做了這么久的 DBA,你真的認識 MySQL 數據安全體系?
《做了這么久的 DBA,你真的認識 MySQL 數據安全體系?》要點:
本文介紹了做了這么久的 DBA,你真的認識 MySQL 數據安全體系?,希望對您有用。如果有疑問,可以聯系我們。


作者介紹:

強昌金
去哪兒網 高級DBA2015年加入去哪兒,擔任MySQL DBA,主要負責去哪兒數據庫管理平臺的開發、MySQL和Redis的運維.在數據庫方面,具有豐富的數據庫運維、性能優化經驗.
給大家分享下有關MySQL在數據安全的話題,怎么通過一些配置來保證數據安全以及保證數據的存儲落地是安全的.
我是在2014年加入陌陌,2015年加入去哪兒網,做MySQL的運維,包括自動化的開發.
接下來我將從四個方面給大家介紹一下,數據庫怎么通過一些配置做到數據安全的.
單機安全
集群安全
備份安全
發展
現在的行業中,數據是一個非常重要的資產.
數據是怎么保證安全呢?在日常中,大家都認為一些商業的數據庫能更好的保證數據安全.他們認為對于新興的MySQL來說,一致認為可以在互聯網使用,因為互聯網的數據丟了也就無所謂了,我感覺他們這是對MySQL數據庫的一個誤解.
我所說的數據安全是指數據落地的安全,而不是遭到黑客攻擊,也不包括網絡安全.
在企業剛開始起步的時候有可能資源有限,只使用單機,這時候單機有可能部署一個.
隨著企業的發展,有可能單機會存在數據崩潰的問題,這將導致整個數據不可用的.因此就會往集群化的方向發展,會利用主從模式,保證數據分布到多個節點,即使某個節點崩潰后,還有其他節點是可用的.
這樣就能保證真正的數據不丟嗎?有可能機房出現了網絡故障,或者整個機房宕機了.今年也遇到過很多整個數據不可用,備份也不可用的情況,這時候數據就丟失了.
為了更好的是保證數據安全,要進行備份.要對數據進行本地備份和遠程備份,這樣集群不可用的時候利用備份進行恢復.
第四方面,介紹一下MySQL基本的發展.
下面詳細的對這四個部分來進行闡述.
一. 單機安全

單機安全會涉及到兩個配置參數:
Double Write
innodb_flush_log_at_trx_commit
下面詳細說明.
1.1 Double Write

我們企業在剛剛起步的時候只有一個節點,怎么保證我們的數據落盤?在MySQL宕機或者系統宕機數據庫啟動的時候它能夠啟起來.在啟動過程中,他們會檢測數據頁是否是正常的,這時候我們會引入一個叫Double Write.
什么叫Double Write?對一個頁面的所有操作,包括頁頭、頁面等等,這原本是物理的操作.但是為了節約日志量,把它改成邏輯的,就會記錄包括空間數、內容字段等等,等到有必要的時候才真正的將這些邏輯寫變成物理寫.
在寫的過程中,首先保證所寫的頁面是正確的.如果一個頁面在寫的過程中由于多次寫導致頁面斷裂,這樣就不可寫.這時候我們就需要一個Double Write,等于現在一個是鏡像,另一個是備份.
MySQL 5.7之前有一個2M的緩存.如果在校驗的過程中,這個頁面有問題,就會利用Double Write將兩個頁面進行拷貝回來,這樣我們的數據庫就恢復到可用的狀態.

