關于移動客戶端中使用 SQLite看這篇就夠了
《關于移動客戶端中使用 SQLite看這篇就夠了》要點:
本文介紹了關于移動客戶端中使用 SQLite看這篇就夠了,希望對您有用。如果有疑問,可以聯系我們。
導語
iOS 程序能從網絡獲取數據.少量的 KV 類型數據可以直接寫文件保存在 Disk 上,App 內部通過讀寫接口獲取數據.稍微復雜一點的數據類型,也可以將數據格式化成 JSON 或 XML 方便保存,這些通用類型的增刪查改辦法也很容易獲取和使用.這些解決方案在數據量在數百這一量級有著不錯的表現,但對于大數據應用的支持則在穩定性、性能、可擴展性方面都有所欠缺.在更大一個量級上,移動客戶端需要用到更專業的桌面數據庫 SQLite.
這篇文章主要從 SQLite 數據庫的使用入手,介紹如何合理、高效、便捷的將這個桌面數據庫和 App 全面結合.避免 App 開發過程中可能遇到的坑,也提供一些在開發過程中通過大量實踐和數據對比后總結出的一些參數設置.整篇文章將以一個個具體的技術點作為講解單元,從 SQLite 數據庫生命周期起始講解到其終結.希望無論是從微觀還是從宏觀都能給工程師以贊助.

一、SQLite 初始化
在寫提綱的時候發現,原來 SQLite 初始化竟然是技術點一點也不少.
1. 設置合理的 page_size 和 cache_size
PRAGMA schema.page_size = bytes;
PRAGMA schema.cache_size = pages;
網上有很多的文章提到了,在內存允許的情況下增加 page_size 和 cache_size 能夠獲得更快的查詢速度.但過大的 page_size 也會造成 B-Tree 查詢退化到二分查找、CPU 占用增加以及 OS 級 cache 命中率的下降的問題.
通過反復比較測試不同組合的 page_size、cache_size、table_size、存儲的數據類型以及各種可能的增刪查改比例,我們發現后三者都是引起 page_size 和 cache_size 性能波動的因素.也就是說對于不同的數據庫并不存在普遍適用的 page_size 和 cache_size 能一勞永逸的幫我們辦理問題.
并且在對比測試中我們發現 page_size 的選取往往會出現一個拐點.拐點以前隨著 page_size 增加各種性能指標都會持續改善.但一旦過了拐點,性能將沒有明顯的改變,各個指標將圍繞拐點時的數據值小范圍波動.
那么如何選取合適的 page_size 和 cache_size 呢?
上一點我們已經提到了可能影響到 page_size 和 cache_size 最優值選取的三個因素:
table_size
存儲的數據類型
增刪查改比例
我們簡單的分析一下看看為什么這三個變量會共同作用于 page_size 和 cache_size.
SQLite 數據庫把其所存儲的數據以 page 為最小單位進行存儲.cache_size 的含義為當進行查詢操作時,用多少個 page 來緩存查詢結果,加快后續查詢相同索引時方便從緩存中尋找結果的速度.
了解了兩者的含義,我們可以發現.SQLite 存儲等長的 int int64 BOOL 等數據時,page 可以優化對齊地址存儲更多的數據.而在存儲變長的 varchar blob 等數據時,一則 page 因為數據變長的影響無法提前計算存儲地址,二則變長的數據往往會造成 page 空洞,空間利用率也有下降.
下表是設置不同的 page_size 和 cache_size 時,數據庫操作中最耗時的增查改三種操作分別與不同數據類型,表列數不同的表之間共同作用的一組測試數據.
