Apache Kylin大數據分析平臺的演進
《Apache Kylin大數據分析平臺的演進》要點:
本文介紹了Apache Kylin大數據分析平臺的演進,希望對您有用。如果有疑問,可以聯系我們。
[來自IT168]
【IT168 專稿】本文根據2016第七屆中國數據庫大會現場演講嘉賓李揚老師分享內容整理而成.錄音及文字編輯@田曉旭@老魚.
講師簡介:
李揚,上海Kyligence聯合創始人兼CTO,Apache Kylin 聯合創建者及項目管理委員會成員(PMC), 主創團隊架構師和技術負責人,專注于大數據分析、并行計算、數據索引、關系數學、近似算法、壓縮算法等前沿技術.

上海Kyligence聯合創始人兼CTO 李揚
曾任eBay全球分析基礎架構部大數據資深架構師、IBM InfoSphere BigInsights的技術負責人,負責Hadoop開源產品架構,“杰出技術貢獻獎”的獲獎者、摩根士丹利副總裁,負責全球監管報表基礎架構.
正文:
我是來自Kyligence的李揚,是上海Kyligence的聯合創始人兼CTO.今天我主要來和大家分享一下來Apache Kylin 1.5的新功能和架構改變.
Apache Kylin是什么

Kylin是最近兩年發展起來的開源項目,在國外的知名度不是很高,但是在中國廣為人知.Kylin的定位是Hadoop大數據平臺上的多維分析工具,最早是由eBay在上海的研究實驗室孵化的,提供ANSI-SQL接口,支持非常大的數據集,未來期望能夠在秒級別返回查詢結果.Kylin于2014年10月開源,現在已經成為為數不多的全部由華人主導的Apache頂級項目.
1.SQL Interface

大多數的Hadoop分析工具和SQL是友好的,所以Apache Kylin擁有SQL接口這一點就顯得尤為重要.Kylin的ANSI SQL可以替代HIVE的很大一部分工作,如果不使用HIVE本地方言的話,那么Kylin和HIVE幾乎完全兼容,也是SQL on Hadoop的一員.
Kylin和其它SQL ON Hadoop的主要區別是離線索引.用戶在使用之前先選擇一個HIVE Table的集合,然后在這個基礎上做一個離線的CUBE構建,CUBE構建完了之后就可以做SQL查詢了.SQL數據下的關系表模型和原本的HIVE Table的一模一樣,所以原來的HIVE查詢可以原封不動的遷移到Kylin上面直接運行.
用離線計算來代替在線計算,在離線過程當中把復雜的、計算量很大的工作做完,在線計算量就會變小,就可以更快的返回查詢結果.通過這種方式,Kylin可以有更少的計算量,更高的吞吐量.
2.Big Data
2015年eBay頒布Kylin已經有接近千億的數據規模,2016年肯定已經穩穩的超過千億了.但是這也可能不是Kylin的最大案例,因為根據我們在中國移動得到的數據,他們每天可能就有百億的增量數據要放到Kylin的系統里面,可能十天就超過千億了.國內很多一線互聯網企業也都在使用Kylin技術來進行多維數據分析.

3.Low Latency
Kylin的查詢性能相當不錯,這也是當初它的設計目標.我們的目標是在秒級別能夠返回查詢結果,在實際生產系統里面,Kylin 90%的查詢都可以在穩定的三秒內返回,而且這并不是一條兩條特別的SQL可以做到這個性能,而是在數萬條不一樣的、在各種復雜的查詢下的SQL都可以做到這樣.
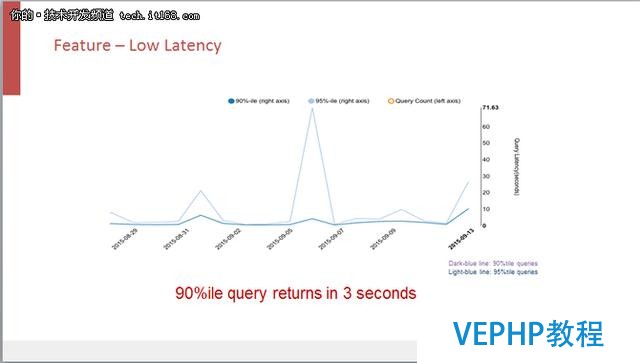
從圖中可以看到,在某一天Kylin的查詢延遲有一個山峰,所以不是說只要用了Kylin所有的查詢就一定快,但是經過調優大多數的查詢都會很快速.