四個問題:
兩次寫本身頁面斷裂會不會有問題?它所要操作頁面之前,記錄的是數據庫之前的狀態是一致的.這時頁面出現問題,本身就不會去寫入了,就不會出現問題.
最近數據是不是一直在覆蓋?因為我們知道只有2M的空間,因此會一直覆蓋去寫.
性能問題?我們知道在Double Write有兩次寫的.這對我們的操作是不是也有兩次?我們知道它有一個緩存空間,當緩存空間滿的時候,會將邏輯寫變成順序寫,這對磁盤的影響是比較小的,不會導致性能消耗,但是也會帶來一點點性能消耗.
可不可以沒有Double Write?有可能.
1.2 innodb_flush_log_at_trx_commit

數據庫宕機分為兩種情況:
數據庫宕機服務器正常
服務器宕機
在宕機的時候,對提交到數據庫的事務如果沒有寫到redo log文件中,數據就會丟失.
innodb_flush_log_at_trx_commit參數的三個值的策略:
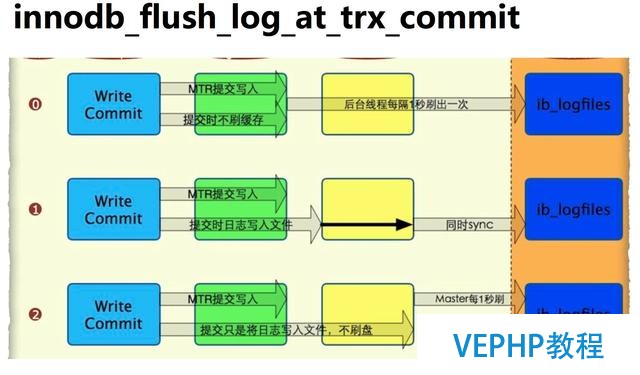
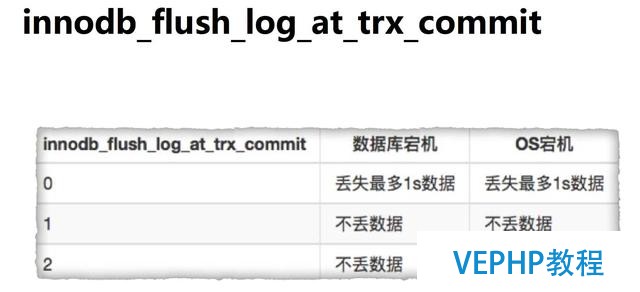
這三個參數對數據庫宕機是不是會導致數據的丟失呢?
在值為0的時候,每秒寫入,在數據庫宕機或者系統宕機時,都會有數據的丟失的.
在值為1的時候,每次操作都會去寫入到真正的redo log的磁盤文件中,這時候不管數據庫宕機還是操作系統宕機,都不會丟失.在啟動的時候,redo log在文件中是可以進行恢復的.
在值為2的時候,是刷到操作系統的cache中,數據庫宕機了,但是操作系統是完整的,能夠寫入到磁盤中,這時候數據是不會丟失的.
二. 集群安全
在單機的過程中,通過兩個參數保證我們的數據落盤.然而,有可能服務器宕機了,再也啟動不起來了,這時我們的數據等于是全部丟失了,或者可以利用備份數據進行恢復一部分的數據,這種情況對我們的企業就會導致一定的影響.

主從復制
異步復制
半同步復制
MySQL Galera Cluster
此時,我們可以通過集群的模式,如搭建一主多從或者多主等等,來保證我們的數據在多個節點都有的,即使一個節點宕機以后,可以把讀寫服務切換到另一個節點,保證數據可用的.
2.1. 主從復制
2.1.1 sync_binlog

主從復制是異步的模式.
在默認情況下,我們都會使用簡單的主從復制進行保證一主多節點進行同步.
在復制過程中最重要的一個東西就是sync_binlog,它在等于0的時候,每次刷新到cache中;等于1的時候會同步到磁盤中.
這個參數對數據丟失的影響:
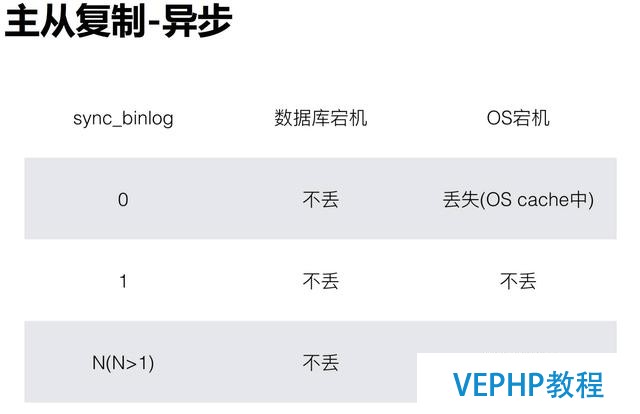
同樣數據庫宕機分兩種,一種是系統的宕機,一種是數據庫宕機.數據庫宕機已經寫入到OS的cache中,因此不會丟失.如果恰好這時操作系統宕機,就等于丟失OS cache了,如果sync_binlog 值為0,將會丟失數據了.
2.1.2 binlog_format

