction 的時(shí)候,取出層級(jí)為 level+1 的且鍵值空間與之重疊的 Table,以次序掃描的方式進(jìn)行合并.level 為0的 SSTable 做 Compaction 有些特殊:會(huì)取出 level 0 所有重疊的Table與下一層做 Compaction,這樣做保證了對(duì)于大于0的層級(jí),每一層里 SSTable 的鍵值空間是互不重疊的.
SSTable 中的某個(gè)文件屬于特定層級(jí),而且其存儲(chǔ)的記錄是 key 有序的,那么必然有文件中的最小 key 和最大 key,這是非常重要的信息,LevelDB 應(yīng)該記下這些信息 —— Manifest 就是干這個(gè)的,它記載了 SSTable 各個(gè)文件的管理信息,好比屬于哪個(gè)Level,文件名稱叫啥,最小 key 和最大 key 各自是多少.下圖是 Manifest 所存儲(chǔ)內(nèi)容的示意:

圖中只顯示了兩個(gè)文件(Manifest 會(huì)記載所有 SSTable 文件的這些信息),即 Level0 的 Test1.sst 和 Test2.sst 文件,同時(shí)記載了這些文件各自對(duì)應(yīng)的 key 范圍,好比 Test1.sstt 的 key 范圍是“an”到 “banana”,而文件 Test2.sst 的 key 范圍是“baby”到“samecity”,可以看出兩者的 key 范圍是有重疊的.
那么上方圖1中的 Current 文件是干什么的呢?這個(gè)文件的內(nèi)容只有一個(gè)信息,便是記載當(dāng)前的 Manifest 文件名.因?yàn)樵?LevleDB 的運(yùn)行過(guò)程中,隨著 Compaction 的進(jìn)行,SSTable 文件會(huì)發(fā)生變化,會(huì)有新的文件產(chǎn)生,老的文件被廢棄,Manifest 也會(huì)跟著反映這種變化,此時(shí)往往會(huì)新生成 Manifest 文件來(lái)記載這種變化,而 Current 則用來(lái)指出哪個(gè) Manifest 文件才是我們關(guān)心的那個(gè) Manifest 文件.
注意,鑒于 LevelDB 不屬于分布式數(shù)據(jù)庫(kù),故CAP軌則在此處不適用.
2. Node下的使用
Node 下可以使用 LevelUP(https://github.com/Level/levelup)來(lái)操作 LevelDB 數(shù)據(jù)庫(kù):

LevelUp 的API異常簡(jiǎn)潔實(shí)用,具體可參考官方文檔.
操作接口簡(jiǎn)單,基本操作包含寫(xiě)記錄,讀記錄和刪除記錄,也支持針對(duì)多條操作的原子批量操作;
寫(xiě)入性能遠(yuǎn)強(qiáng)于讀取性能;
數(shù)據(jù)量增年夜后,讀寫(xiě)性能下降趨平緩.
毛病:
隨機(jī)讀性能一般;
對(duì)分布式事務(wù)的支持還不成熟.并且機(jī)器資源浪費(fèi)率高.
順應(yīng)場(chǎng)景:
適用于對(duì)寫(xiě)入需求遠(yuǎn)大于讀取需求的場(chǎng)景(大部門(mén)場(chǎng)景其實(shí)都是這樣).
作者先容 VaJoy藍(lán)邦玨
騰訊SNG增值產(chǎn)物部前端工程師
小我博客:www.cnblogs.com/vajoy
近期熱文(點(diǎn)擊題目可閱讀全文)
《DAMS 2016:第二屆中國(guó)數(shù)據(jù)資產(chǎn)管理峰會(huì)重磅開(kāi)啟!》
《58沈劍:三種妙法搞定冗余表數(shù)據(jù)一致性!》
《力薦:一條update語(yǔ)句引發(fā)的“血案”》
《一道面試題:遇到大規(guī)模Oracle壞塊該怎么處理?》
《2B迎來(lái)風(fēng)口!7城熱招70人!保舉成功送iPhone6s!》
《高速換輪:Uber如何用微服務(wù)重構(gòu)工程系統(tǒng)?》
《Codis作者首度揭秘TiKV事務(wù)模型,Google Spanner開(kāi)源實(shí)現(xiàn)!》
《深度保舉:創(chuàng)業(yè)團(tuán)隊(duì)為什么要選擇Oracle而不是MySQL?》
近期活動(dòng):
Gdevops環(huán)球敏捷運(yùn)維峰會(huì)北京站
峰會(huì)官網(wǎng):www.gdevops.com
DAMS第二屆中國(guó)數(shù)據(jù)資產(chǎn)治理峰會(huì)
峰會(huì)官網(wǎng):www.dams.org.cn
References
node-hbase —— https://github.com/wdavidw/node-hbase
Couchbase的簡(jiǎn)單先容 —— http://bbs.byr.cn/#!article/Database/8365
新聞中間件剖析 —— http://blog.lday.me/?p=170
歡迎參與《細(xì)數(shù)5款主流NoSQL數(shù)據(jù)庫(kù)到底哪家強(qiáng)?》討論,分享您的想法,維易PHP學(xué)院為您提供專業(yè)教程。
轉(zhuǎn)載請(qǐng)注明本頁(yè)網(wǎng)址:
http://www.fzlkiss.com/jiaocheng/9235.html
同類教程排行
- 大數(shù)據(jù)學(xué)習(xí)——你知道Apache Cas
- 一張圖理清NoSQL、MPP和Hadoo
- 新思潮:NoSQL與DPDK、RDMA等
- CockroachDB 1.1發(fā)布 平均
- NoSQL的基本概念和分類比較 Redi
- 細(xì)數(shù)5款主流NoSQL數(shù)據(jù)庫(kù)到底哪家強(qiáng)?
- mongodb nosql 如何實(shí)現(xiàn)分頁(yè)
- 解析SQL與NoSQL的融合架構(gòu)產(chǎn)品GB
- mongodb NOSQL 各種查詢條件
- 科普|大數(shù)據(jù)技術(shù)原理與應(yīng)用(第五章 No
- 騰訊十多個(gè)人管理一萬(wàn)多臺(tái)NoSQL存儲(chǔ)服
- NoSQL數(shù)據(jù)庫(kù)的分布式算法
- 如何學(xué)習(xí)及選擇大數(shù)據(jù)非關(guān)系型數(shù)據(jù)庫(kù)NoS
- SQL和NOSQL有區(qū)別嗎?
- 2017年度全球“大數(shù)據(jù)企業(yè)50強(qiáng)”