其中各列數據含義如下,時間單位為毫秒
A = page_size(bytes)
B = cache_size(個)
C = DBThread
D = UIThread
E = Insert 60000 row to TABLE E(25 columns, 10 integer, 15 varchar, 1 blob)
F = Insert 80000 row to TABLE F(7 column, 6 integer, 1 varchar)
G = update 2000 row of TABLE E with WHERE clause, select 50 row from TABLE J, at last update 2000 row of TABLE E with WHERE clause again
H = insert 40000 row to TABLE H(9 columns, 8 integer, 1 varchar)
J = insert 50 row to TABLE J(15 columns, 11 integer, 2 varchar, 2 blob)
K = DB File size(MB)
L = memory usage peak size(MB)
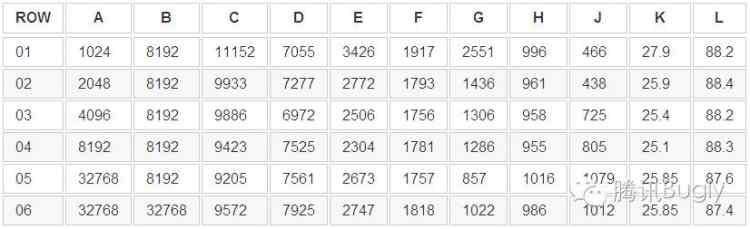
從上表我們看到,放大 page_size 和 cache_size 并不能不斷的獲得性能的提升,在拐點以后提升帶來的優化不明顯甚至是副作用了.這一點甚至體現到了數據庫大小這方面.從 G 列可以看到,page_size 的增加對于數據庫查詢的優化明顯優于插入操作的優化.從05、06行可以發現,增加 cache_size 對于數據庫性能提升并不明顯.從 J 列可以看到,當插入操作的數據量比較小的時候,反而是小的 page_size 和 cache_size 更有優勢.但 App DB 耗時更多的體現在大量數據增刪查改時的性能,所以選取合適的、稍微大點的 page_size 是合理的.
所以通過表格分析以后,我們傾向于選擇 DB 線程總耗時以及線程內部耗時最多的三個辦法,作為衡量 page_size 優劣的參考標準.
page_size 有兩種設置辦法.一是在創建 DB 的時候進行設置.二是在初始化時設置新的 page_size 后,需要調用 vacuum 對數據表對應的節點重新計算分配大小.這里可參考 pragma_page_size 官方文檔
https://www.sqlite.org/pragma.html#pragma_page_size
2. 通過 timer 控制數據庫事務定時提交
Transaction 是任何一個數據庫中最核心的功能,但其對 Server 端和客戶端的意義卻不盡相同.對 Server 而言,一個 Transaction 是主備容災分片的最小單位(當然還有其他意義).對客戶端而言,一個 Transaction 能夠大大的提升其內部的增刪查改操作的速度.SQLite 官方文檔以及工程實測的數據都顯示,事務的引入能提升性能 兩個數量級 以上.
實現方案其實非常簡單.程序初始化完畢以后,啟動一個事務,并創建一個 repeated 的 Timer
// sqlite3_exec(db, "BEGIN TRANSACTION", NULL, NULL, &sErrMsg);Statement begin(GetCachedStatement(SQL_FROM_HERE, "BEGIN TRANSACTION"));
begin.Run();
m_timer.reset(base::ForegroundTimer::Create());m_timer->Start(FROM_HERE, base::TimeDelta::FromSeconds(5), this, &RenewTransaction);
在 Timer 的回調函數 RenewTransaction 中,提交事務,并新啟動一個事務.
void RenewTransaction()
{
// sqlite3_exec(db, "COMMIT", NULL, NULL, &sErrMsg);
Statement commit(GetCachedStatement(SQL_FROM_HERE, "COMMIT"));
commit.Run();
// sqlite3_exec(db, "BEGIN TRANSACTION", NULL, NULL, &sErrMsg);
Statement begin(GetCachedStatement(SQL_FROM_HERE, "BEGIN TRANSACTION"));
begin.Run();
}
這樣就能實現自動化的事務管理,將優化的實現黑盒化.邏輯使用方能將更多精力集中在邏輯實現方面,不用關心性能優化、數據丟失方面的問題.
從手動事務管理到自動事務管理會引發一個問題:
當兩份數據必須擁有相同的生命周期,同時寫入 DB、同時從 DB 刪除、同時被修改時,通過時間作為提交事務的唯一標準,就有可能引發兩份數據的操作進入了不同的事務.而第二個事務如果不能正確的提交,就會造成數據丟失或錯誤.
解決這個問題,可以利用 SQLite 的事務嵌套功能,設計一組開啟事務和關閉提交事務的接口,供邏輯使用者依照其需求調用事務的開始、提交和關閉.讓內層事務保證兩(多)份數據的完整性.
3. 緩存被編譯后的 SQL 語句
和其他很多編程語言一樣,數據庫使用的 SQL 語句也需要經過編譯后才能被執行使用.SQL 語句的編譯結果如果能夠被緩存下來,第二次及以后再被使用時就能直接利用緩存結果,大大減少整個操作的執行時間.與此同理的還有 Java 數學庫優化,通過把極其復雜的 Java 數學庫實現翻譯成 byte code,在調用處直接執行機器碼,能大大優化 Java 數學庫的執行速度和 C++ 持平甚至優于其.而對 SQLite 而言,一次 compile 的時間根據語句復雜程度從幾毫秒到十幾毫秒不等,對于批量操作性能優化是極其明顯的.
sprintf(strSQL, "INSERT INTO TABLEA VALUES (NULL, __1, __2, __3 __4, __5, __6, __7)");
sqlite3_prepare_v2(db, strSQL, BUFFER_SIZE, &stmt, &tail);
// cache stmt for later use
sqlite3_bind_text(stmt, 1, str1, -1, SQLITE_TRANSIENT);...