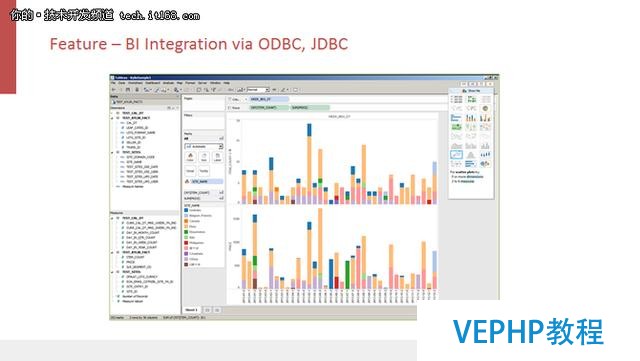
4.BI工具的集成
Kylin提供了標準的ODBC和JDBC接口,能夠和傳統BI工具進行很好的集成.分析師們可以用他們最熟悉的工具來享受Kylin帶來的快速.
5.Scalable Throughput
Kylin是用離線計算來代替在線計算,相比于其他的工具,在線計算量較小,能夠在固定的硬件配置上面擁有更高的吞吐率.
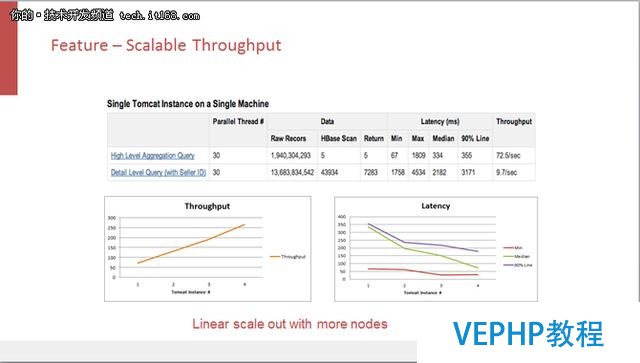
這是在兩條比較復雜的查詢下查看Kylin的線性擴展能力的實驗.我們在一個比較簡單的機器上面增加Kylin的查詢引擎的個數,從圖中可以看出Kylin在從一個實例加到四個實例的過程中吞吐量是呈線性上漲的,Kylin每秒可以支持大約250個查詢.當然,這個實驗還沒有探測到整個系統的瓶頸,根據理論,Kylin系統的瓶頸最后會落在他的存儲引擎上面.所以,在存儲有保障的前提下,我們可以通過擴展存儲引擎來擴展Kylin的吞吐量.
Apache Kylin 1.5新特性
1.可擴展架構
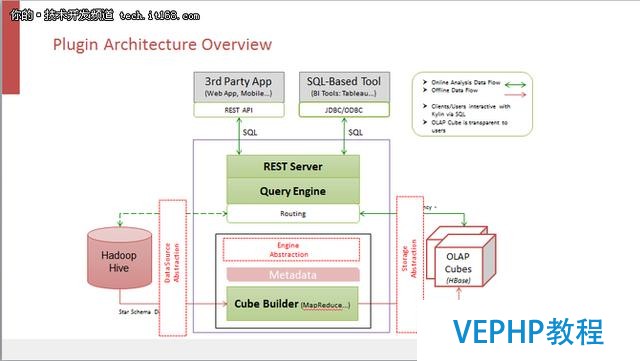
Kylin采用的是一個可擴展的架構.用戶的數據首先是落在HIVE里面,然后根據META DATA定義的CUBE描述,進行離線CUBE構建,構建完成的CUBE結果存放在HBase里面.當查詢從頂部過來的時候,不管是SQL接口或者是Rest API接口,查詢引擎都會把這個查詢引導到構建好的CUBE當中去返回結果,不需要再去查原本的HIVE數據,這種方式大大的提高了系統性能.
