NoSQL數(shù)據(jù)庫類型
《NoSQL數(shù)據(jù)庫類型》要點:
本文介紹了NoSQL數(shù)據(jù)庫類型,希望對您有用。如果有疑問,可以聯(lián)系我們。
本文摘自 Introducing Data Science,我們將向您介紹四大NoSQL數(shù)據(jù)庫類型.
有四大NoSQL類型:鍵值存儲(key-value store),文件存儲(document store),列導向的數(shù)據(jù)庫(Column-Oriented Database)和圖形數(shù)據(jù)庫(graph database).每種類型都辦理了傳統(tǒng)關系數(shù)據(jù)庫無法辦理的問題.實際的實現(xiàn)往往是這些組合的組合.例如,結合NoSQL類型,Orientdb是一個多模式的數(shù)據(jù)庫.Orientdb是圖形數(shù)據(jù)庫,每個節(jié)點都是一個文檔.
在進入不同的NoSQL數(shù)據(jù)庫之前,讓我們看看與關系數(shù)據(jù)庫之間的比較.傳統(tǒng)關系數(shù)據(jù)庫正在努力的走向規(guī)范化:確保每一個數(shù)據(jù)都只存儲一次.正規(guī)化標志著他們的結構設置.舉個例子來說,如果你想把一個人和他的喜好存儲為數(shù)據(jù),那么你就可以建兩個表:一個表存儲為人,一個表存儲他們的喜好.如圖1所示,一個附加的表是必要的,因為他們存在著很多關系:一個人可以有多個喜好,然而一個喜好也可以有很多人喜歡.
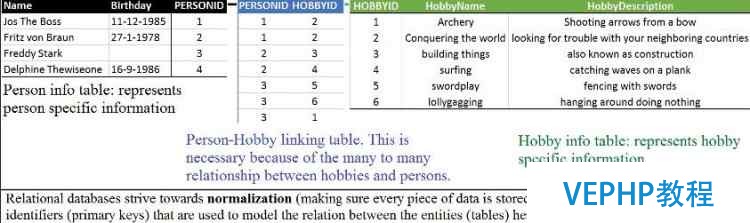
圖1
一個全面的關系數(shù)據(jù)庫可以由許多實體和聯(lián)系表.現(xiàn)在讓我們看看NoSQL不同的類型的數(shù)據(jù)庫之間的比擬.
Column databases store列存儲數(shù)據(jù)庫
行數(shù)據(jù)庫實際上就是傳統(tǒng)的關系數(shù)據(jù)庫,每一行有一行id,并在一個表中存儲的行中的每個字段.假設,關于喜好,沒有額外的表來存儲并且你只有一個表來描述人,如圖2所示.注意,在這種情況下,你有輕微的反規(guī)范化,因為喜好是可以重復的.如果喜好這個信息是一個額外的信息,但在你使用時并不是必不可少的,添加它作為一個列表內(nèi)的喜好列是可以接受的方法.但是如果這些信息對一個單獨的表來說是不夠的,它應該被存儲在所有的?

圖2
每次你在行存據(jù)庫中尋找某個數(shù)據(jù),進行每行掃描,不管你必要哪列.假設你只必要生日在9月的列表.數(shù)據(jù)庫將在表中從上到下和從左到右掃描所有數(shù)據(jù),如圖3所示,最終返回生日列表.

圖3
索引數(shù)據(jù)在某些列可以顯著提高查詢速度,但索引每一列帶來額外的開銷和數(shù)據(jù)庫仍然是掃描所有列.
Column databases store分別存儲每一列,允許更快的掃描時,只涉及一小部分列.見圖4.
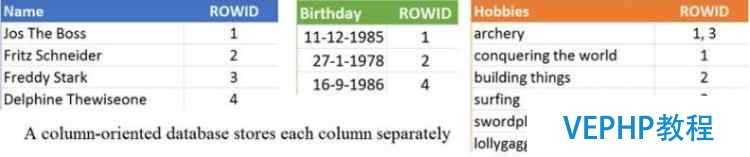
圖4
這個布局看起來很像一個以行為導向的數(shù)據(jù)庫,每一列都有一個索引.一個數(shù)據(jù)庫索引是一種數(shù)據(jù)結構,允許在存儲空間上快速查找數(shù)據(jù)和額外的寫(索引更新).索引映射到數(shù)據(jù)的行數(shù),而一個列數(shù)據(jù)庫將數(shù)據(jù)映射到行數(shù),這樣計算變得更快,所以很容易看到有多少人喜歡射箭.例如,單獨存儲的列也可以優(yōu)化壓縮,因為只有一個數(shù)據(jù)類型的表.