其實在上面的第2點中,已經是用一個專門的類將編譯結果保存下來.每次根據文件名稱和行號為索引,獲得對應位置的 SQL 語句編譯結果.為了便于大家理解,我在注釋中也將 SQLIite 內部最底層的辦法寫出來供大家參考和對比性能數據.
4. 數據庫完整性校驗
移動客戶端中的數據庫運行環境要遠復雜于桌面平臺和服務器.掉電、后臺被掛起、進程被 kill、磁盤空間不足等原因都有可能造成數據庫的損壞.SQLite 提供了檢查數據庫完整性的命令
PRAGMA integrity_check
該 SQL 語句的執行結果如果不為 OK ,則意味著數據庫損壞.程序可以通過 ROLLBACK 到一個稍老的版本等辦法來解決數據庫損壞帶來的不穩定性.
5. 數據庫升級邏輯
代碼管理可以用 git、svn,數據庫如果要做升級邏輯相對來說會復雜很多.好在我們可以利用 SQLite,在內部用一張 meta 表專門用于記錄數據庫的當前版本號、最低兼容版本號等信息.用好了這張表,我們就可以對數據庫是否需要升級、升級的路徑進行規范.
我們代入一個簡單銀行客戶的例子來說明如何進行數據庫的升級.
a. V1 版本對數據庫的要求非常簡單,保存客戶的賬號、姓、名、出生日期、年齡、信用這6列.以及對應的增刪查改,對應的SQL語句如下
CREATE TABLE IF NOT EXISTS USER (
localid INTEGER PRIMARY KEY,
firstname LONGVARCHAR DEFAULT '' NOT NULL,
lastname LONGVARCHAR DEFAULT '' NOT NULL,
birthdate LONGVARCHAR DEFAULT '' NOT NULL,
age INTEGER DEFAULT 0 NOT NULL,
credit INTEGER DEFAULT 0 NOT NULL)INSERT INTO USER (localid, firstname , lastname , birthdate , age, credit) VALUES (?, ?, ?, ?, ?, ?)SELECT localid, firstname, lastname, birthdate, age, credit FROM USER
并且在 meta 表中保存當前數據庫的版本號為1,向前兼容的版本為1,代碼如下
CREATE TABLE meta (key LONGVARCHAR NOT NULL UNIQUE PRIMARY KEY, value LONGVARCHAR)INSERT OR REPLACE INTO meta (key,value) VALUES (version, 1)INSERT OR REPLACE INTO meta (key,value) VALUES (last_compatible_version, 1)
b. V2 版本時需要在數據庫中增加客戶在銀行中的存款和欠款兩列.首先我們需要從 meta 表中讀取用戶的數據庫版本號.增加了兩列后創建 table 和增刪查改的 SQL 語句都要做出適當的修改.代碼如下
SELECT value FROM meta WHERE key=versionSELECT value FROM meta WHERE key=last_compatible_versionCREATE TABLE IF NOT EXISTS USER (
localid INTEGER PRIMARY KEY,
firstname LONGVARCHAR DEFAULT '' NOT NULL,
lastname LONGVARCHAR DEFAULT '' NOT NULL,
birthdate LONGVARCHAR DEFAULT '' NOT NULL,
age INTEGER DEFAULT 0 NOT NULL,
credit INTEGER DEFAULT 0 NOT NULL,
deposit INTEGER DEFAULT 0 NOT NULL,
debt INTEGER DEFAULT 0 NOT NULL)INSERT INTO USER (localid, firstname , lastname , birthdate, age, credit, deposit) VALUES (?, ?, ?, ?, ?, ?, ?, ?)SELECT localid, firstname, lastname, birthdate, age, credit, deposit, debt FROM USER
很顯然 V2 版本的 SQL 語句很多都和 V1 是不兼容的.V1 的數據使用 V2 的 SQL 進行操作會引發異常產生.所以在 SQLite 封裝層,我們需要根據當前數據庫版本分別進行處理.V1 版本的數據庫需要通過 ALTER 操作增加兩列后使用.記得升級完畢后要更新數據庫的版本.代碼如下
if (1 == currentVersion) { ALTER TABLE USER ADD COLUMN deposit INTEGER DEFAULT 0 NOT NULL
