理解APACHE SOLR默認的評分機制
《理解APACHE SOLR默認的評分機制》要點:
本文介紹了理解APACHE SOLR默認的評分機制,希望對您有用。如果有疑問,可以聯(lián)系我們。
Apache Solr是基于Apache Lucene的企業(yè)級開源平臺.希望通過本文你能了解Solr/Lucene的默認評分機制,以及哪些因子會影響搜索結(jié)果的排序.
首先看一下Lucene的評分公式,
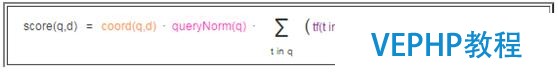
以下是對公式中各個因子的詳細解釋:
1. tf(t in d) 關(guān)聯(lián)詞出現(xiàn)的頻率,詞頻率是指搜索詞t 在文檔d 中出現(xiàn)的次數(shù).文檔中搜索詞出現(xiàn)次數(shù)越多總評分也就越高.tf(t in d)默認的實現(xiàn)是:
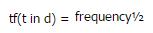
2. idf(t) 關(guān)聯(lián)到反轉(zhuǎn)文檔頻率,文檔頻率(docFreq)指出現(xiàn)過詞 t的文檔數(shù)量.docFreq 越少 idf 就越高(物以稀為貴).idf(t)不只要反映詞t在文檔中的反轉(zhuǎn)頻率,還要反映詞t在所有搜索詞中的反轉(zhuǎn)頻率,所以你會在評分公式中看到idf(t)有個平方.idf(t)默認的實現(xiàn)是:
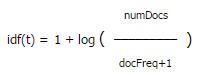
3. coord(q,d)評分因子,是基于文檔中出現(xiàn)查詢詞的個數(shù).越多的查詢詞在一個文檔中,說明些文檔的匹配程序越高.默認是出現(xiàn)查詢項的百分比.
4. queryNorm(q)一個標準的查詢因子,使不同查詢之間可以比擬.此因子不影響文檔的排序,因為所有有文檔都會使用此因子.queryNorm(q)默認的實現(xiàn)是:

每個查詢項權(quán)重的平分方和(sumOfSquaredWeights)由 Weight 類完成.例如 以下是BooleanQuery的計算公式:
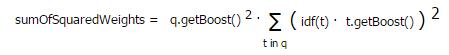
5. t.getBoost()查詢時,詞t的加權(quán)值(如:jakarta^4 apache,其中詞jakarta的加權(quán)值就是4),或者可以在程序中使用 setBoost()辦法來給詞加權(quán).
6. norm(t,d)封裝索引期間的加權(quán)和長度因子(如果想忽略該因素,可以在schema.xml中定義字段時加上omitNorms=”true”屬性),以下是關(guān)于加權(quán)和長度因子的解釋:
· Field boost – 字段加權(quán),在將字段內(nèi)容索引到solr文檔之前,通過調(diào)用 field.setBoost()為字段加權(quán).
· lengthNorm(field) – 由字段中的 Token 的個數(shù)來計算此值,字段越短,評分越高.
以上所有因子相乘得出norm值,如果文檔中有相同的字段,它們的加權(quán)也會相乘:

索引的時候,把 norm 值壓縮(encode)成一個 byte 保留在索引中.搜索的時候再把索引中 norm 值解壓(decode)成一個 float 值.所以在真正搜索的時候,norm值是無法改變的.
Solr的默認評分算法可以滿足大部門業(yè)務(wù)需求,如果你當前的業(yè)務(wù)需求非常復(fù)雜且默認算法無法滿足,你也可以自定義評分算法.
《理解APACHE SOLR默認的評分機制》是否對您有啟發(fā),歡迎查看更多與《理解APACHE SOLR默認的評分機制》相關(guān)教程,學(xué)精學(xué)透。維易PHP學(xué)院為您提供精彩教程。
轉(zhuǎn)載請注明本頁網(wǎng)址:
http://www.fzlkiss.com/jiaocheng/13030.html
同類教程排行
- apache常用配置指令說明
- Hive實戰(zhàn)—通過指定經(jīng)緯度點找出周圍的
- Apache2.2之httpd.conf
- apache怎么做rewrite運行th
- 獨家|一文讀懂Apache Kudu
- Apache 崩潰解決 -- 修改堆棧大
- Apache 個人主頁搭建
- Apache OpenWhisk架構(gòu)概述
- Apache自動跳轉(zhuǎn)到 HTTPS
- 深入理解Apache Flink核心技術(shù)
- Apache Kylin查詢性能優(yōu)化
- Apache Flume 大數(shù)據(jù)ETL工
- Apache Flink異軍突起受歡迎!
- apache常見錯誤代碼
- Apache MADlib成功晉升為Ap