那么,何時該使用Row-Oriented Database和Column-Oriented Database呢?在Column-Oriented Database中,很容易添加另一個列,因為不受它的影響.但添加整個完整記錄必要調(diào)整所有的表.這使得Row-Oriented Database更好于Column-Oriented Database在聯(lián)機事務處理(OLTP)方面,因為他可以不斷地添加或更改記錄.
Column-Oriented Database在執(zhí)行分析和申報時的表現(xiàn): 求和值和計算條目.Row-Oriented Database通常是實際交易的操作數(shù)據(jù)庫(如銷售).夜間批處理作業(yè)將用于數(shù)據(jù)庫更新,支持客戶快速查找和聚合使用MapReduce算法申報.例如column-family stores are Apache HBase、Facebook的Cassandra、Hypertable和the grandfather of wide-column stores、谷歌的 BigTable.
KEY-VALUE STORES 鍵值存儲
鍵值存儲是最復雜的NoSQL數(shù)據(jù)庫.顧名思義,鍵值對的集合,如圖5所示,這種簡單性使得他們成為最可伸縮的NoSQL數(shù)據(jù)庫類型,能夠存儲大量的數(shù)據(jù).
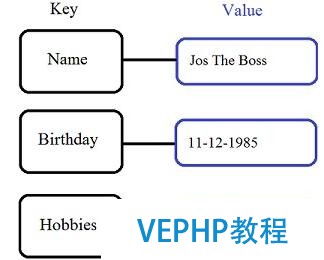
圖5
鍵值存儲的值可以是任何東西:一個字符串,一個數(shù)字,而且也是一個新的鍵值對封裝在一個對象.如圖6顯示了一個稍微復雜鍵值結構.關鍵值存儲的例子有Redis、Voldemort、Riak和Amazon’s Dynamo.
{"internal data":[{"entities":[ {"customer":[ {"id:1,"name":"Freddy"}, {"id:2,"name":"Fritz"} }], {"legal entities":[ {"id":1,"company":"Maiton"} ]}]},{"Products":[ {"furniture":[ {"id" :1,"name":"Octopus Table","stock":1} ]}]}]} 圖6
DOCUMENT STORES 文檔存儲
文檔存儲是鍵值存儲的復雜性的一個步驟:一個文檔存儲庫確實假定一個特定的文檔結構,可以用一個模式來指定.文檔存儲出現(xiàn)最自然的NoSQL數(shù)據(jù)庫類型中,因為它們用于存儲日常文檔,并且他們允許復雜的查詢和計算,這往往已經(jīng)成為聚合形式的數(shù)據(jù).在關系數(shù)據(jù)庫中存儲的方式是從一個正常化的角度來看,所有的一切都應該存儲一次,并通過外鍵連接.文件存儲的關心小的正常化,只要數(shù)據(jù)是在一個結構是有意義的.關系數(shù)據(jù)模型并不總是適合某些業(yè)務案例.
報紙或雜志,例如,包含文章.要把這些存儲在關系數(shù)據(jù)庫中,首先要把它們切碎:這篇文章正文在一個表中,作者和作者所有的信息,以及在一個網(wǎng)站上頒發(fā)的文章的評論.如圖7所示,報紙上一篇文章也可以存儲為一個單一的實體,這降低了對于習慣看到文章內(nèi)容所消耗的時間.文檔存儲以MongoDB和CouchDB為例子.

圖7
GRAPH DATABASES 圖數(shù)據(jù)庫
最后一個大的NoSQL數(shù)據(jù)庫類型是最復雜的一個,為了高效地存儲實體之間的關系.數(shù)據(jù)是高度互聯(lián)的,如社會網(wǎng)絡,科學論文引用,或資本資產(chǎn)集群,圖形數(shù)據(jù)庫的答案.圖或網(wǎng)絡數(shù)據(jù)主要有2個組成部分:
節(jié)點:實體自己.在社交網(wǎng)絡中,這可能是人.