ALTER TABLE USER ADD COLUMN debt INTEGER DEFAULT 0 NOT NULL
++currentVersion
}INSERT OR REPLACE INTO meta (key,value) VALUES (version, currentVersion)INSERT OR REPLACE INTO meta (key,value) VALUES (last_compatible_version, currentVersion)
c. V3 版本發現出生日期與年齡兩個字段有重復,冗余的數據會帶來數據庫體積的增加.希望 V3 數據庫能夠只保留出生日期字段.我們依然從 meta 讀取數據庫版本號信息.不過這次需要注意的是直到 SQLite 3.9.10 版本并沒有刪掉一列的操作.不過這并不影響新版本創建的 TABLE 會去掉這一列,而老版本的DB也可以和新的 SQL 語句一起配合工作不會引發異常.代碼如下
SELECT value FROM meta WHERE key=versionSELECT value FROM meta WHERE key=last_compatible_versionCREATE TABLE IF NOT EXISTS USER (
localid INTEGER PRIMARY KEY,
firstname LONGVARCHAR DEFAULT '' NOT NULL,
lastname LONGVARCHAR DEFAULT '' NOT NULL,
birthdate LONGVARCHAR DEFAULT '' NOT NULL,
credit INTEGER DEFAULT 0 NOT NULL,
deposit INTEGER DEFAULT 0 NOT NULL,
debt INTEGER DEFAULT 0 NOT NULL)INSERT INTO USER (localid, firstname , lastname , birthdate, credit, deposit) VALUES (?, ?, ?, ?, ?, ?, ?, ?)SELECT localid, firstname, lastname, birthdate, credit, deposit, debt FROM USERif (2 == currentVersion) {
// do Nothing
++currentVersion
}INSERT OR REPLACE INTO meta (key,value) VALUES (version, currentVersion)INSERT OR REPLACE INTO meta (key,value) VALUES (last_compatible_version, 2)
注意 last_compatible_version 這里可以填2也可以填3,主要根據業務邏輯合理選擇
d. 除了數據庫結構發生變化時可以用上述的辦法升級.當發現老版本的邏輯引發了數據錯誤,也可以用類似的辦法重新計算正確結果,刷新數據庫.
二、如何寫出高效的 SQL 語句
這個部分將以 App 開發中經常面對的場景作為樣例進行對比分析.
1. 分類建索引(covering index & explain query)
或許很多開發都知道,當用某列或某些列作為查詢條件時,給這些列增加索引是能大大提升查詢速度的.
但真的如此的簡單嗎?
要回答這個問題,我們需要借助 SQLite 提供的 explain query 工具.
顧名思義,它是用來向開發人員解釋在數據庫內部一條查詢語句是如何進行的.在 SQLite 數據庫內部,一條查詢語句可能的執行方式是多種多樣的.它有可能會掃描整張數據表,也可能會掃描主鍵子表、索引子表,或者是這些方式的組合.具體的關于 SQLite 查詢的方式可以參看官方文檔 Query Planning
https://www.sqlite.org/queryplanner.html#searching
簡單的說,SQLite 對主鍵會依照平衡多叉樹理論對其建樹,使其搜索速度降低到 Log(N).
針對某列建立索引,就是將這列以及主鍵所有數據取出.以索引列為主鍵依照升序,原表主鍵為第二列,重新創建一張新的表.需要特別注意的是,針對多列建立索引的內部實現方案是,索引第一列作為主鍵依照升序,第一列排序完畢后索引第二列依照升序,以此類推,最后以原表主鍵作為最后一列.這樣就能保證每一行的數據都不完全相同,這種多列建索引的方式也叫 COVERING INDEX.所以對多列進行索引,只有第一列的搜索速度理論上能到 Log(N).
更重要的是,SQLite 這種建索引的方式確實可以帶來搜索性能的提升,但對于數據庫初始化的性能有著非常大的負面影響.這里先點到為止,下文會專門論述如何進行優化.這里以 SQLite 官方的一個例子來說明,在邏輯上 SQLite 是如何建立索引的.