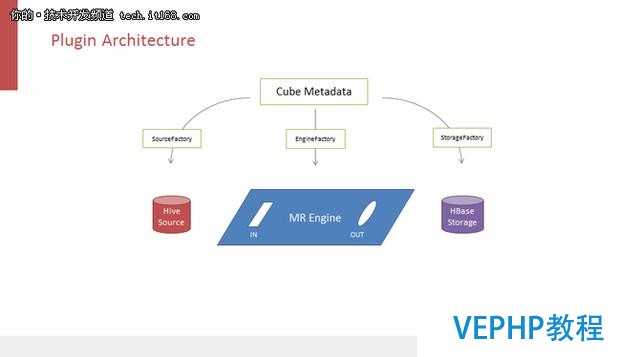
所謂可擴展的架構是指把Kylin三個依賴的接口抽象出來,從而在一定程度上替換它們.Kylin的三大依賴分別是HIVE Source、MapReduce分布式計算引擎以及存儲引擎HBase,它們都是通過原數據來驅動的,即需要在CUBE原數據上聲明數據源、構建引擎和存儲系統.通過工廠類初始化三個依賴,它們之間是沒有關聯的,彼此不能夠了解對方的存在,所以也不能一起工作.后面用個適配器的模式,想象下面MapReduce Engine作為一個主板,它有一個輸入槽和一個輸出槽,分別用來連接左側DataSource和右側的Storage.從HIVE和HBase分別產生構造出一個適配器部件,把它們插在主板上以后,這三個部件就聯通了,數據就可以從左側流到右側,完成實現整個CUBE構建的過程.

有了上述的基礎,我們就可以在Kylin系統上面來嘗試不一樣的構建引擎、數據源以及存儲引擎.我們曾經嘗試將Spark作為Kylin CUBE的構建引擎,但是從實驗結果來看,Spark引擎暫時并沒有帶來特別高的性能提升.目前,數據源除了HIVE以外,現在也可以連接Spark和Kafka.存儲引擎是大家最為關注的,一開始,選用HBase作為Kylin的存儲引擎時,大家都很不解,也有很多人表示為什么不試一下Kudu或者其他的存儲引擎呢,有了這個可擴展架構,大家可以親自來嘗試不同的存儲引擎.

整個可擴展架構帶來了很多好處,首先就是自由度,之前Kylin等于是綁死在Hadoop平臺上面,依賴HIVE,MapReduce和HBase.有了這個架構以后,就可以嘗試一些不一樣的替代技術.其次是可擴展性,系統可以接受各種數據源,例如Kafka,也可以接受更好的分布式計算引擎Spark等.第三是靈活度,不一樣的構建算法適合不一樣的數據集.有了靈活度以后,就可以在整個系統中同時存在很多種不一樣的CUBE構建算法,用戶可以根據自己數據集的特性來指定當中的某一個.
2.Layered Cubing
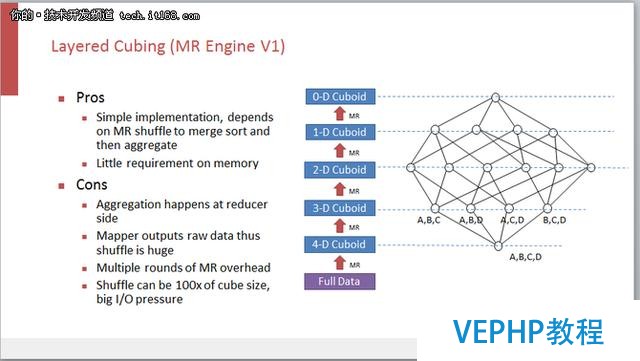
MRv1是一個比較老的CUBE的引擎,采用的是一個非常質樸的CUBE構建算法.上圖所示是一個分層的CUBE構建的過程,先Group by A、B、C、D四個維度,算完了這個四級維度的一層以后,再用四級維度的結果來算三級維度的一層,依此類推,分別算出二級和一級維度的結果.
這種分層模式可以利用MapReduce的 shuffling 和 merge sort 做完了很多Aggregation,從而減少開發量.但同時也帶來了一些問題,因為Aggregation都發生在Reduce端,Map端是直接把原數據給扔在網絡上,然后靠MapReduce的shuffling讓數據匯總到Reduce端,所以這就帶來了很大的網絡開銷,而網絡又偏偏是大多數Hadoop系統的瓶頸.相關數據顯示了這樣的Layered Cubing給網絡的壓力相當于一百個CUBE的大小,也就是說如果CUBE有10T的話,那么網絡的壓力可能就是一千個T.
