No-SQL數據庫為什么能適應分布式數據存儲?
《No-SQL數據庫為什么能適應分布式數據存儲?》要點:
本文介紹了No-SQL數據庫為什么能適應分布式數據存儲?,希望對您有用。如果有疑問,可以聯系我們。
在上一篇文章中介紹了非關系型數據庫的CAP理論,但是我們也提到了在一致性和可用性上很難去達到均衡,如果實現高可用性,并且允許分區的話,節點和節點之間就會失去聯系,每個節點在所在的局部網絡上可能能達到數據一致性,但是從全局角度來看,在允許時間范圍內的強一致性卻很難達到,現在很多的非關系型數據庫就屬于這一類.
CAP理論定義了分布式系統中如何存儲的問題,但是對于C和A原則的均衡問題并沒有得到很好的辦理,直到Base理論的提出,一致性和可用性的均衡才找到了一種比較合理的辦理方案.
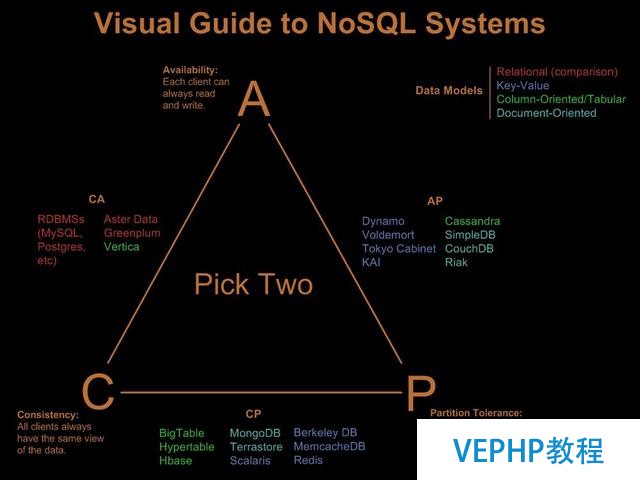
Base理論 = 基本可用性+軟狀態+最終一致性,弱化了強一致性和可用性,雙方都退一步,找到一致性和可用性最適合的距離.
基本可用性
在分布式數據庫系統中只要保證基本的可用性就可以了,也就說允許分布式系統的部分功能不可用,但是不影響整體核心功能的使用,降低了對可用性的需求.
軟狀態
我們在關系型數據庫的一致性中曾提到在事務提交后,數據庫的狀態從一種狀態轉變為另一種狀態,但是無論是轉變前還是轉變后都能夠數據庫的狀態都是一致的.而這里提到的軟狀態指的是允許數據庫在做狀態更新時存在一些中間狀態,尤其是整個分布式系統中的不同節點之間以及數據副本之間存在數據同步所帶來的延時,但只要保證不會影響到整體的可用性這種軟狀態的存在也是OK的.
最終一致性
最終一致性和強一致性的區別在于并不要求實時的數據一致性,只要保證在延時允許內數據副本最終和數據保持一致性,像我們用一臺計算機拜訪某個網站,另一臺計算機也同時拜訪這個網站,假設這兩臺或者是更多的計算機拜訪同一個網站時,如果這些計算機不在一個網段上,也就是處于不同的節點上,它們從網站服務器上獲取的數據可能在很短的時間內是不同的,但是最終它們獲得的數據必須是一致的,這樣才能保證服務器提供正常的服務.

非關系型數據能在大數據存儲上應用廣泛,很大程度上還是因為非關系型數據庫在分布式數據存儲的優秀表現.像Google之前提出的關系型分布式存儲系統也具備比擬靈活的擴展性,并且也不影響RBMS的其他性能,但是并沒有得到大范圍的使用.
《No-SQL數據庫為什么能適應分布式數據存儲?》是否對您有啟發,歡迎查看更多與《No-SQL數據庫為什么能適應分布式數據存儲?》相關教程,學精學透。維易PHP學院為您提供精彩教程。
同類教程排行
- 大數據學習——你知道Apache Cas
- 一張圖理清NoSQL、MPP和Hadoo
- 新思潮:NoSQL與DPDK、RDMA等
- CockroachDB 1.1發布 平均
- NoSQL的基本概念和分類比較 Redi
- 細數5款主流NoSQL數據庫到底哪家強?
- mongodb nosql 如何實現分頁
- 解析SQL與NoSQL的融合架構產品GB
- mongodb NOSQL 各種查詢條件
- 科普|大數據技術原理與應用(第五章 No
- 騰訊十多個人管理一萬多臺NoSQL存儲服
- NoSQL數據庫的分布式算法
- 如何學習及選擇大數據非關系型數據庫NoS
- SQL和NOSQL有區別嗎?
- 2017年度全球“大數據企業50強”