二進制日志格式有三種:
STATEMENT
MIXED
ROW
我們現在主要使用ROW格式,會存在一個問題,就是我們日志量會稍微大一些.
2.1.3 與復制POS點相關參數

在主從復制過程中,有兩個重要的文件:
一個是記錄master-info
一個是記錄relay-log-info
從MySQL 5.7版本,已經使用表結構了,建議這么做.
這兩個sync-master-info和sync-relay-log-info參數,如果存在宕機,我們能知道之前復制的點在什么位置.
relay_log_recovery個參數,如果設置為1,它會找到MySQL線程最新執行的最后的位置,然后利用那個位置,重新創新一個relay-log,這個值對我們來講非常重要.如果不設為1,會導致我們在啟動過程中,點不是最新的點,會導致事物的沖突,甚至會導致主從復制的沖突.
2.2 半同步
主要說說一下三點:
半同步復制特性
半同步與異步對比
半同步參數: rpl_semi_sync_master_wait_point
2.2.1 半同步復制特性
主庫和從庫會存在延時的,可能從庫沒有接收到主庫的binlog信息.
MySQL 推出了一個半同步復制,就是主庫會等待從庫中至少一個節點,是否真正的獲取到binlog日志,并且刷新到redo log文件中.
半同步有哪些特性呢?

從庫告知主庫是否為半同步
主庫事務提交會被阻塞
從庫寫入relay log后通知主庫
主庫等待超時后,自動轉換為異步復制
主從必須同時開啟半同步
首先會告訴主庫自己是否配置了半同步,并且主庫提交事物的時候,這個線程會進行阻塞,等待從庫進行回復.如果真的沒有回復,它會把這個從庫降成異步復制.如果有回復,進行確認后,主庫的線程就會繼續做其他的事務,那么在這個過程中,它是會被阻塞掉的.
從庫接收到主庫的binlog后,會寫入到redo log.
在半同步的復制過程中,每個事務提交的時候,會等待至少一個從節點,如果從節點已經獲取到了binlog,這時候主節點才會真正的提交做后續的操作,這時候就可以保證至少有一個節點是和主節點的數據是一致的.
2.2.2 半同步復制特性

最主要的區別在于半同步復制能保證至少一個從節點會與主節點數據一致性.
2.2.3 rpl_semi_sync_master_wait_point

在半同步過程中,有一個重要的參數rpl_semi_sync_master_wait_point來進行控制,就是主庫的線程提交事務后,在整個進程進行等待還是在提交事務以后再去等待.
首先講一下這兩個配置有什么影響.

AFTER_COMMIT提交完進入等待狀態,等待一個從庫,現場回復一個ACP確認.從庫匯報了ACP確認后,進入后續的狀態,就是將結果通知到客戶端.
在這個狀態的情況下,可能會導致從庫丟數據,之所以這樣是因為我們在引擎層已經提交了,這時候我們在等待的過程中,其實在這個主庫上的其它會話是能夠知道這個事務已經提交的結果.但是如果此時主庫還在等待過程中主庫宕機了,并且不可恢復,這時從庫有可能沒有接收到數據的,在主庫上它認為這個事務已經提交成功了,就會導致從庫根本沒有拿到這個binlog,因此會丟失這個事務的數據.
為了解決這個問題,在MySQL 5.7會推出另外一種狀態進行等待—-AFTER_SYNC,就是同步完立馬進行等待.
如果這時候主庫宕機了,從庫有可能接收到這個binlog,并且應用到從庫的數據庫中,這時主庫還沒有進入到提交,因此主庫的數據是沒有提交的,有可能從庫會多出一部分數據.
我個人認為,多出的數據,總比丟失的好.當我們的服務切入到從庫,服務在處理的過程中,會根據多出來的數據做相應的處理,總比沒有相對來說更好一些.
2.3 MySQL Galera Cluster
上面說的主從復制,不管使用異步復制還是半同步復制,都可能出現丟失數據的問題.去哪兒網,經過幾年的發展,多年的研究,大量的在使用Galera Cluster.