3.Fast Cubing
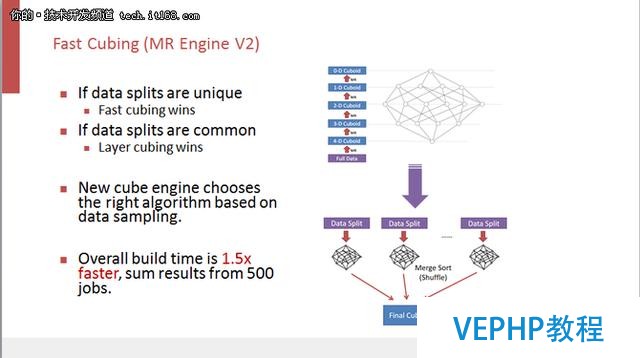
如何辦理這個瓶頸問題,下面為大家分享一個新算法Fast Cubing,它是逆向思考,既然數據在Reduce端做聚合會有很多網絡壓力,那么可不可以把聚合放到Map端來做,然后把聚合完的結果通過網絡進行傳輸,在Reduce端做最終的聚合,這樣的話,Reduce端收到的數據就會變少,網絡壓力就會變輕.目前比較經典的多維分析多是用內存來做多維計算,我們采用類似的技術在Map端分配比較大的內存,用比較多的CPU做In-mem cubing,這樣做的效果類似于Layered發生在Map端.這些過程完成之后得到的是已經聚合過的數據,再通過網絡分發到Reduce端做最終的聚合.這種方式的缺點是算法較為復雜,開發和維護比較困難,但是可以減輕網絡壓力.
我們把兩個算法放到實際的生產環境當中去比較,發現其實并不總是Fast Cubing會更快.我們期望Map端的預先聚合可以減少網絡shuffling,但其實不一定是這樣,因為這取決于數據分布.例如我們的期望結果是李揚在十月一號一共買了多少東西,消費總金額是多少,那么這取決于消費記錄是只出現在一個data splits里面還是出現在所有的Map的data splits里面.如果記錄只出現在一個Map上,那么聚合完的結果不需要去和其他的Map做第二次的聚合,網絡分發比較快.但是如果不幸,交易記錄被均勻分散到了所有的Map上,那么還是要通過網絡分發很多次,然后在Reduce再做第二次的聚合,這樣的話相比前面的Layered Cubing沒有多少的改進.
如果Map的data splits是比較獨特,每個Map會生成不同的CUBE數據,然后分發也不會重復,那么Fast Cubing確實會減少網絡的傳輸.但是反過來,如果每個Map的數據都有雷同,那么就還是會造成網絡的壓力,所以在MRv2里面最后搭載的是一個混合算法.先對數據做采樣,根據數據樣本來判斷這個數據集在Map上面的分配是獨特的還是有重復,然后根據這樣的特性來選擇采用Layered Cubing 還是Fast Cubing.我們通過在500個不一樣的生產環境中的測試發現這種混合算法要比原來的MRv1快1.5倍.
4.Parallel Scan
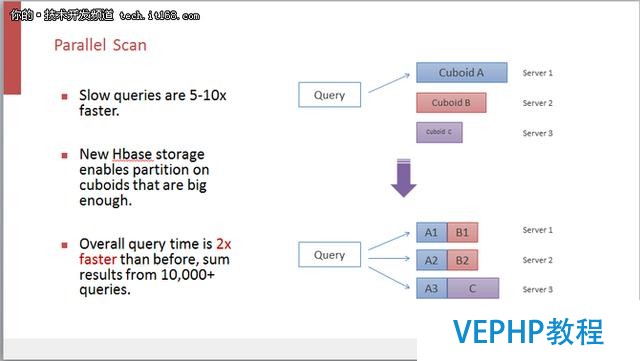
并行掃描是一個十分直觀的改進.在之前的Kylin版本里面數據聚合完以后密度非常高,而且因為數據聚合過,返回集很小,不需要掃描太大的數據集就能夠返回SQL查詢的結果.但是對于一些比較復雜或者本身比較慢的查詢,盡管經過了聚合,但是數據還是有百萬、千萬條,那么在運行時候還是要掃描很多數據,這時候簡單的串行掃描顯然就不適合了.如果調整一下數據的存儲結構,做一些分區.通過掃描物化視圖來產生查詢結果,把存在一個結點上的物化視圖均勻的分散在多個結點上,那么串行掃描就變成了并行掃描.
這個改進可以使慢的查詢速度提升五到十倍左右,不過從實際情況來看提升并沒有那么多,因為原本大多數Kylin的查詢已經比較快了,掃描數據本來就不多.通過對一萬條左右生產狀態查詢結果的比較,我們發現,引入并行掃描的技術之后,速度大概會提升兩倍左右.