實際上 SQLite 建立索引的方式并不是下列圖看起來的聚集索引,而是采用了非聚集索引.因為非聚集索引的性能并不比聚集索引低,但空間開銷卻會小很多.SQLite 官方圖片只是示意,請一定注意
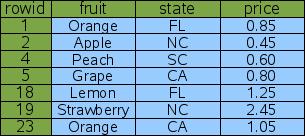
一列行號外加三列數據 fruit state price
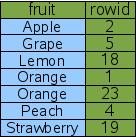
當我們用 CREATE INDEX Idx1 ON fruitsforsale(fruit) 為 fruit 列創建索引后,SQLite 在內部會創建一張新的索引表,并以 fruit 為主鍵.如上圖所示
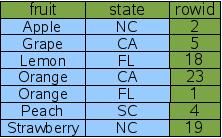
而當我們繼續用 CREATE INDEX Idx3 ON FruitsForSale(fruit, state) 創建了 COVERING IDNEX 時,SQLite 在內部并不會為所有列單獨創建索引表.而是以第一列作為主鍵,其他列升序,行號最后來創建一張表.如上圖所示
我們接下來要做的就是利用 explain query 來分析不同的索引方式對于查詢方式的影響,以及性能對比.
sqlite> EXPLAIN QUERY PLAN SELECT a, b FROM t1 WHERE a=1;
SCAN TABLE t1
不加索引的時候,查詢將會掃描整個數據表
sqlite> CREATE INDEX i1 ON t1(a);
sqlite> EXPLAIN QUERY PLAN SELECT a, b FROM t1 WHERE a=1;
SEARCH TABLE t1 USING INDEX i1
針對 WHERE CLAUSE 中的列加了索引以后的情況.SQLite 在進行搜索的時候會先根據索引表i1找到對應的行,再根據 rowid 去原表中獲取 b 列對應的數據.可能有些工程師已經發現了,這里可以優化啊,沒必要找到一行數據后還要去原表找一次.剛才不是說了嘛,對多列建索引的時候,是把這些列的數據都放入一個新的表.那我們試試看.
sqlite> CREATE INDEX i2 ON t1(a, b);
sqlite> EXPLAIN QUERY PLAN SELECT a, b FROM t1 WHERE a=1;
SEARCH TABLE t1 USING COVERING INDEX i2 (a=?)
果然,同樣的搜索語句,不同的建索引的方式,SQLite 的查詢方式也是不同的.這次 SQLite 選擇了索引 i2 而非索引 i1,因為 a、b 列數據都在同一張表中,減少了一次根據行號去原表查詢數據的操作.
看到這里不知道大家有沒有產生這樣的一個疑問,如果我們用 COVERING INDEX i2 的非第一列去搜索是不是并沒有索引的效果?
sqlite> EXPLAIN QUERY PLAN SELECT * FROM t1 WHERE b=2;
SCAN TABLE t1
WTF,果然,看起來我們為 b 列創建了索引 i2,但用 EXPLAIN QUERY PLAN 一分析發現 SQLite 內部依然是掃描整張數據表.這點也和上面分析的對 COVERING INDEX 建索引表的理論一致,不過情況依然沒這么簡單,我們看看下面三個搜索
// ANDsqlite> EXPLAIN QUERY PLAN SELECT * FROM t1 WHERE a=1 AND b=2SEARCH TABLE t1 USING INDEX i2 (a=? AND b=?)// ORsqlite> EXPLAIN QUERY PLAN SELECT * FROM t1 WHERE a=1 OR b=2SCAN TABLE t1// b index ORsqlite> CREATE INDEX i3 ON t1(b);
sqlite> EXPLAIN QUERY PLAN SELECT * FROM t1 WHERE a=1 OR b=2SEARCH TABLE t1 USING COVERING INDEX i2 (a=?)
SEARCH TABLE t1 USING INDEX i3 (b=?)
WTF,搜索的時候用 AND 和 OR 的效果是不一樣的.其實多想想 COVERING INDEX 的實現原理也就想通了.對于沒有建索引的列進行搜索那不就是掃描整張數據表.所以如果 App 對于兩列或以上有搜索需求時,就需要了解一個概念 “前導列” .所謂前導列,就是在創建 COVERING INDEX 語句的第一列或者連續的多列.比如通過:CREATE INDEX covering_idx ON table1(a, b, c)創建索引,那么 a, ab, abc 都是前導列,而 bc,b,c 這樣的就不是.在 WHERE CLAUSE 中,前導列必須使用等于或者 in 操作,最右邊的列可以使用不等式,這樣索引才可以完全生效.如果確實要用到等于類的操作,需要像上面最后一個例子一樣為右邊的、不等于類操作的列單獨建索引.
