Apache Spark 1.6發(fā)布
《Apache Spark 1.6發(fā)布》要點(diǎn):
本文介紹了Apache Spark 1.6發(fā)布,希望對(duì)您有用。如果有疑問(wèn),可以聯(lián)系我們。
維易PHP培訓(xùn)學(xué)院每天發(fā)布《Apache Spark 1.6發(fā)布》等實(shí)戰(zhàn)技能,PHP、MYSQL、LINUX、APP、JS,CSS全面培養(yǎng)人才。
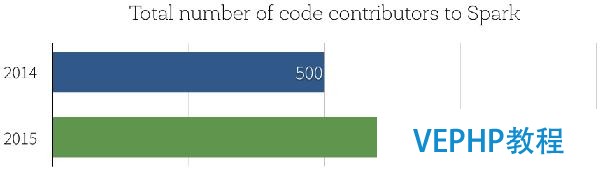
本日我們非常高興能夠發(fā)布Apache Spark 1.6,通過(guò)該版本,Spark在社區(qū)開(kāi)發(fā)中達(dá)到一個(gè)重要的里程碑:Spark源碼貢獻(xiàn)者的數(shù)據(jù)已經(jīng)超過(guò)1000人,而在2014年年末時(shí)人數(shù)只有500.
那么,Spark 1.6有什么新特性呢?Spark 1.6有逾千個(gè)補(bǔ)丁.在本博文中,我們將重點(diǎn)突出三個(gè)主要的開(kāi)發(fā)主題:性能提升、新的DataSet API和數(shù)據(jù)科學(xué)函數(shù)的擴(kuò)展.
性能提升
根據(jù)我們2015年Spark調(diào)查申報(bào),91%的用戶(hù)認(rèn)為性能是Spark最重要的方面,因此,性能優(yōu)化是我們進(jìn)行Spark開(kāi)發(fā)的一個(gè)重點(diǎn).
Parquet性能:Parquet已經(jīng)成為Spark中最常用的數(shù)據(jù)格式之一,同時(shí)Parquet掃描性能對(duì)許多大型應(yīng)用程序的影響巨大.在以前,Spark的Parquet讀取器依賴(lài)于parquet-mr去讀和解碼Parquet文件.當(dāng)我們?cè)诰帉?xiě)Spark應(yīng)用程序時(shí),必要花很多的時(shí)間在“記錄裝配(record assembly)”上,以使進(jìn)程能夠?qū)arquet列重建為數(shù)據(jù)記錄.在Spark 1.6中,我們引入了新的Parquet讀取器,它繞過(guò)parquert-mr的記錄裝配并使用更優(yōu)化的代碼路徑以獲取扁平模式(flat schemas).在我們的基準(zhǔn)測(cè)試當(dāng)中,通過(guò)5列測(cè)試發(fā)現(xiàn),該新的讀取器掃描吞吐率可以從290萬(wàn)行/秒增加到450萬(wàn)行/秒,性能提升接近50%.
自動(dòng)內(nèi)存管理:Spark 1.6中另一方面的性能提升來(lái)源于更良好的內(nèi)存管理,在Spark 1.6之前,Spark靜態(tài)地將可用內(nèi)存分為兩個(gè)區(qū)域:執(zhí)行內(nèi)存和緩存內(nèi)存.執(zhí)行內(nèi)存為用于排序、hashing和shuffling的區(qū)域,而緩存內(nèi)存為用于緩存熱點(diǎn)數(shù)據(jù)的區(qū)域.Spark 1.6引入一新的內(nèi)存管理器,它可以自動(dòng)調(diào)整不同內(nèi)存區(qū)域的大小,在運(yùn)行時(shí)根據(jù)執(zhí)行程序的必要自動(dòng)地增加或縮減相應(yīng)內(nèi)存區(qū)域的大小.對(duì)許多應(yīng)用程序來(lái)說(shuō),它意味著在無(wú)需用戶(hù)手動(dòng)調(diào)整的情況下,在進(jìn)行join和aggregration等操作時(shí)其可用內(nèi)存將大量增加.
前述的兩個(gè)性能提升對(duì)用戶(hù)來(lái)說(shuō)是透明的,使用時(shí)無(wú)需對(duì)代碼進(jìn)行修改,而下面的改進(jìn)是一個(gè)新API能夠保證更好性能的例子.
流式狀態(tài)管理10倍性能提升:在流式應(yīng)用程序當(dāng)中,狀態(tài)管理是一項(xiàng)重要的功能,常常用于維護(hù)aggregation或session信息.通過(guò)和許多用戶(hù)的共同努力,我們對(duì)Spark Streaming中的狀態(tài)管理API進(jìn)行了重新設(shè)計(jì),引入了一個(gè)新的mapWithState API,它可以根據(jù)更新的數(shù)量而非整個(gè)記錄數(shù)進(jìn)行線(xiàn)性擴(kuò)展,也便是說(shuō)通過(guò)跟蹤“deltas”而非總是進(jìn)行所有數(shù)據(jù)的全量掃描的方式更加高效.在許多工作負(fù)載中,這種實(shí)現(xiàn)方式可以獲得一個(gè)數(shù)量級(jí)性能提升.我們創(chuàng)建了一個(gè)notebook以說(shuō)明如何使用該新特性,不久后我們也將另外撰寫(xiě)相應(yīng)的博文對(duì)這部分內(nèi)容進(jìn)行說(shuō)明.