5.近實時
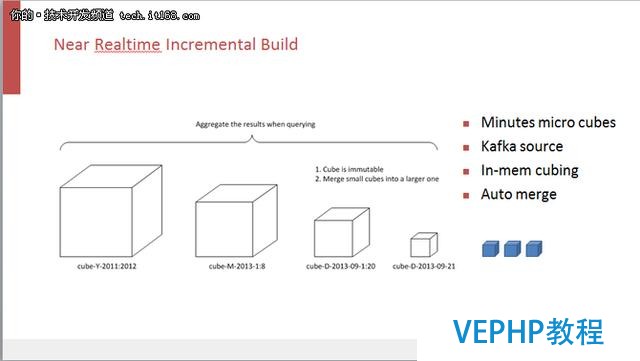
Apache Kylin 1.5的另一個特性就是近實時的構建,它是延續之前的增量構建.Kylin和很多大數據系統一樣,在對數據做預處理的時候,會對數據做一個增量的預處理,即不是把過去所有的數據每天都算一遍,而是每天只計算今天的數據,再去和歷史數據做匹配.所以首先要把整個數據集依照時間線來做分割,時間距離最遠的數據會比較大塊,可能是按年的,中間的可能是按月,最小的一個數據集是今天的.如果要做到近實時的話,只需要把每天增量構建的時間力度進一步的切小,可以從天縮小到小時,小時縮小到分鐘,依照這個思路就可以很順暢的完成近實時的CUBE構建.
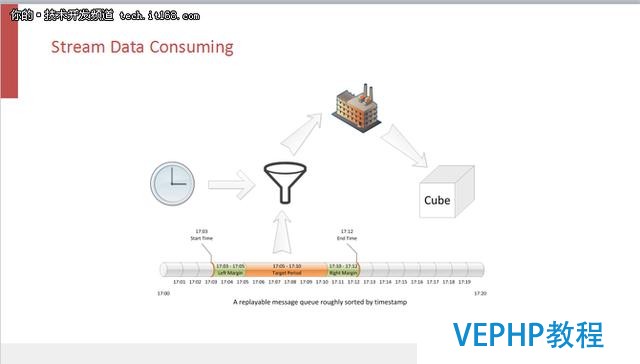
這是我們在1.5里面嘗試的一個案例,其中數據源來自Kafka的Source,算法使用Fast Cubing .這樣的搭配看起來很完美,其實不然,它會產生很多的CUBE碎片,例如今天的五分鐘就是一個獨立的數據集,它會產生一個獨立的CUBE碎片.當這個碎片越來越多的時候,查詢性能就會下降,一個查詢命令需要命中很多個碎片,每一個都要執行存儲層的一次Scan的操作.
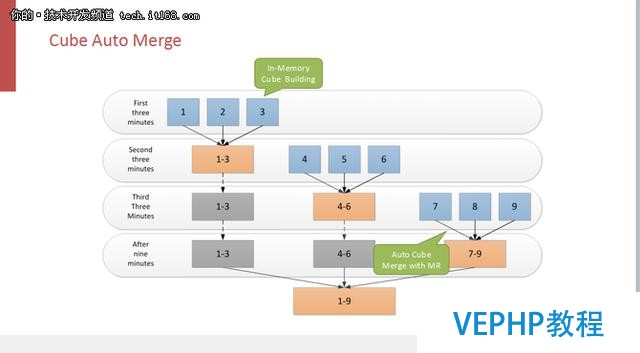
解決的辦法也很簡單,那就是合并CUBE碎片,但是這個合并是自動的常態,不需人為手工來觸發.新版本里用戶可以配置自動合并,把五分鐘的碎片合并成半小時,半小時合并到四小時,四小時合并到一天,天合并到周,周合并到月.
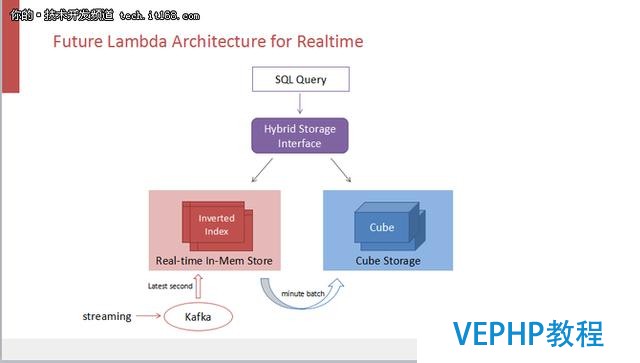
如果五分鐘的近實時仍然不滿足需求的話,可以把他近化成一個Lambda架構,即在CUBE的存儲之外再配上一個實時的內存存儲系統來記錄最后五分鐘的數據.CUBE五分鐘近實時離真正的實時就差五分鐘的數據,把這些數據放在內存里面,用一個混合的查詢接口來同時擊中內存引擎和CUBE存儲,那么匯總的結果就是一個真實實施的結果集了.但是,遺憾的是目前這個想法還未實現.