很多時候,我們對于搜索結果有排序的要求.如果對于排序列沒有建索引,可以想象 SQLite 內部會對結果進行一次排序.實際上如果對沒有建索引,SQLite 會建一棵臨時 B Tree 來進行排序.
// NO index on csqlite> EXPLAIN QUERY PLAN SELECT c, d FROM t2 ORDER BY c
SCAN TABLE t2
USE TEMP B-TREE FOR ORDER BY// YES index on csqlite> CREATE INDEX i4 ON t2(c);
sqlite> EXPLAIN QUERY PLAN SELECT c, d FROM t2 ORDER BY c
SCAN TABLE t2 USING INDEX i4
所以我們建索引的時候別忘了對 ORDER BY 的列進行索引
講了這么多關于 SQLite 建索引,其實也不過官方文檔的萬一.但是了解了 SQLite 建索引的理論和實際方案,掌握了通過 EXPLAIN QUERY PLAN 去分析自己的每一條 WHERE CLAUSE和ORDER BY.我們就可以分析出性能到底還有沒有可以優化的空間.盡量減少掃描數據表的次數、盡量掃描索引表而非原始表,做好與數據庫體積的平衡.讓好的索引加快你程序的運行.
2. 先建原始數據表,再創建索引 - insert first then index
是的,當我第一眼看見這個結論時,我甚至覺得這是搞笑的.當我去翻閱 SQLite 官方文檔時,并沒有對此相關的說明文檔.看著 StackOverflow 上面華麗麗的 insert first then index VS insert and index together 的對比數據,當我真的將建索引挪到了數據初始化插入后,奇跡就這樣發生了.XCode Instrument 統計的十萬條數據的插入CPU耗時,降低了20%(StackOverflow 那篇介紹文章做的對比測試下降還要更多達30%).
究其原因,索引表在 SQLite 內部是以 B-Tree 的形式進行組織的,一個樹節點一般對應一個 page.我們可以看到數據庫要寫入、讀取、查詢索引表其實都需要用到公共的一個操作是搜索找到對應的樹節點.從外存讀取索引表的一個節點到內存,再在內存判斷這個節點是否有對應的 key(或者判斷節點是否需要合并或分裂).而統計研究表明,外存中獲取下一個節點的耗時比內存中各項操作的耗時多好幾個數量級.也就是說,對索引表的各項操作,增刪查改的耗時取決于外存獲取節點的時間(SQLite 用 B-Tree 而非 STL 中采用的 RB-Tree 或平衡二叉樹,正是為了盡可能降低樹的高度,減少外存讀取次數).一邊插入原始表的數據,一邊插入索引表數據,有可能造成索引表節點被頻繁換到外存又從外存讀取.而同一時間只進行建索引的操作,OS 緩存節點的量將增加,命中率提高以后速度自然得到了一定的提升.
SQLite 的索引采用了 B-Tree,樹上的一個 Node 一般占用一個 page_size.
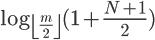
B-Tree 的搜索節點復雜度如上.我們可以看到公式中的 m 就是 B-Tree 的階數也就是節點中最大可存放關鍵字數+1.也就是說,m 是和 page_size 成正比和復雜度成反比和樹的高度成反比和讀取外存次數成反比和耗時成反比.所以 page_size 越大確實可以減少 SQLite 含有查詢類的操作.但無限制的增加 page_size 會使得節點內數據過多,節點內數據查詢退化成線性二分查詢,復雜度反而有些許上升.
* 所以在這里還是想強調一下,page_size 的選擇沒有普適標準,一定要根據性能工具的實際分析結果來確定 *
3. SELECT then INSERT VS INSERT OR REPLACE INTO
有過 SQLite 開發經驗的工程師都知道,INSERT 插入數據時如果主鍵已經存在是會引發異常的.而這時往往邏輯會要求用新的數據代替數據庫已存在的老數據.曾經老版本的 SQLite 只能通過先 SELECT 查詢插入數據主鍵對應的行是否存在,不存在才能 INSERT,否則只能調用 UPDATE.而3.x版本起,SQLite 引入了 INSERT OR REPLACE INTO,用一行 SQL 語句就把原來的三行 SQL 封裝替代了.
不過需要注意的是,SQLite 在實現 INSERT OR REPLACE INTO 時,實現的方案也是先查詢主鍵對應行是否存在,如果存在則刪除這一行,最后插入這行的數據.從其實現過程來看,當數據存在時原來只需要刷新這一行,現在則是刪掉老的插入新的,理論速度上會變慢.這種寫法僅僅是對數據庫封裝開發提供了便利,對性能還是有些許影響的.不過對于數據量比較少不足1000行的情況,用這種辦法對性能的損耗還是細微的,且這樣寫確實方便了很多.但對于更多的數據,插入的時候還是推薦雖然寫起來很麻煩,但是性能更好的,先 SELECT 再選擇 INSERT OR UPDATE 的辦法.