Dataset API
在本年較早的時(shí)候我們引入了DataFrames,它提供高級(jí)函數(shù)以使Spark能夠更好地理解數(shù)據(jù)結(jié)構(gòu)并執(zhí)行計(jì)算,DataFrame中額外的信息可以使Catalyst optimizer和Tungsten執(zhí)行引擎(Tungsten execution engine)自動(dòng)加速實(shí)際應(yīng)用場(chǎng)景中的大數(shù)據(jù)分析.
自從我們發(fā)布DataFrames,我們得到了大量反饋,其中缺乏編譯時(shí)類(lèi)型平安支持是諸多重要反饋中的一個(gè),為解決這該問(wèn)題,我們正在引入DataFrame API的類(lèi)型擴(kuò)展即Datasets.
Dataset API通過(guò)擴(kuò)展DataFrame API以支持靜態(tài)類(lèi)型和用戶(hù)定義函數(shù)以便能夠直接運(yùn)行于現(xiàn)有的Scala和Java類(lèi)型基礎(chǔ)上.通過(guò)我們與經(jīng)典的RDD API間的比擬,Dataset具有更好的內(nèi)存管理和長(zhǎng)任務(wù)運(yùn)行性能.
請(qǐng)參考Spark Datasets入門(mén)這篇博文.
新數(shù)據(jù)科學(xué)函數(shù)
機(jī)器學(xué)習(xí)流水線(xiàn)持久化:許多機(jī)器學(xué)習(xí)應(yīng)用利用Spark ML流水線(xiàn)特性構(gòu)建學(xué)習(xí)流水線(xiàn),在過(guò)去,如果程序想將流水線(xiàn)持久化到外部存儲(chǔ),需要用戶(hù)自己實(shí)現(xiàn)對(duì)應(yīng)的持久化代碼,而在Spark 1.6當(dāng)中,流水線(xiàn)API提供了相應(yīng)的函數(shù)用于保留和重新加載前一狀態(tài)的流水線(xiàn),然后將前面構(gòu)建的模型應(yīng)用到后面新的數(shù)據(jù)上.例如,用戶(hù)通過(guò)夜間作業(yè)訓(xùn)練了一個(gè)流水線(xiàn),然后在生產(chǎn)作業(yè)中將其應(yīng)用于生產(chǎn)數(shù)據(jù).
新的算法和能力:本版本同時(shí)也增加了機(jī)器學(xué)習(xí)算法的范圍,包含:
- 單變量和雙變量統(tǒng)計(jì)
- 存活分析
- 最小二乘法尺度方程
- 平分K均值聚類(lèi)
- 聯(lián)機(jī)假設(shè)檢驗(yàn)
- ML流水線(xiàn)中的隱含狄利克雷分布(Latent Dirichlet Allocation,LDA)
- 廣義線(xiàn)性模型(General Liner Model,GLM)類(lèi)R統(tǒng)計(jì)
- R公式中的特征交互
- GLM實(shí)例權(quán)重
- DataFrames中的單變量和雙變量統(tǒng)計(jì)
- LIBSVM數(shù)據(jù)源
- 非尺度JSON數(shù)據(jù)
本博文只給出了本發(fā)布版本中的主要特性,我們也編譯了.
在接下來(lái)的幾周內(nèi),我們將陸續(xù)推出對(duì)這些新特性進(jìn)行更詳細(xì)說(shuō)明的博文,請(qǐng)繼承關(guān)注Databricks博客以便了解更多關(guān)于Spark 1.6的內(nèi)容.如果你想試用這些新特性,Databricks可以讓你在保存老版本Spark的同時(shí)使用Spark 1.6.注冊(cè)以獲取免費(fèi)試用帳號(hào).
若沒(méi)有1000個(gè)源碼貢獻(xiàn)者,Spark現(xiàn)在不可能如此成功,我們也趁此機(jī)會(huì)對(duì)所有為Spark貢獻(xiàn)過(guò)力量的人表現(xiàn)感謝.
原文地址:Announcing Spark 1.6(譯者/牛亞真 審校/朱正貴 責(zé)編/仲浩)
譯者介紹:牛亞真,中科院計(jì)算機(jī)信息處置專(zhuān)業(yè)碩士研究生,關(guān)注大數(shù)據(jù)技術(shù)和數(shù)據(jù)挖掘方向.
轉(zhuǎn)載請(qǐng)注明本頁(yè)網(wǎng)址:
http://www.fzlkiss.com/jiaocheng/13026.html
同類(lèi)教程排行
- apache常用配置指令說(shuō)明
- Hive實(shí)戰(zhàn)—通過(guò)指定經(jīng)緯度點(diǎn)找出周?chē)?/a>
- Apache2.2之httpd.conf
- apache怎么做rewrite運(yùn)行th
- 獨(dú)家|一文讀懂Apache Kudu
- Apache 崩潰解決 -- 修改堆棧大
- Apache 個(gè)人主頁(yè)搭建
- Apache OpenWhisk架構(gòu)概述
- Apache自動(dòng)跳轉(zhuǎn)到 HTTPS
- 深入理解Apache Flink核心技術(shù)
- Apache Kylin查詢(xún)性能優(yōu)化
- Apache Flume 大數(shù)據(jù)ETL工
- Apache Flink異軍突起受歡迎!
- apache常見(jiàn)錯(cuò)誤代碼
- Apache MADlib成功晉升為Ap