在eBay頒布的使用案例里面有一個Kylin新版本近實時CUBE構建的案例——SEO Dashboard,它是對查詢引擎導入的用戶流量進行監控.實時監控從谷歌或者雅虎進來的消費者的記錄,實時監控流量起伏,一旦發現用戶流量在五分鐘內有抖動的話,立即采取相應的措施,從而保證eBay的交易量營收的穩定.
6.用戶自定義聚合類型

1.5的另外一個新功能是User Defined Aggregation Types,即用戶自定義聚合類型,以前Kylin有HyperLogLog(近似的Count Distinct算法).在這個基礎上面,新版本又加入了TopN以及社區貢獻的基于Big Map的精確Count Distinct和保存最底層原始數據的記錄Raw Records.用戶可以實現抽象接口擴展自己想要的聚合函數.例如,通過它來聚合很多用戶的事件,提取出用戶的拜訪模型,或者做一個很多點樣本的一個聚類,也可以把他預計算好,存成一個聚合的數據類型,所以這個自定義的函數可以擴展到很多領域.

TopN用的是一個很經典的算法,叫SpaceSaving,在很多的流式處理里面都有用到.我們把TopN介入到Kylin里面,定義成一個自定義的聚合函數.一般的SpaceSaving是一個單線程的算法,但是Kylin采用的是并行算法.
用戶TopN的查詢,例如抓取100個數據,寫成SQL語句如上圖所示.而Kylin會自動適配這樣的SQL來直接使用預聚合好的結果,所以在運行時候Kylin只是把預先算好的一千個,一萬個item直接返回就好了,這當中幾乎就沒有在線計算,速度就會很快.
7.分析工具的集成
在新版本里面Kylin也增加了ODBC的一些接口,主要是實現了對Tableau 9的集成,以及和MS Excel、MS Power BI的集成.
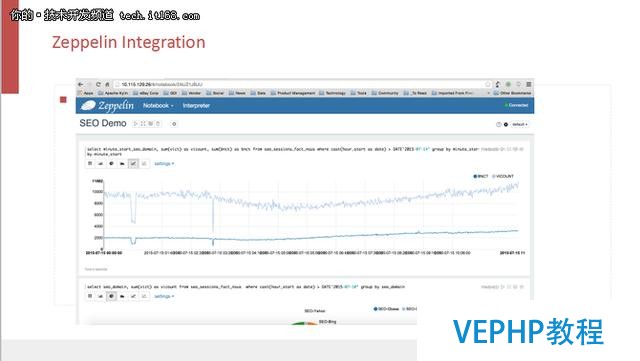
Zeppelin 的集成模塊也已經共享在Zeppelin 開源社區,大家可以在Zeppelin 最新的發布版里面找到,另外,直接從Zeppelin 里面也可以調用Kylin的數據.
總結

總的來說,Apache Kylin 1.5有以下幾個新亮點:1.可擴展的架構,這個新的架構等于是打開了Kylin對于其他的可替換技術的一個大門,我們可以選擇除了MapReduce之外的其他并行計算引擎,比如Spark,也可以選擇不一樣的數據源,甚至不一樣的storage.這樣可以保證Kylin可以和其他的并行計算、大數據技術一起來演化而不是鎖死在某個平臺上面.2.新的CUBE引擎,因為引入了一個新的Fast Cubing的算法,速度提升大概達到原來的1.5倍左右,3.并行掃描,存儲結構的改良使查詢的速度提升了大約兩倍.4.近實時分析,盡管還在產品測試的階段,但是,大家可以來社區使用,發現問題可以和我們及時溝通.5.用戶自定義聚合類型,這個部分在未來應該有很大的發展空間.6.集成了更多的分析工具.
以上就是我想和大家分享的內容,Kylin是個開源產品,所以歡迎大家有興趣的來使用,并且跟我們在社區上面互動,有任何問題我們社區都是很樂意來幫助大家辦理.
維易PHP培訓學院每天發布《Apache Kylin大數據分析平臺的演進》等實戰技能,PHP、MYSQL、LINUX、APP、JS,CSS全面培養人才。