4. Full Text Search(FTS)
INTEGER 類的數據能夠很方便的建索引,但對于 VARCHAR 類的數據,如果不建索引則只能使用 LIKE 去進行字符串匹配.如果 App 對于字符串搜索有要求,那么基本上 LIKE 是滿足不了要求的.
FTS 是 SQLite 為加快字符串搜索而創建的虛擬表.FTS 不僅能通過分詞大大加快英文類字符串的搜索,對于中文字符串 FTS 配合 ICU 也能對中文等其他語言進行分詞、分字處理,加快這些語言的搜索速度.下面這個是 SQLite 官方文檔對兩者搜索速度的一個對比.
// For example, if each of the 517430 documents in the "Enron E-Mail Dataset" is inserted into both an FTS table and an ordinary SQLite table created using the following SQL scriptCREATE VIRTUAL TABLE enrondata1 USING fts3(content TEXT); /* FTS3 table */CREATE TABLE enrondata2(content TEXT); /* Ordinary table */SELECT count(*) FROM enrondata1 WHERE content MATCH 'linux'; /* 0.03 seconds */SELECT count(*) FROM enrondata2 WHERE content LIKE '%linux%'; /* 22.5 seconds */
上面創建 FTS 虛擬表的方式只能對英文搜索起作用,對其他語言的支持是通過 ICU 模塊支持來實現的.所以工程是需要編譯創建 ICU 的靜態庫,編譯 SQLite 時需要指定鏈接ICU庫.
CREATE VIRTUAL TABLE VCONTENT USING fts3(TOKENIZE icu, content LONGVARCHAR DEFAULT '' NOT NULL)INSERT INTO VCONTENT (docid, content) VALUES (?, ?)SELECT docid FROM VCONTENT WHERE content MATCH ? GROUP BY docid HAVING content LIKE ?
其實無論創建數據表的時候是否創建了行號(rowid)列,SQLite 都會為每個數據表創建行號列.想想上面的 fruitsforsale,當數據表沒有任何列建了索引的時候,行號就是數據表的唯一索引.FTS 表略微不同的是,它的行號叫 docid,并且是可以用 SQL 語句拜訪的.我們一般會用字符串在原始表中的行號作為這里的 docid.
如果你仔細看搜索語句你會發現和官方文檔不太一樣的是,對于 MATCH 的結果我們會再用 LIKE 過濾一次.
在回答這個問題前,我們需要知道 SQLite 默認對英文是按單詞(空格為分隔符)進行分詞,對中文則是依照字進行拆分.當中文是按字進行拆分時,SQLite 會對關鍵字也按字進行拆分后進行搜索.這會帶來一個 bug,當關鍵字是疊詞時,比如“天天”,除了可以把正確的如“天天向上”搜索出來,還能把“今天天氣不錯,挺風和日麗的”給搜索出來.就是因為關鍵詞“天天”也被按字拆分了.如果我們把 SQLite 內英文搜索設置成按字母拆分,一樣會產生相同的問題.所以我們需要把結果再 LIKE 一次,因為在一個小范圍內 LIKE 且不用加%通配符,這里的速度也是很快的.
如果希望對英文也按字母拆分,使得輸入關鍵字 “cent”,就能匹配上 “Tencent” 也非常簡單.只需要找到,SQLite 實現的 icuOpen 辦法.
static int icuOpen辦法(
sqlite3_tokenizer *pTokenizer, /* The tokenizer */const char *zInput, /* Input string */int nInput, /* Length of zInput in bytes */sqlite3_tokenizer_cursor **ppCursor /* OUT: Tokenization cursor */){
...//pCsr->pIter = ubrk_open(UBRK_WORD, p->zLocale, pCsr->aChar, iOut, &status); 按單詞分詞// 按字母進行拆分pCsr->pIter = ubrk_open(UBRK_CHARACTER, p->zLocale, pCsr->aChar, iOut, &status);
...