邊:實體間的關系.這種關系用一條線來表示,并且有它本身的特性.邊可以有一個方向,例如,如果箭頭表示誰是誰的老板.
圖可以變的非常復雜來給定足夠的關系和實體類型.圖8已經(jīng)表明了復雜性,只有有限數(shù)量的實體.圖數(shù)據(jù)庫像Neo4j還聲稱保持ACID,而文檔存儲和鍵值存儲保持BASE.
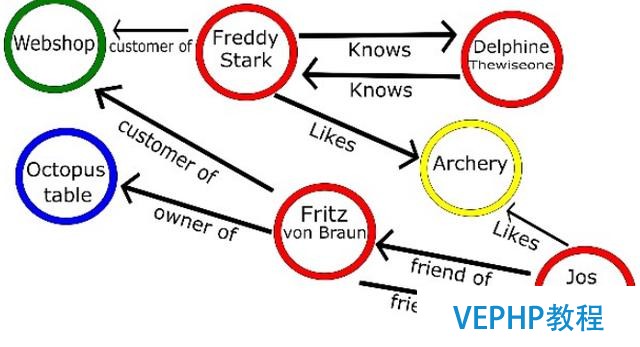
圖8
這個可能性是無限的,因為世界正變得越來越互聯(lián),Graph databases可能會贏過其他類型的數(shù)據(jù)庫,包含如今仍然占主導地位的關系數(shù)據(jù)庫.排名最受歡迎的數(shù)據(jù)庫和他們是如何進展可以點擊:最新數(shù)據(jù)庫排名
翻譯:CSDN編纂孫思,關注數(shù)據(jù)庫,歡迎加入CSDN 數(shù)據(jù)庫討論QQ群:123038767.尋求報道或投稿,請聯(lián)系sunsi@csdn.net.2016年3月18日-19日,由CSDN重磅打造的數(shù)據(jù)庫核心技術與實戰(zhàn)應用峰會、互聯(lián)網(wǎng)應用架構實戰(zhàn)峰會將在上海舉行.這兩場峰會將邀請業(yè)內(nèi)頂尖的架構師和技術專家,共同探討高可用/高并發(fā)系統(tǒng)架構設計、新技術應用、移動應用架構、微服務、智能硬件架構、云數(shù)據(jù)庫實戰(zhàn)、新一代數(shù)據(jù)庫平臺、產(chǎn)品選型、性能調(diào)優(yōu)、大數(shù)據(jù)應用實戰(zhàn)等領域的熱點話題與技術.(報名參會)
維易PHP培訓學院每天發(fā)布《NoSQL數(shù)據(jù)庫類型》等實戰(zhàn)技能,PHP、MYSQL、LINUX、APP、JS,CSS全面培養(yǎng)人才。
轉載請注明本頁網(wǎng)址:
http://www.fzlkiss.com/jiaocheng/9332.html
同類教程排行
- 大數(shù)據(jù)學習——你知道Apache Cas
- 一張圖理清NoSQL、MPP和Hadoo
- 新思潮:NoSQL與DPDK、RDMA等
- CockroachDB 1.1發(fā)布 平均
- NoSQL的基本概念和分類比較 Redi
- 細數(shù)5款主流NoSQL數(shù)據(jù)庫到底哪家強?
- mongodb nosql 如何實現(xiàn)分頁
- 解析SQL與NoSQL的融合架構產(chǎn)品GB
- mongodb NOSQL 各種查詢條件
- 科普|大數(shù)據(jù)技術原理與應用(第五章 No
- 騰訊十多個人管理一萬多臺NoSQL存儲服
- NoSQL數(shù)據(jù)庫的分布式算法
- 如何學習及選擇大數(shù)據(jù)非關系型數(shù)據(jù)庫NoS
- SQL和NOSQL有區(qū)別嗎?
- 2017年度全球“大數(shù)據(jù)企業(yè)50強”