MySQL Galera Cluster 注意點:
基于binlog復制模式
DDL執行卡死
DDL優先
DDL執行過程中不能退出
Flow Control

在支付的業務中,我們要強烈要求數據是一致性的,這時候PRC能夠非常好的滿足這個特點.包括多點寫入,在日常維護中經常遇到一個問題,有可能需要重啟數據庫,或者遷移數據庫.
主從復制的架構,需要將業務的讀寫請求切換到另外一個節點.如果流量慢慢切入到別的節點就OK了,這時對業務的影響幾乎是沒有的,所以我們可以非常大膽的做一些切換操作.

double write如果我們沒有開,有可能數據庫就啟動不起來,啟動不起來也沒有任何問題,因為相當于這個新的節點加入到PCRC的過程中,就會執行一個SYNC的操作,會把數據拉取過來,只不過數據恢復的時間較長一些.
redo log這個參數是為了可以提高一些性能.sync-binlog,甚至binlog都不用開.
有了集群,這時候對業務來說,對企業來說,應該比較放心了,數據應該不會丟失了.但是,今年出現了好幾個案例,就是數據庫機房宕機,或者集群宕機以后,沒有備份可以用了,所有的數據都丟失了,我們只能強烈的依賴于備份.
今年上半年出現了兩個比較大的故障,就是連備份都不可用了.這時候備份安全對我們企業,對我們業務來說是非常重要的.
三. 備份安全
備份中分為兩個:
數據備份
binlog備份
數據備份中,我們可以每天對數據,對整個機器的數據進行一個鏡像,或者用別的MySQL Double等等進行備份.
binlog有可能我們在數據備份的時候也只是備份某一點的數據備份,在這次備份到下次備份之間,這種數據是怎么恢復呢?我們可以用binlog.
3.1 數據備份

備份方式分為:
冷備
熱備
備份工具分為:
邏輯備份工具
mysqldump
mysqldumper
mysqlpump
select … into outfile
物理備份工具
InnoDB ibbackup
Percona XtraBackup
邏輯備份工具,就是把dump文件保存起來,這會存在一個問題,有可能dump的時間很長,恢復的時間也就很長了.
這在整個數據庫想要依賴于這個備份節點恢復的時候,整個業務等待的時間就很長了.如果用邏輯備份,恢復時間越長,對業務的影響越大.所以,我們盡量采用一個物理的備份,如XtraBckup.
備份存儲分為:
本地存儲
遠程存儲
我們的備份數據庫存儲在本地的服務器上的話,可能存在備份文件不可用了,會導致數據的丟失.
因此,我們要優先考慮遠程備份,可以把MySQL數據文件備份到異地的機房.
3.2 binlog備份

有了數據備份后,它只是某個點的鏡像,上一次備份和下一次備份之間的數據怎么辦呢?只能通過binlog了,因此也需要備份binlog,而且最好也是存到遠程上.
四. 發展

我們在使用過程中,業務剛剛起步,有可能先單機模式,隨著業務的發展,我們就會擴展到復制模式,隨著業務的再次壯大以及業務重要性的要求,就會開始引入集群模式了,保證數據真正的不丟失,即使一個節點出現宕機,其他節點還有完整的數據.
END
維易PHP培訓學院每天發布《做了這么久的 DBA,你真的認識 MySQL 數據安全體系?》等實戰技能,PHP、MYSQL、LINUX、APP、JS,CSS全面培養人才。