}/** The possible types of text boundaries. @stable ICU 2.0 */typedef enum UBreakIteratorType {/** Character breaks @stable ICU 2.0 */UBRK_CHARACTER = 0,/** Word breaks @stable ICU 2.0 */UBRK_WORD = 1,/** Line breaks @stable ICU 2.0 */UBRK_LINE = 2,/** Sentence breaks @stable ICU 2.0 */UBRK_SENTENCE = 3,
UBRK_TITLE = 4,
UBRK_COUNT = 5} UBreakIteratorType;
其實只需要改變讀取 ICU 的方式,就能支持英文按字母拆分了.
4. 不固定個數的元素集合不要分表
在設計數據庫時,我們會把一個對象的屬性分成不同的列按行存儲.如果屬性是個數量不定的數組,切忌不要把這個數組屬性放到一個新表里面.上面我們提到過數據操作最耗時的其實是拜訪外存上面的數據.當數據量很大時,多張表的外存拜訪是非常慢的.這里的做法是講數組數據用 JSON 序列化后,已 VARCHAR 或者 BLOB 的形式存成一列,和其他的數據放在同一個數據表當中.
5. 用 protobuf 作為數據庫的輸入輸出參數
先說結論,這樣做是數據庫 Model 跨 iOS、Android 平臺的辦理方案.兩個平臺用同一份 proto 文件分別生成各自的實現文件.需要跨平臺時將數據序列化后,以傳遞內存的方式通過 JNI 接口將數據傳遞給對方平臺.對方平臺有相應的方式進行反序列化.JNI 封裝層的工作也大大降低了.這樣做還有個好處是,后臺返回 protobuf 的結果,網絡只需要拷貝在內存一份數據(實際上如果 UI、DB 是不同的線程,有可能會需要兩份)就能讓數據庫進行使用,減少了不必要的內存開銷.
6. 千萬不要編譯使用 SQLite 多線程實現
標題已經勝過千言萬語了.多線程版的 SQLite 可是對每行操作加鎖的,性能是比較差的,同樣的操作耗時是單線程版本的2倍.
三、一些可能有用的輔助模塊
1. 利用 Lambda 表達式簡化從 UI 線程異步調用數據庫接口
好的 App 架構,一定會為數據庫單獨安排一個線程.在多線程環境下,UI 線程發起了數據庫接口哀求后,一定要保證接口是異步返回數據才能保證整個UI操作的流暢性.但是異步接口開發最大的麻煩在于調用在A處,還要實現一個 B 方法來處理異步返回的結果.這里推薦使用 C++11的 lambda 表達式加模板函數 base::Bind 來實現像 JavaScript 語言一樣,能夠將異步回調方法作為輸入參數傳遞給執行方,待執行完成操作后進行異步回調.用異步化接口編程,大大降低開發難度和實現量,并帶來了流暢的界面體驗.
C++要實現將回調函數作為輸入參數傳遞給函數執行者,并在執行者完成預定邏輯獲得返回結果時調用回調函數傳遞回結果,有兩個難點需要克服.
如何將函數變成一個局部變量(C++11 lambda 表達式)
如何將一個函數匿名化(C++11 auto decltype 聯合推導 lambda 表達式的類型)
// base::Bind是chromium開源庫中的基礎庫base project中的一個模板辦法.// base::Bind的邏輯是將一個辦法包裝在一個模板類中,并重載operator()辦法來實現通過調用模板類()來調用其包裝的函數// base::Bind的功效非常接近于boost::function,這里用boost::function來進行替換亦可namespace base { template <typename Functor> auto BindLambda(const Functor& functor) -> decltype(base::Bind(&Functor::operator(), base::Owned(&functor))) { auto functor_on_heap = new Functor(functor); return base::Bind(&Functor::operator(), base::Owned(functor_on_heap));
}
}
// 像JS一樣把Callback函數作為輸入參數進行了傳遞,這樣不需要多加一個函數就能把vector中能夠整除2的數據篩查出來std::vector<int> result = filter(source, base::BindLambda([=](int dividend) -> bool{ return dividend % 2 == 0;
}));
2. 加密數據庫
有些時候,出于某種考慮,我們需要加密數據庫.SQLite 數據庫加密對性能的損耗依照官方文檔的評測大約在3%的 CPU 時間.實現加密一種方案是購買 SQLite 的加密版本,大約是3000刀.還有一種就是自己實現數據庫的加密模塊.網上有很多介紹如何實現 SQLite 免費版中空實現的加密方法.
最后,希望本文能對大家有所贊助.
《關于移動客戶端中使用 SQLite看這篇就夠了》是否對您有啟發,歡迎查看更多與《關于移動客戶端中使用 SQLite看這篇就夠了》相關教程,學精學透。維易PHP學院為您提供精彩教程。
